

План аварийного восстановления – это первоочередная мера, которую организация должна иметь перед тем, как на нее обрушится необычное событие. В ИТ-индустрии он начинается с создания официального документа, содержащего планы, действия и процедуры по ликвидации последствий катастрофы и ее последствий. Катастрофа – это событие, которое происходит внезапно, без предварительного уведомления, и может быть разных типов. И когда она наступает, люди и организации сталкиваются с трудностями разного рода, включая финансовые вопросы и проблемы пользователей. Если атака произошла, вы должны быть готовы минимизировать ее последствия и быстрее восстановить свою деятельность.
Именно здесь подготовка практического плана аварийного восстановления поможет вам удержать или предотвратить катастрофу. Вы также сможете уменьшить ее последствия с точки зрения удобства работы пользователей, затрат и времени простоя. Кроме того, вы должны держать в готовности свои планы, людей, стратегии, оборудование и системы, чтобы вернуть все в рабочее состояние. Но для этого вы должны глубоко понимать, что такое аварийное восстановление. В этой статье я подробно расскажу об этом, а также о ключевых терминах аварийного восстановления, чтобы вы могли дать отважный отпор и стать сильнее в таких неблагоприятных условиях. Давайте начнем!
Что такое катастрофа?

Катастрофа – это непредвиденное событие, которое может произойти где угодно, в том числе и в ИТ-индустрии. Оно происходит либо естественным путем, либо по вине людей и может помешать работе компании и нарушить структуру инфраструктуры. В результате страдает организация, ее клиенты, поставщики, сотрудники и партнеры. Это оказывает давление на организацию с точки зрения финансов, репутации в отрасли, доверия клиентов и периметра безопасности. Следовательно, вы должны быть заранее готовы к преодолению такого сценария.
Для этого необходимо мгновенно восстановить все операции и данные. Проще говоря, вы должны подготовить свою организацию к тому, чтобы восстановить все в кратчайший промежуток времени для ваших клиентов. Катастрофы бывают разных типов, например, кибератаки, саботаж, террористические атаки, ransomware или физические угрозы, ураганы, землетрясения, пожары, наводнения, промышленные аварии, отключения электроэнергии и многое другое.
Что вы подразумеваете под восстановлением после катастроф?
Восстановление после катастрофы – это процесс восстановления нормальной работы после бедствия. Он включает в себя возобновление доступа к аппаратным средствам, программному обеспечению, оборудованию, возможностям подключения, сетям, электропитанию и данным. Вы должны установить правила и процедуры в документированном процессе подготовки организации перед катастрофой. Однако, если объекты вашей организации разрушены, вы должны продлить некоторые мероприятия, работая над коммуникациями, транспортом, поиском поставщиков, рабочими местами и т.д.
Почему важен план восстановления после стихийных бедствий?
Разработка идеального плана восстановления после катастрофы, как природной, так и техногенной, необходима для каждой ИТ-индустрии. Убедитесь, что у вас есть нужные сотрудники и инструменты в нужном месте для беспрепятственного выполнения плана. Давайте подробнее рассмотрим, почему восстановление после катастрофы имеет решающее значение.
Ограничение ущерба
Катастрофа непредсказуема. Никто не знает, когда она придет и когда уйдет. Но вы готовитесь заранее, чтобы контролировать ущерб, нанесенный вашей инфраструктуре. Например, в районах, подверженных наводнениям, вы можете разместить важные документы и виды оборудования на верхнем этаже, чтобы избежать ущерба. Аналогично, создайте резервные копии важных данных до того, как кибер-атаки смогут нарушить данные или украсть их.
Услуги по восстановлению
Если вы подготовите надежный план восстановления после катастрофы, то восстановление всех сервисов до их нормального состояния будет быстрым и легким. Это означает, что за короткий промежуток времени вы сможете восстановить почти все основные активы и услуги.
Минимизация перерывов
Вы не можете знать, что произойдет завтра или на следующем этапе операции. Но, имея идеальный план восстановления, вам не придется сильно беспокоиться о последствиях. Ваша инфраструктура сможет продолжать работу с минимальными перерывами.
