

Интернет-трафик изменился навсегда. Сегодня почти половина всех посетителей вашего сайта — это не люди, а автоматизированные программы, или боты.1 Значительная и постоянно растущая часть этого трафика является вредоносной, представляя собой настоящую «невидимую армию», которая наносит ущерб вашему бизнесу.3 Эта армия искажает вашу аналитику, перегружает серверы, ворует уникальный контент, крадет данные клиентов и опустошает рекламные бюджеты.4 Последствия варьируются от незначительных неудобств до катастрофических финансовых потерь и репутационного ущерба.
Многие владельцы сайтов полагаются на устаревшие или поверхностные методы защиты, которые современные боты обходят с легкостью. Простой запрет в файле robots.txt или блокировка копирования текста на странице — это не более чем иллюзия безопасности. Настоящая защита требует многоуровневой, продуманной стратегии, которая охватывает все: от фундаментальной настройки сервера до передовых систем поведенческого анализа, способных отличить человека от машины по неуловимым признакам.
Это руководство — исчерпывающее исследование, которое проведет вас через все этапы построения такой защиты. Мы начнем с классификации ботов, чтобы вы точно знали, с кем имеете дело. Затем мы разберем и опровергнем популярные мифы о защите, показав, почему они не работают. Далее мы перейдем к самому мощному арсеналу: детальным, с примерами кода, инструкциям по настройке серверной защиты на NGINX и Apache. Мы погрузимся в мир интеллектуального обнаружения, изучив, как работают CAPTCHA, цифровые отпечатки устройств и поведенческий анализ. Мы также рассмотрим юридические аспекты парсинга, включая знаковые судебные решения, и проанализируем рынок коммерческих сервисов, которые могут взять эту сложную работу на себя. Это единственное руководство по защите от ботов, которое вам когда-либо понадобится.
Часть 1: Невидимое вторжение: Понимание мира ботов и парсеров
Прежде чем строить оборону, необходимо понять врага. Мир автоматизированных программ огромен и разнообразен. Боты — это не единая сущность; они варьируются от жизненно важных инструментов, поддерживающих работу интернета, до изощренных вредоносных программ, созданных для кражи и разрушения. Понимание их целей и методов является первым шагом к созданию эффективной защиты.
Экосистема ботов: Мир «хороших», «плохих» и «уродливых»
Традиционно ботов делят на две категории: полезных и вредоносных. Однако современная реальность сложнее и требует более детальной классификации.

Хорошие боты
Это автоматизированные программы, которые выполняют важные и легитимные функции. Без них интернет, каким мы его знаем, не мог бы существовать. Их следует не блокировать, а, наоборот, всячески приветствовать на сайте.4
- Поисковые краулеры: Боты, такие как Googlebot и YandexBot, сканируют (или «обходят») веб-страницы, чтобы индексировать их содержимое для поисковых систем. Именно благодаря им пользователи могут находить ваш сайт через поиск.7
- Сервисные боты: Это боты, которые обеспечивают работу различных онлайн-сервисов. Например, боты социальных сетей, генерирующие превью ссылок, или боты-ассистенты, интегрирующиеся с платформами для выполнения задач пользователя.7
Плохие боты
Это категория вредоносных программ, созданных с единственной целью — нанести ущерб сайту, его владельцу или пользователям. Их цели варьируются от мелкого хулиганства до крупномасштабных кибератак.
- Парсеры (Скрейперы): Их основная задача — автоматический сбор данных с веб-страниц. Они воруют уникальный контент для размещения на других сайтах, собирают прайс-листы для анализа конкурентов, крадут контактные данные пользователей и любую другую ценную информацию.4
- Спам-боты: Эти боты автоматически заполняют формы обратной связи, оставляют спамные комментарии и регистрируют поддельные аккаунты, засоряя сайт и создавая угрозу фишинга для легитимных пользователей.7
- Боты для подбора учетных данных (Credential Stuffing): Используя базы украденных логинов и паролей, эти боты пытаются получить доступ к аккаунтам пользователей на вашем сайте. Успешная атака ведет к захвату учетных записей.
- Боты для рекламного мошенничества (Click Fraud): Они имитируют клики по рекламным объявлениям, истощая ваш маркетинговый бюджет и искажая статистику рекламных кампаний. Такие сервисы, как clickfraud.ru, специализируются на борьбе именно с этим типом ботов.10
- Сканеры уязвимостей: Вредоносные боты, которые систематически сканируют сайты на наличие известных уязвимостей в программном обеспечении с целью их последующей эксплуатации для взлома.7
- DDoS-боты: Являясь частью ботнетов (сетей зараженных компьютеров), эти боты одновременно отправляют огромное количество запросов на сервер, чтобы перегрузить его и сделать сайт недоступным для пользователей. Это одна из самых разрушительных форм атак.7
«Уродливые» (Серая зона)
С развитием технологий искусственного интеллекта появилась новая категория ботов, которые не являются откровенно вредоносными, но их деятельность может наносить ущерб.
- Боты для обучения ИИ: Крупные технологические компании используют ботов для сбора огромных объемов текстовых и графических данных для обучения своих языковых и генеративных моделей (например, боты OpenAI).3 Эти боты не пытаются взломать сайт, но они массово потребляют ваш контент и серверные ресурсы, не принося взамен никакой пользы, в отличие от поисковых систем. Их деятельность по сути является формой парсинга, но под предлогом «исследований».