Обучение и подготовка

ИТ-инфраструктура состоит из множества сотрудников, работающих под одной крышей. Все они должны знать о восстановлении, чтобы в случае возникновения чрезвычайной ситуации действовать незамедлительно в соответствии с требованиями и ожиданиями. Правильная подготовка также снизит уровень стресса у всех, кто связан с вашей организацией. Кроме того, вы можете обучить своих сотрудников необходимым действиям в случае возникновения непредвиденных обстоятельств.
Терминология аварийного восстановления
Давайте начнем с терминологии, чтобы лучше понять, что такое аварийное восстановление.
RTO
Цель времени восстановления (RTO) – это количество времени, которое организация устанавливает в соответствии с характером бизнеса, чтобы перенести катастрофу без ущерба для финансового роста. При определении RTO компания должна проверить время простоя, которое может повлиять на вашу организацию различными способами. Он используется для изучения жизнеспособных стратегий продолжения бизнес-операций даже после катастрофы. Когда клиенты сталкиваются с какими-либо нарушениями в работе приложения, они спрашивают, сколько времени потребуется приложению, чтобы вернуться к работе.
Ответ – RTO для каждой организации. Пример: Предположим, вы являетесь компанией, занимающейся онлайн-транзакциями, такой как PayPal или Pioneer, сталкивающейся с непредсказуемыми событиями. В этом случае ваш RTO будет достаточно быстрым для восстановления работы. Другими словами, компания устанавливает RTO на час или два, чтобы избежать последствий в виде финансов или данных.
RPO
Точка восстановления (Recovery Point Objectives, RPO) – это потеря данных, с которой может справиться ИТ-инфраструктура с точки зрения времени и количества информации. Сбивает с толку? Возьмем пример базы данных, которая регистрирует транзакции банка, включая переводы, планирование, платежи и многое другое. Когда происходит катастрофа, база данных восстанавливается в режиме реального времени. В этом случае разница между базой данных на момент катастрофы и восстановлением базы данных после катастрофы равна нулю.
Для некоторых компаний приемлемо, что восстановление всей информации из резервной копии занимает около 24 часов, но иногда это может привести к катастрофе. Очень важно настроить свою инфраструктуру в соответствии с требованиями RPO. Это включает в себя увеличение частоты резервного копирования, добавление резервной базы данных в вашу архитектуру и многое другое.
Обход отказа
Представьте себе ситуацию, когда вы путешествуете на большое расстояние. Вдруг по какой-то неожиданной причине у вас спустило колесо. Вы благодарите запасное колесо, имеющееся в вашем автомобиле, и инструменты для замены поврежденного колеса.
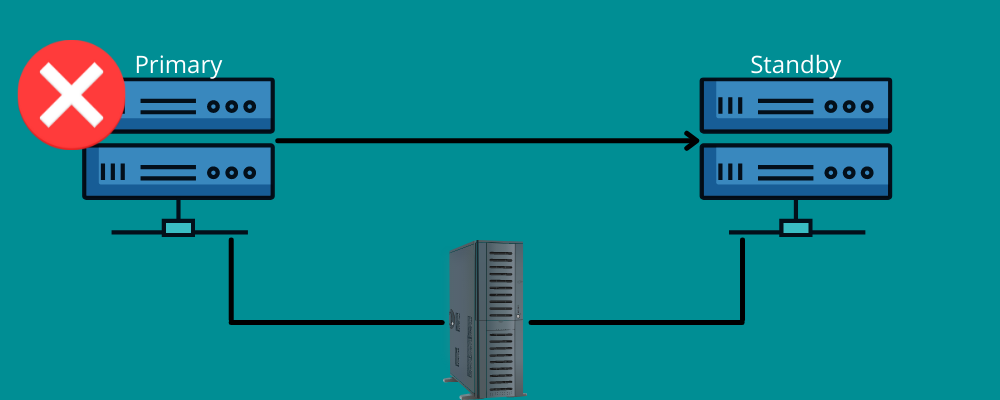
Обход отказа работает аналогичным образом. Это означает, что вам необходимо резервное соединение во время катастрофы. В двух словах, обход отказа означает наличие сетей и систем, которые вы можете использовать во время аварии для переключения информации на систему восстановления. Обход отказа обеспечивает бесперебойную работу всех ваших сервисов даже в случае инфраструктурных или аппаратных сбоев. Таким образом, вы можете предотвратить потерю данных и доходов вашей организации и избежать перебоев в обслуживании конечных пользователей. Вы можете настроить его вручную или позволить ему функционировать автоматически для перемещения данных на резервный сервер.