Эта новая реальность означает, что простая бинарная логика «хороший/плохой» больше не работает. Владельцы сайтов должны сами определять политику доступа для разных типов автоматизированных систем, а не полагаться на общепринятые стандарты. Современная стратегия защиты — это не просто черный список, а гибкая система управления доступом, способная идентифицировать и обрабатывать этот новый класс ботов.
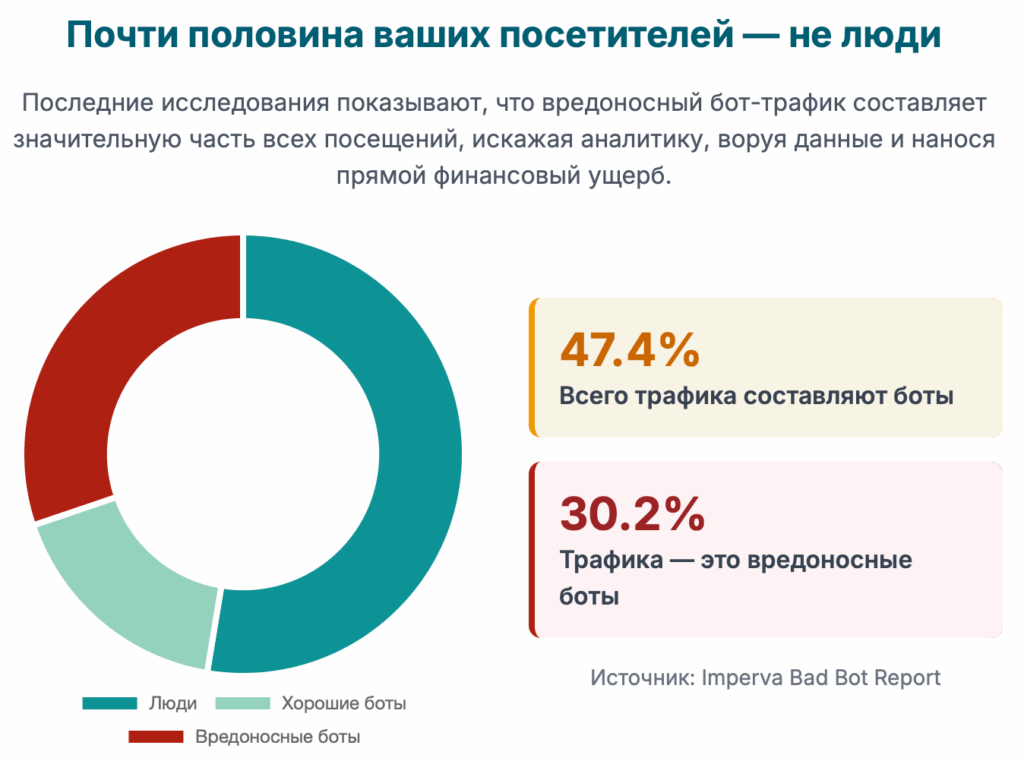
Влияние на бизнес: Как атаки ботов незаметно разрушают ценность
Ущерб от ботов редко бывает очевиден сразу. Он накапливается со временем, подтачивая бизнес изнутри по нескольким ключевым направлениям.
- Финансовые потери: Прямые убытки включают в себя потраченный впустую рекламный бюджет из-за кликфрода, возвратные платежи (чарджбэки) в результате мошеннических транзакций, совершенных с захваченных аккаунтов, и увеличение затрат на хостинг из-за необходимости обрабатывать огромный объем паразитного трафика.4
- Искажение данных и аналитики: Боты создают хаос в системах веб-аналитики. Они генерируют фиктивные посещения, завышают показатель отказов, искажают время на сайте и географию посетителей.4 В результате бизнес принимает стратегические решения, основываясь на ложных данных, что может привести к неверным инвестициям и упущенным возможностям.
- Потеря конкурентного преимущества: Когда парсеры крадут ваши цены, описания товаров, уникальные статьи или клиентскую базу, они передают ваше главное конкурентное преимущество в руки соперников. Это позволяет им мгновенно реагировать на ваши маркетинговые ходы, демпинговать цены и перехватывать клиентов.18
- Снижение производительности и ухудшение пользовательского опыта: Интенсивный трафик от ботов создает дополнительную нагрузку на сервер, что замедляет скорость загрузки страниц для реальных пользователей. Медленный сайт приводит к потере клиентов, снижению конверсии и падению позиций в поисковой выдаче.4
- Репутационный ущерб: Захват аккаунтов пользователей, рассылка спама от имени вашего сайта или утечка данных подрывают доверие клиентов. Восстановить утраченную репутацию чрезвычайно сложно и дорого.5
1.3. Что такое парсинг (веб-скрейпинг)? Взгляд на инструментарий скрейпера
Парсинг — это процесс автоматического извлечения информации с веб-сайтов.9 Вместо того чтобы вручную копировать данные, скрейперы используют программы, которые заходят на страницы, считывают их HTML-код и извлекают нужные элементы (например, цены, названия товаров, тексты статей).
Инструменты для парсинга варьируются от простых до чрезвычайно сложных:
- Простые HTTP-клиенты: Программы вроде cURL или библиотеки для языков программирования (например, requests в Python) могут отправлять прямые запросы к серверу и получать HTML-код страницы. Они быстры, но не могут исполнять JavaScript, что делает их бесполезными на современных динамических сайтах.
- Headless-браузеры (безголовые браузеры): Это настоящие браузеры (такие как Chrome или Firefox), которые работают в фоновом режиме без графического интерфейса и управляются программно. Инструменты вроде Puppeteer и Playwright позволяют скрейперам полностью имитировать действия реального пользователя: они исполняют JavaScript, нажимают на кнопки, заполняют формы и ждут загрузки контента. Это делает их чрезвычайно эффективными для парсинга даже самых защищенных сайтов и создает основу для современной гонки вооружений между скрейперами и системами защиты, которую мы рассмотрим в Части 5.
Часть 2: Фундаментальные уровни: Базовые (и часто неверно понимаемые) методы защиты
Многие владельцы сайтов начинают защиту с самых простых и широко известных методов. К сожалению, именно эти методы либо совершенно неэффективны против злонамеренных ботов, либо, при неправильном использовании, могут даже навредить. Важно понимать их ограничения, чтобы не питать ложных иллюзий о безопасности.
Миф о robots.txt: Джентльменское соглашение
Файл robots.txt — это текстовый файл, размещаемый в корневом каталоге сайта. Его основная и единственная цель — давать рекомендации «хорошим» ботам, в первую очередь поисковым системам, о том, какие страницы или разделы сайта не следует сканировать.19 Это инструмент для управления SEO и краулинговым бюджетом, а не для обеспечения безопасности.
Критическая слабость robots.txt заключается в том, что это добровольный протокол. Вредоносные боты, парсеры и сканеры уязвимостей просто игнорируют его предписания.6 Полагаться на него для защиты — все равно что вешать на дверь табличку «Пожалуйста, не входите» и надеяться, что она остановит грабителя.
Пример стандартного файла robots.txt:
# Запретить всем ботам сканировать административную панель и личные кабинеты
User-agent: *
Disallow: /admin/
Disallow: /private/
# Разрешить боту Яндекса сканировать все, кроме результатов поиска по сайту
User-agent: Yandex
Disallow: /search/
# Указать путь к карте сайта
Sitemap: https://www.example.com/sitemap.xml
Более того, robots.txt может быть контрпродуктивным с точки зрения безопасности. Поскольку этот файл общедоступен, злоумышленники часто просматривают его в первую очередь, чтобы составить карту сайта и найти потенциально интересные директории. Когда они видят строку Disallow: /api/v1/user-data, они воспринимают это не как запрет, а как указатель на ценную цель.22 Таким образом, файл, предназначенный для SEO, превращается в инструмент разведки для атакующих. Настоящая безопасность заключается в защите самих конечных точек (например, с помощью аутентификации), а не в просьбах их не посещать.
Также важно избегать распространенных ошибок при его настройке, таких как блокировка CSS- и JavaScript-файлов, что может помешать поисковым системам правильно отображать и индексировать сайт, нанося вред вашему SEO.27
Клиентские средства устрашения: Иллюзия контроля
Другой популярный, но неэффективный подход — это попытка защитить контент с помощью технологий, работающих в браузере пользователя (на стороне клиента).
- Запрет выделения и копирования текста: Это достигается с помощью CSS-стилей или небольших JavaScript-скриптов.30
Пример CSS:CSS
body {
-webkit-user-select: none; /* Safari */
-ms-user-select: none; /* IE 10+ */
user-select: none; /* Standard syntax */
}
Пример JavaScript для блокировки копирования:JavaScript
document.addEventListener('copy', function(e) {
e.preventDefault();
alert('Копирование контента запрещено!');
}); - Запрет правого клика мыши: Еще один JavaScript-трюк, который должен помешать пользователю открыть контекстное меню и сохранить изображение или просмотреть код страницы.
JavaScript
document.addEventListener(‘contextmenu’, event => event.preventDefault());
Эффективность этих методов равна нулю. Боты и парсеры не взаимодействуют с сайтом так, как человек. Они не «выделяют» текст и не «кликают» мышкой. Они напрямую загружают и анализируют исходный HTML-код страницы, где весь контент представлен в чистом виде. Любые клиентские скрипты и стили для них просто не существуют. Эти меры лишь создают неудобства для легитимных пользователей, не представляя никакой преграды для автоматизированных систем.
Часть 3: Укрепление сервера: Ваша самая мощная линия обороны
Настоящая защита начинается не в браузере пользователя, а на вашем сервере. Именно здесь у вас есть реальный контроль над входящим трафиком и возможность применять мощные, труднопреодолимые барьеры. Серверные методы защиты являются основой любой серьезной стратегии борьбы с ботами.
Сила ограничения скорости (Rate Limiting): Подавление вредоносной активности
Ограничение скорости — это фундаментальная техника, которая заключается в контроле количества запросов, которые один клиент (обычно идентифицируемый по IP-адресу) может сделать за определенный промежуток времени.31 Это чрезвычайно эффективная мера против атак методом перебора (brute-force), агрессивного парсинга и DDoS-атак низкой и средней интенсивности.
Глубокое погружение: Настройка Rate Limiting в NGINX
NGINX является одним из самых популярных веб-серверов и предоставляет мощные и гибкие инструменты для ограничения скорости. В его основе лежит алгоритм «дырявого ведра» (leaky bucket), который можно представить как ведро с отверстием в дне: запросы поступают в ведро с разной скоростью, а обрабатываются (вытекают) с постоянной, заданной скоростью. Если запросов поступает слишком много, ведро переполняется, и новые запросы отбрасываются.31
Настройка выполняется с помощью двух основных директив: limit_req_zone и limit_req.
Пример конфигурации в nginx.conf:
Nginx
# Директива http-уровняhttp {
#... другие настройки...