Отказоустойчивость
Отказоустойчивость ИТ – это простая операция, при которой исходное производство возвращается на прежнее место (в систему) после устранения последствий аварии. Во время атаки компании выполняют операцию failover, в результате которой все рабочие нагрузки переходят на реплику виртуальной машины или резервную систему. Однако нельзя просто пропустить следующий этап возвращения. Когда вы все восстановите и вернетесь в строй, вам необходимо перенести все рабочие нагрузки на их исходные ВМ или системы.
Этот общий процесс возвращения рабочих нагрузок на исходное рабочее место или систему известен как failback. Это означает, что вы возвращаетесь “назад” после атаки. Failback также используется для планового обслуживания предприятия. Верно, что отказ всегда происходит после обхода отказа. Другими словами, обход отказа – это первый шаг, а отказ – второй шаг в восстановлении важных данных. Отказоустойчивость может быть организована между облаком и облаком, локальной сетью и локальной сетью, локальной сетью и облаком, а также в любой комбинации.
DR
Disaster Recovery (DR) – это процесс, в ходе которого у вас есть заранее разработанные планы по восстановлению ваших активов в установленные сроки. DR дает организации возможность быстро реагировать и восстанавливать каждую услугу после неожиданного события. Она также предоставляет официальную документацию, содержащую инструкции по принятию немедленных мер в случае непредвиденных инцидентов.
BCP
План обеспечения непрерывности бизнеса (BCP) – это один из наиболее приемлемых планов восстановления после катастроф, который позволяет ИТ-инфраструктуре разработать стратегии для того, чтобы справиться с нарушениями в работе серверов, мобильных устройств, персональных компьютеров и сетей. BCP несколько отличается от аварийного восстановления, поскольку помогает организации составить планы по восстановлению корпоративного программного обеспечения и производительности для удовлетворения ключевых потребностей бизнеса. Здесь компания создает систему восстановления для преодоления потенциальных угроз, таких как кибер-атаки или стихийные бедствия. Она предназначена для защиты активов и обеспечения быстрого восстановления работы всех служб после удара.
BCM

Управление непрерывностью бизнеса (BCM) – это процесс управления рисками, специально разработанный для защиты от угроз бизнес-процессам. BCM – это следующий шаг BCP, на котором проверяются планы восстановления, чтобы убедиться, что все участники бизнеса мгновенно реагируют на план и восстанавливают все необходимое.
BCM действует как управленческая структура для определения рисков инфраструктуры, когда она сталкивается с внешними и/или внутренними угрозами. Она также обеспечивает эффективное функционирование структуры с помощью регулярного тестирования для повышения предсказуемости, снижения риска и согласования плана с будущими атаками.
BIA
Анализ воздействия на бизнес (BIA) – это процесс анализа выживаемости бизнеса путем выявления важнейших систем, операций и процессов. Он рассказывает о влиянии катастрофы на вашу организацию в связи с перерывами в работе. BIA прогнозирует последствия до того, как атака действительно произойдет, чтобы собрать ключевую информацию, которая поможет создать мощные стратегии восстановления.
Он также определяет затраты, связанные со сбоями, такие как стоимость замены оборудования, потеря денежного потока, прибыли, заработной платы и многое другое. При создании отчета BIA необходимо учитывать важнейшие процессы, задействованные в вашем бизнесе, влияние сбоев на различные области, приемлемую продолжительность, допустимые области, финансовые затраты и многое другое.