# Шаг 1: Определение зоны ограничения
# $binary_remote_addr: IP-адрес клиента в бинарном формате (экономит память)
# zone=mylimit:10m: Название зоны 'mylimit' и выделение 10 МБ памяти
# (10 МБ достаточно для хранения состояния ~160,000 IP-адресов)
# rate=10r/s: Установка лимита в 10 запросов в секунду
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=10r/s;
server {
#... другие настройки сервера...
# Шаг 2: Применение ограничения к определенному местоположению (location)
# Например, защищаем страницу входа
location /login {
# Применяем зону 'mylimit'
# burst=20: Разрешаем "всплеск" до 20 запросов сверх лимита.
# Эти запросы не отбрасываются сразу, а ставятся в очередь.
# nodelay: Запросы из очереди обрабатываются без задержки,
# но новые запросы сверх лимита и burst будут сразу отклонены.
# Если убрать nodelay, запросы будут обрабатываться с задержкой,
# чтобы соответствовать заданному rate.
limit_req zone=mylimit burst=20 nodelay;
#... настройки проксирования на бэкенд...
proxy_pass http://my_backend;
}
# Можно применять ограничение ко всему сайту
location / {
# Более мягкое ограничение для всего сайта
# limit_req zone=mylimit burst=5;
#...
}
}
}
Эта конфигурация позволяет очень гибко управлять трафиком. Например, можно установить жесткие лимиты для критически важных URL (страница входа, API), и более мягкие — для всего остального сайта.32
Глубокое погружение: Ограничение пропускной способности и соединений в Apache
Веб-сервер Apache также имеет встроенные механизмы для контроля трафика, хотя их настройка может быть менее интуитивной, чем в NGINX. Основным инструментом является модуль mod_ratelimit.
Пример конфигурации в файле виртуального хоста Apache:
Apache
# Шаг 1: Убедитесь, что модуль включен
# В файле конфигурации модулей (например, /etc/httpd/conf.modules.d/00-base.conf)
# должна быть раскомментирована строка:# LoadModule ratelimit_module modules/mod_ratelimit.so
<IfModule mod_ratelimit.c>
# Применяем ограничение к директории /downloads
<Location /downloads>
# Включаем фильтр ограничения скорости
SetOutputFilter RATE_LIMIT
# Устанавливаем переменную окружения rate-limit
# Значение в килобайтах в секунду
SetEnv rate-limit 200
</Location>
</IfModule>
Эта конфигурация ограничивает скорость скачивания файлов из директории /downloads до 200 КБ/с для каждого клиента.36
Несмотря на свою мощь, базовое ограничение скорости по IP-адресу имеет фундаментальный недостаток в современном мире. Его эффективность напрямую подрывается развитием изощренных методов обхода, в частности, использованием резидентных прокси-сетей. Когда парсер использует такую сеть, он может отправлять каждый новый запрос с нового, уникального IP-адреса, принадлежащего реальному домашнему пользователю. Для сервера, который отслеживает запросы по IP, атака, состоящая из 10 000 запросов с 10 000 разных IP, выглядит как 10 000 разных пользователей, сделавших по одному запросу. Лимит скорости никогда не будет достигнут. Это заставляет защитников переходить к более сложным методам, которые анализируют не только IP, но и другие характеристики запроса и поведения.
Межсетевые экраны для веб-приложений (WAF): Привратник на основе правил
Web Application Firewall (WAF) — это специализированный защитный экран, который анализирует HTTP-трафик между пользователем и веб-приложением. Его основная задача — блокировать вредоносные запросы, соответствующие известным шаблонам атак, таким как SQL-инъекции, межсайтовый скриптинг (XSS) и другие.37
В контексте защиты от ботов WAF выполняет несколько функций:
- Блокировка по сигнатурам: WAF может блокировать запросы, содержащие известные User-Agent строки, принадлежащие вредоносным ботам или парсерам.
- Блокировка по IP-адресам: WAF может использовать постоянно обновляемые черные списки IP-адресов, с которых ведутся атаки.
- Географическая блокировка: Если ваш бизнес ориентирован на конкретный регион, WAF может блокировать трафик из стран, откуда легитимные пользователи приходить не должны.
Пример правила блокировки ботов по User-Agent в файле .htaccess (для Apache):
Apache
RewriteEngine On
# Блокируем известных ботов-парсеров
RewriteCond %{HTTP_USER_AGENT} "AhrefsBot"
RewriteCond %{HTTP_USER_AGENT} "SemrushBot"
RewriteCond %{HTTP_USER_AGENT} "MJ12bot"
RewriteCond %{HTTP_USER_AGENT} "DotBot" [NC]
# Отправляем запрещенным ботам ошибку 403 Forbidden
RewriteRule.* - [F,L]
Этот код проверяет User-Agent каждого входящего запроса и, если он совпадает с одним из перечисленных, блокирует доступ.40
WAF является важным элементом защиты, но он эффективен в основном против известных и относительно простых ботов. Изощренные боты легко меняют свои User-Agent и используют прокси-сети, чтобы обойти IP-блокировки, что делает WAF на основе статических правил менее эффективным. Поэтому WAF часто используется в сочетании с более динамическими методами обнаружения.
Часть 4: Интеллектуальное обнаружение: Отделяя людей от машин
Когда серверные средства защиты, основанные на статических правилах и IP-адресах, оказываются недостаточными, наступает время для более интеллектуальных методов. Эти технологии направлены на то, чтобы отличить человека от автоматизированной программы, анализируя их поведение, характеристики браузера и способность решать сложные задачи.
Дилемма CAPTCHA: Тест Тьюринга для веба
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) — это тест, предназначенный для того, чтобы быть простым для человека, но сложным для компьютера.37 Это один из самых старых и известных методов защиты от ботов.