Дерево вызовов
Дерево вызовов – это процесс составления списка сотрудников, к которым можно обратиться во время чрезвычайной ситуации. Это процедура, которая имеет древовидную структуру. Например, во время бедствия один человек связывается с небольшой группой сотрудников со срочным сообщением, и эти сотрудники звонят каждой группе отдельно. Таким образом, все сотрудники получат информацию во время угрозы и начнут выполнять свою работу, чтобы вовремя восстановить все функции и процессы. Составить список просто, но его реализация в реальном времени приводит к путанице.
Вы должны проводить регулярные мероприятия по вызову, чтобы подготовить каждого сотрудника к чрезвычайной ситуации, чтобы он оставался начеку. Регулярное тестирование также поможет выявить измененные или отсутствующие номера, которые могут серьезно повлиять на производительность. Дерево вызовов содержит информацию, которая будет использоваться во время чрезвычайной ситуации для передачи инструкций. Это можно сделать и вручную, но в современном цифровом мире люди используют автоматизацию для ускорения процесса и оповещения членов организации.
Командный центр/Центр управления
Это виртуальный или физический объект, специально подготовленный для обеспечения командования или контроля над планами восстановления во время кризиса. Он взаимодействует с командой для управления системами и функциями во время катастрофы. Традиционно инфраструктура зависит от командного центра, который справляется с кризисами без надлежащего подхода.
В настоящее время организации идеально спроектировали свой центр управления, который превращает немедленное реагирование в основную компетенцию. Почувствовав катастрофу, командный центр быстро переходит к этапу восстановления. Более того, он служит точкой отчетности в случае предоставления услуг, прессы, доставки и т.д. Он также объединяет людей разных специальностей во время таких сценариев.
Реагирование на инцидент

Реагирование на инцидент – это тип реагирования на атаку. Это делается с помощью правильных процедур и персонала для эффективного сохранения безопасности сети и данных в нужное время. Если у организации есть план реагирования на инциденты до наступления неожиданного события, она может защитить свои данные от угроз в режиме реального времени. Специалисты по реагированию на инциденты всегда остаются бдительными к проблемам и действуют естественно во время инцидента.
Они принимают определенные меры, чтобы избежать нарушений безопасности, не пропуская ни одного шага во время восстановления после аварии. Вначале необходимо определить критически важные данные и хранить их в облаке или любом удаленном месте для обеспечения безопасности. Учитывайте текущие потребности инфраструктуры и развивающиеся киберугрозы, регулярно обновляя планы реагирования на инциденты.
Резервное копирование
Решения для резервного копирования помогают ИТ-инфраструктуре поддерживать копии данных и надежно хранить их в нужное время. Если вы столкнетесь с повреждением базы данных, случайным удалением всех данных или любой другой проблемой, вы должны быть готовы к резервному копированию, чтобы мгновенно восстановить данные и продолжить работу.

Она включает в себя тиражирование файлов и хранение их в безопасном месте, чтобы после необычного события можно было легко получить доступ ко всем данным. Резервное копирование данных в нескольких местах поможет вам восстановить их даже в случае сбоя на одном из сайтов.
Устойчивость
Способность сообществ, государств, организаций и отдельных людей противостоять или выдерживать бедствие без ущерба для услуг и систем называется устойчивостью к бедствиям. Организация должна быть готова выдержать большой стресс, вызванный опасностями. Убедитесь, что у вас есть возможности минимизировать потери с помощью лучшего планирования, вместо того чтобы ждать, пока кто-то придет и спасет вас.
Это поможет вам справиться с катастрофами и эффективно восстановить вашу ИТ-инфраструктуру. Главная цель здесь – сохранить и восстановить основные функции и структуры в нужное время, когда это необходимо. Чтобы стать организацией, устойчивой к катастрофам, необходимо заранее подготовиться и иметь возможность предвидеть риски, приспосабливаться к изменениям, делиться опытом и учиться, интегрировать различные сектора и управлять уровнем риска.