Технология CAPTCHA прошла долгий путь эволюции:
- Текстовая CAPTCHA: Первое поколение, требующее от пользователя распознать и ввести искаженные буквы и цифры. Сегодня такие CAPTCHA легко решаются с помощью алгоритмов машинного зрения.41
- CAPTCHA на основе изображений: Пользователю предлагается выбрать все изображения с определенным объектом (например, «светофоры» или «автобусы»). Этот тип более устойчив, но все еще уязвим для современных ИИ.
- reCAPTCHA v2 («Я не робот»): Разработанная Google, эта система анализирует поведение пользователя еще до того, как он поставит галочку. Оцениваются движения мыши, скорость клика и другие параметры. Если поведение кажется подозрительным, пользователю предлагается решить задачу с изображениями.42
- reCAPTCHA v3 (Невидимая): Эта версия работает полностью в фоновом режиме, не требуя от пользователя никаких действий. Она анализирует поведение пользователя на сайте и присваивает ему «оценку риска» от 0.0 (бот) до 1.0 (человек). Владелец сайта может затем решать, что делать с пользователями с низкой оценкой: заблокировать, потребовать дополнительную аутентификацию или просто пропустить.41
Главный недостаток CAPTCHA — это пользовательское трение (user friction). Видимые тесты раздражают пользователей, снижают конверсию и могут быть непреодолимым барьером для людей с ограниченными возможностями.43 Кроме того, даже самые сложные CAPTCHA сегодня могут быть обойдены. Существуют как автоматизированные решатели на базе ИИ, так и целые сервисы, где живые люди за небольшую плату решают тысячи CAPTCHA в час для ботов.42
| Тип CAPTCHA | Механизм | Преимущества | Недостатки | Уязвимость для ботов |
| Текстовая | Распознавание искаженного текста | Простота реализации | Высокое трение для пользователя, низкая доступность | Высокая. Легко решается OCR-алгоритмами. |
| На основе изображений | Классификация объектов на картинках | Сложнее для простых ботов | Раздражает пользователей, может быть медленной | Средняя. Обходится с помощью ИИ и сервисов-решателей. |
| reCAPTCHA v2 (Галочка) | Поведенческий анализ + задача | Низкое трение при успешной проверке | Все еще требует действия, может показать задачу | Средняя. Обходится, но требует более сложных ботов. |
| reCAPTCHA v3 (Невидимая) | Фоновый поведенческий анализ | Нет трения для пользователя | Требует сложной логики на стороне сайта для обработки оценки | Низкая. Сложнее всего обойти, так как основана на поведении. |

Расставляя ловушки: Реализация «приманок» (Honeypots)
Honeypot — это обманный механизм, который невидим для обычного пользователя, но виден и привлекателен для ботов.39 Когда бот взаимодействует с такой приманкой, он выдает себя, и система может его заблокировать.
Практические примеры реализации:
- Скрытые поля формы: В форму (например, регистрации или обратной связи) добавляется дополнительное поле, которое скрывается от пользователей с помощью CSS.
HTML:HTML
<form action="/submit" method="post">
<label for="name">Имя:</label>
<input type="text" id="name" name="name">
<label for="email">Email:</label>
<input type="email" id="email" name="email">
<div style="position: absolute; left: -5000px;" aria-hidden="true">
<input type="text" name="fax_number" tabindex="-1" autocomplete="off">
</div>
<button type="submit">Отправить</button>
</form>
Человек не увидит поле fax_number, так как оно визуально скрыто. Однако простой бот, который автоматически заполняет все поля формы, заполнит и его. На сервере достаточно проверить, заполнено ли это поле. Если да — это бот.44 - Скрытые ссылки: На страницу добавляется ссылка, невидимая для человека (например, сделанная того же цвета, что и фон, или скрытая через display: none).
HTML:HTML
<a href="/bot-trap-page" style="display: none;" rel="nofollow">Секретная ссылка</a>
Любой переход по этой ссылке может быть однозначно идентифицирован как действие бота, который сканирует все ссылки в HTML-коде.44 Можно пойти дальше и запретить доступ к
/bot-trap-page в файле robots.txt. Это создаст двойную ловушку: «плохие» боты, игнорирующие robots.txt, перейдут по ссылке и будут пойманы; «хорошие» боты подчинятся robots.txt и не попадутся.
Honeypots — это не только метод блокировки, но и ценный инструмент для сбора информации о ботах, атакующих ваш сайт.45
Цифровые отпечатки: Каждый браузер уникален
Цифровой отпечаток (fingerprinting) — это техника сбора множества атрибутов браузера и устройства для создания уникального идентификатора посетителя.39 Этот идентификатор остается стабильным даже после очистки cookie.
Глубокое погружение: Canvas Fingerprinting
Это один из самых мощных методов. Его принцип работы следующий:
- С помощью JavaScript на странице создается невидимый элемент <canvas>.
- На этом холсте рисуется сложная 2D-графика с текстом и фигурами.
- Из-за мельчайших различий в аппаратном обеспечении (видеокарта), драйверах, операционной системе и настройках сглаживания шрифтов, итоговое изображение будет уникальным практически для каждого устройства.
- Скрипт считывает пиксельные данные этого изображения и преобразует их в хэш-строку (например, с помощью алгоритма SHA-256).
- Эта строка и есть уникальный и очень точный «отпечаток» браузера.53
Помимо Canvas, для создания отпечатка используются и другие параметры:
- Список установленных шрифтов.
- Разрешение экрана и глубина цвета.
- Версия браузера и операционной системы.
- Список плагинов.
- Отпечаток WebGL (рендеринг 3D-графики).
- Отпечаток аудиоконтекста (обработка звука).
Системы защиты собирают эти отпечатки и сравнивают их с базой данных известных отпечатков ботов. Если отпечаток совпадает или имеет аномальные характеристики (например, заявляет, что он Chrome на Windows, но имеет отпечаток, характерный для Linux-сервера), посетитель помечается как бот.
Поведенческий анализ: Высший пилотаж
Это самый сложный и самый эффективный подход. Он фокусируется не на том, кем является посетитель (его отпечаток), а на том, как он себя ведет.52
Системы поведенческого анализа отслеживают и анализируют множество сигналов в реальном времени:
- Движения мыши: Люди двигают курсор плавно, с небольшими изгибами и остановками. Боты либо не двигают его вовсе, либо перемещают по идеально прямым линиям с неестественной скоростью.
- Динамика нажатия клавиш: Ритм, скорость и интервалы между нажатиями клавиш при заполнении форм у человека уникальны. Боты вводят текст мгновенно или с постоянными интервалами.
- Паттерны прокрутки: Человек прокручивает страницу неравномерно, останавливаясь для чтения. Бот прокручивает страницу либо мгновенно, либо с постоянной скоростью.
- Последовательность действий: Пользователи переходят по сайту по логичным путям (например, главная -> категория -> товар). Боты могут обращаться к страницам в алфавитном или числовом порядке, игнорируя навигацию.
Эти и десятки других сигналов передаются в модель машинного обучения, которая вычисляет «оценку бота» (Bot Score) — вероятность того, что данный сеанс является автоматизированным.57 На основе этой оценки система может принять решение: разрешить доступ, показать CAPTCHA или полностью заблокировать.
Внедрение таких сложных систем защиты ставит владельцев сайтов перед выбором. Можно выбрать простое и дешевое решение, но оно будет неэффективным. Можно использовать CAPTCHA, которая эффективна, но ухудшает пользовательский опыт и снижает конверсию. А можно внедрить невидимые и эффективные методы, такие как поведенческий анализ, но это требует значительных технических и финансовых вложений. Этот компромисс между эффективностью, удобством для пользователя и сложностью реализации является ключевым фактором, который стимулирует рынок коммерческих сервисов, стремящихся предоставить все три компонента в одном пакете.
Часть 5: Современная гонка вооружений: Противодействие изощренным тактикам обхода
Пока защитники разрабатывают новые методы обнаружения, злоумышленники создают все более совершенные инструменты для их обхода. Эта непрекращающаяся гонка вооружений привела к появлению ботов, которые практически неотличимы от реальных пользователей. Понимание их арсенала — ключ к построению действительно надежной защиты.

Восстание безголовых браузеров (Headless Browsers)
Безголовый браузер — это полноценный веб-браузер (например, Google Chrome или Mozilla Firefox), который работает на сервере без графического интерфейса и управляется с помощью программного кода.55 Инструменты автоматизации, такие как
Puppeteer, Playwright и Selenium, позволяют ботам использовать эти браузеры для взаимодействия с сайтами.
Почему они так опасны?
В отличие от простых скриптов, которые могут только загружать HTML, безголовые браузеры:
- Исполняют JavaScript: Они могут взаимодействовать с динамическими сайтами, построенными на фреймворках вроде React или Angular.
- Рендерят страницы: Они полностью отрисовывают страницу, как и обычный браузер, что позволяет им обходить защиты, основанные на анализе DOM.
- Имитируют действия пользователя: Они могут нажимать на кнопки, заполнять формы, прокручивать страницу и выполнять любые другие действия, доступные человеку.
Это делает их идеальным инструментом для обхода большинства базовых и средних уровней защиты.
Глубокое погружение: Как обнаружить безголовый браузер
Несмотря на их продвинутость, стандартные безголовые браузеры оставляют следы, которые могут быть обнаружены системами защиты:
- Флаг navigator.webdriver: В автоматизированных браузерах это свойство JavaScript по умолчанию имеет значение true. Простая проверка if (navigator.webdriver) может выдать бота.55
- Несоответствия в User-Agent: Стандартный User-Agent безголового Chrome содержит строку «HeadlessChrome», что является очевидным признаком.60
- Отсутствие браузерных плагинов: У безголовых браузеров обычно пустой массив navigator.plugins, в то время как у большинства реальных пользователей там есть хотя бы один плагин (например, для просмотра PDF).62
- Специфические переменные: Фреймворки автоматизации могут внедрять в окружение страницы глобальные переменные, такие как window.__playwright__binding__ или document.__selenium_unwrapped, наличие которых прямо указывает на бота.60
- Аномалии в отпечатках: Безголовые браузеры, запущенные на серверах, часто имеют аномалии в цифровых отпечатках. Например, WebGL-отпечаток может соответствовать серверной видеокарте, а не потребительской, или разрешение экрана может быть нестандартным.