SLA

Соглашение об уровне обслуживания (SLA) – это план действий в случае аварии, в котором вы сообщаете конечным пользователям о времени, которое может потребоваться для восстановления услуг во время чрезвычайной ситуации. SLA гарантирует клиентам, что их данные находятся в безопасности, не скомпрометированы и не переданы третьим лицам. Это единая точка соприкосновения с проблемами конечных пользователей. Каждая ИТ-инфраструктура дает гарантии SLA своим клиентам. Поэтому убедитесь, что вы заранее общаетесь с конечными пользователями.
SPOF
Единая точка отказа (Single Point of Failure, SPOF) – это часть оборудования, человек, ресурс или приложение, к которому подключено множество других систем или приложений. Если такая часть оборудования или ресурса выходит из строя, то вместе с ней выходят из строя все основные части, подключенные к системе. Таким образом, пострадает весь процесс и бизнес-операция.
Поэтому вы должны иметь стратегию решения такой проблемы, чтобы ваша организация продолжала работать. Самое первое, что вы можете сделать, это определить ту единицу оборудования или системы, которая может повлиять на большее. Затем проведите анализ воздействия на бизнес и получите оценку рисков, чтобы знать, какие сцены могут произойти. Покопайтесь и найдите их до начала мероприятия.
Как только вы перечислите все SPOF, классифицируйте их в соответствии с процессом восстановления. Отнесите каждый из SPOF к трем различным категориям:
- Восстановить легко и напрямую с меньшими затратами времени и бюджета.
- Восстановить будет сложно, но для восстановления можно разработать надежный процесс.
- Ничего нельзя сделать для восстановления после сбоя.
Вы можете действовать соответственно в зависимости от категории.
Восстановление системы
При аппаратном сбое необходимо запустить процесс восстановления, чтобы вернуть конкретную систему или сервер в исходную форму. А чтобы восстановить всю систему, нужно быть готовым к требованиям восстановления, резервным копиям, совместимости прошивки и аппаратной совместимости. Восстановление системы – это процесс, который возвращает машину к ее прежним настройкам или к тому состоянию, в котором она была, когда была новой.
При этом удаляются все вирусные инфекции, вызванные установленным в системе программным обеспечением или приложениями. Этот процесс включает в себя планирование восстановления ИТ-инфраструктуры, которое устанавливает и соблюдает определенные процедуры для обеспечения доступности данных при антропогенных или естественных сбоях.
Восстановление системы
Восстановление системы – это инструмент восстановления, который позволяет вернуть определенные файлы и информацию к их предыдущему состоянию в нужное время. С помощью восстановления системы вы можете восстановить ключи реестра, установленные программы, драйверы, системные файлы и многое другое до их предыдущей версии. Это спасает от многих бедствий.
План тестирования
Это документ, в котором хранится информация о стратегии тестирования, оценках, ресурсах, сроках, целях и графиках. Он работает как план, по которому проводятся тесты для обеспечения безопасности аппаратного и программного обеспечения. Сюда входят различные тесты в соответствии с процедурами и шагами, запланированными для управления последствиями катастрофы. Проводите регулярные тесты, чтобы подготовить себя и свою организацию к тому, чтобы не пропустить ни одного шага в ходе выполнения действий. Таким образом, ИТ-инфраструктура сможет понять недостатки и быть готовой к борьбе.
Заключение
Никто не знает, когда произойдет катастрофа. Поэтому надлежащие меры безопасности и защиты необходимы каждому предприятию. Терминология аварийного восстановления поможет вам понять, как реагировать на атаки и катастрофы. Это также поможет вам подготовиться заранее, чтобы вы могли защитить свою инфраструктуру во время непредвиденных событий. Вы сможете создать эффективную стратегию аварийного восстановления в режиме реального времени, чтобы сэкономить миллионы долларов и сохранить доверие клиентов.