Разумеется, создатели ботов знают об этих методах обнаружения и активно им противодействуют. Они используют специальные «стелс-плагины» или модифицированные версии браузеров, которые скрывают эти следы. Например, они могут переопределить свойство navigator.webdriver или подменить User-Agent.58
Пример кода, который используют скрейперы для маскировки (на Puppeteer):
JavaScript
// Запуск Puppeteer с опциями для обхода обнаруженияconst browser = await puppeteer.launch({
args: ['--disable-blink-features=AutomationControlled'] // Скрывает флаг автоматизации
});
const page = await browser.newPage();
// Переопределение свойства webdriver на каждой новой странице
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
});
});
Под чужим флагом: Проблема резидентных и мобильных прокси-сетей
Даже самый совершенный безголовый браузер будет быстро заблокирован, если все его запросы будут исходить с одного и того же IP-адреса, принадлежащего дата-центру. Чтобы решить эту проблему, скрейперы используют прокси-сети.
- Прокси дата-центров: Это IP-адреса, принадлежащие хостинг-провайдерам. Они дешевые и быстрые, но их диапазоны хорошо известны, и они легко блокируются.63
- Резидентные прокси: Это IP-адреса, выданные интернет-провайдерами обычным домашним пользователям. Запросы, проходящие через такие прокси, выглядят как трафик от реальных людей, что делает их практически невозможным для блокировки на основе IP.63
- Мобильные прокси: IP-адреса, принадлежащие операторам сотовой связи. Этот трафик также считается очень надежным.
Крупнейшие прокси-провайдеры, такие как Bright Data или Oxylabs, оперируют сетями, насчитывающими десятки миллионов резидентных IP-адресов по всему миру.64 Скрейпер может настроить
ротацию прокси, при которой каждый его запрос отправляется с нового, случайного IP-адреса. Это полностью нейтрализует защиту, основанную на IP-репутации и ограничении скорости.
Идеальный шторм: Комбинированный стек для максимальной скрытности
Самый изощренный современный бот — это комбинация нескольких технологий:
- Модифицированный безголовый браузер со «стелс»-настройками для обхода JavaScript-проверок и снятия цифровых отпечатков.
- Ротируемая резидентная прокси-сеть для маскировки IP-адреса и обхода сетевых блокировок.
- Алгоритмы имитации человеческого поведения, которые добавляют случайные задержки, имитируют движения мыши и следуют естественным путям навигации по сайту.
Противостоять такой угрозе с помощью отдельных, несвязанных методов защиты практически невозможно. Это требует комплексного подхода, который анализирует всю совокупность сигналов. Современные системы защиты выигрывают, находя несоответствия между различными уровнями этого тщательно подделанного окружения. Например, система может обнаружить, что IP-адрес запроса геолоцируется в Бразилии, язык браузера установлен как русский, а часовой пояс — UTC. Или браузер утверждает, что он Chrome на Windows, но его WebGL-отпечаток соответствует графическому процессору Linux-сервера. Именно эти противоречия между сетевым уровнем (IP), уровнем приложения (браузер) и уровнем поведения (действия) позволяют выявить даже самого продвинутого бота. Такой целостный, межслойный анализ является ядром передовых коммерческих решений.
Часть 6: Вызов специалистов: Руководство по коммерческим сервисам защиты от ботов
Самостоятельная разработка и поддержка комплексной системы защиты от ботов — задача чрезвычайно сложная, требующая глубоких знаний и постоянного внимания. Для большинства компаний более рациональным решением является использование готовых коммерческих сервисов. Эти платформы специализируются на борьбе с автоматизированными угрозами и предлагают передовые технологии в виде удобного продукта.
Комплексные платформы: Провайдеры CDN и WAF
Крупнейшие игроки на этом рынке предоставляют защиту от ботов как часть более широкого пакета услуг по доставке контента и безопасности. Они работают как обратный прокси: весь трафик к вашему сайту сначала проходит через их глобальную сеть, где он фильтруется и очищается от угроз.
- Cloudflare: Один из самых популярных сервисов, предлагающий щедрый бесплатный тариф, что делает его доступным для сайтов любого размера. Его решение Bot Management использует данные, собранные с миллионов сайтов в его сети, для обучения моделей машинного обучения. Система анализирует поведение, применяет цифровые отпечатки и выставляет каждому посетителю «оценку бота», на основе которой можно настроить правила (пропустить, показать CAPTCHA, заблокировать).37 Cloudflare также активно внедряет альтернативы CAPTCHA, такие как Private Access Tokens, для снижения трения для пользователей.71
- Akamai: Один из старейших и крупнейших CDN-провайдеров, ориентированный в основном на крупных корпоративных клиентов. Его Bot Manager является одним из лидеров рынка и использует сложные алгоритмы поведенческого анализа и машинного обучения для обнаружения самых продвинутых ботов.39
- Imperva: Еще один лидер в сегменте enterprise-безопасности, известный своим мощным WAF и решением Advanced Bot Protection. Imperva ежегодно публикует авторитетный отчет Bad Bot Report, который является важным источником данных о ландшафте автоматизированных угроз.1
Специализированные российские сервисы для защиты от рекламного мошенничества и ботов
На российском рынке также существуют сильные игроки, часто с более узкой специализацией, что может быть преимуществом для решения конкретных задач.
- Фокус: clickfraud.ru: Этот сервис, как следует из названия, в первую очередь специализируется на защите рекламных кампаний в Яндекс.Директ и Google Ads от скликивания (кликфрода).10
- Принцип работы: clickfraud.ru устанавливает на сайт свой код отслеживания, который собирает данные о каждом посетителе, пришедшем с рекламы. Система анализирует десятки параметров, включая IP-адрес, цифровой отпечаток браузера и поведенческие факторы, чтобы выявить мошенническую активность.75
- Механизм блокировки: Когда алгоритмы машинного обучения идентифицируют бота, его IP-адрес или идентификатор (например, yaClientID) автоматически добавляется в списки исключений непосредственно в рекламных кампаниях через API Яндекса и Google. Это предотвращает дальнейшие показы рекламы этому боту, экономя бюджет рекламодателя.10
Сравнительная таблица коммерческих решений по управлению ботами
Выбор правильного сервиса зависит от конкретных задач, масштаба бизнеса и бюджета. Эта таблица поможет сориентироваться в многообразии предложений.
| Провайдер | Основной сценарий использования | Ключевые методы обнаружения | Модель развертывания | Ценовой сегмент |
| Cloudflare | Общая безопасность сайта, защита от DDoS, управление ботами | Машинное обучение, поведенческий анализ, отпечатки, IP-репутация (глобальная сеть) | Смена DNS (прокси) | Есть бесплатный тариф, SMB, Enterprise |
| Akamai | Enterprise CDN, безопасность для крупных компаний | Поведенческий анализ, машинное обучение, обнаружение аномалий | Смена DNS (прокси) | Enterprise |
| Imperva | Enterprise WAF, защита API и приложений | Поведенческий анализ, машинное обучение, защита от захвата аккаунтов | Смена DNS (прокси) | Enterprise |
| clickfraud.ru | Защита от скликивания (кликфрода) в Яндекс.Директ и Google Ads | Машинное обучение, отпечатки, анализ сессий, IP-черные списки | JavaScript-тег на сайте, интеграция по API с рекламными платформами | SMB |
Эта таблица наглядно демонстрирует, что для разных проблем существуют разные решения. Владельцу интернет-магазина, страдающему от скликивания рекламы, нет смысла платить за дорогостоящий Enterprise-пакет от Akamai. Специализированный сервис, такой как clickfraud.ru, решит его проблему более эффективно и за меньшие деньги. В то же время, крупной финансовой организации, нуждающейся в комплексной защите от всех видов атак, включая захват аккаунтов и атаки на API, больше подойдет решение уровня Cloudflare или Imperva.

Часть 7: Поле битвы — закон: Является ли веб-скрейпинг преступлением?
Техническая защита — это лишь одна сторона медали. Вторая — юридическая. Понимание правового статуса парсинга данных имеет решающее значение как для тех, кто защищается, так и для тех, кто собирает данные. Ландшафт здесь сложен и постоянно меняется, но ключевые прецеденты и законы дают четкие ориентиры.
Знаковое дело: hiQ Labs против LinkedIn
Это судебное разбирательство в США стало поворотным моментом в юридической оценке веб-скрейпинга.
- Суть дела: Небольшая аналитическая компания hiQ Labs занималась парсингом общедоступных данных из профилей пользователей LinkedIn для создания аналитических отчетов для работодателей. LinkedIn попыталась заблокировать hiQ, отправив официальное требование прекратить деятельность и применив технические блокировки, ссылаясь на американский Закон о компьютерном мошенничестве и злоупотреблениях (CFAA).78
- Ключевое решение: Апелляционный суд девятого округа США постановил, что сбор данных, которые являются общедоступными и не требуют авторизации (не находятся за «логином и паролем»), не является «несанкционированным доступом» в понимании закона CFAA. Это означает, что сам по себе парсинг публичной информации не является уголовным преступлением в США.78
- Важный нюанс: Несмотря на победу по CFAA, в конечном итоге было признано, что hiQ нарушила Условия предоставления услуг (Terms of Service) LinkedIn, которые прямо запрещали автоматический сбор данных. Это является нарушением контракта.80
Этот прецедент кардинально изменил правовую стратегию защиты от парсинга. Он показал, что попытки приравнять парсинг публичных данных к взлому в большинстве случаев бесперспективны. Вместо этого правовое поле сместилось от уголовного права к гражданскому (договорному) праву.
Сила Условий предоставления услуг (ToS)
После дела hiQ против LinkedIn стало очевидно, что главным юридическим инструментом защиты сайта от парсинга являются его Условия предоставления услуг (ToS) или Пользовательское соглашение.
- Юридическая основа: ToS — это публичный договор, который каждый пользователь (включая ботов) принимает, заходя на сайт. Если в этом договоре четко и недвусмысленно прописан запрет на использование автоматизированных средств для сбора данных (парсинг, скрейпинг), то любая такая деятельность становится нарушением контракта.83
- Рекомендация: Любой веб-сайт, содержащий ценную информацию, которую необходимо защитить от парсинга, должен иметь в своих ToS пункт, запрещающий автоматизированный сбор данных. Это создает прочную юридическую основу для отправки требований о прекращении деятельности (cease-and-desist letters) и последующих судебных исков о нарушении условий договора.
Таким образом, работа юридического отдела по составлению грамотного Пользовательского соглашения становится такой же важной частью стратегии борьбы с парсингом, как и технические средства защиты, внедряемые разработчиками.
Правовой ландшафт в России
В российском законодательстве нет специального закона, который бы прямо регулировал или запрещал веб-скрейпинг. Однако деятельность по сбору и использованию данных с сайтов подпадает под действие нескольких других законов.
- Авторское право (ст. 1259 ГК РФ): Контент на сайте — тексты, фотографии, видео — является объектом авторского права. Его копирование и последующая перепубликация без разрешения автора являются прямым нарушением закона.86 Парсер, который собирает статьи с вашего блога и размещает их на другом ресурсе, нарушает ваши исключительные права.
- Закон о защите персональных данных (152-ФЗ): Если парсер собирает любую информацию, относящуюся к физическим лицам (имена, фамилии, телефоны, email, адреса), он осуществляет обработку персональных данных. Закон 152-ФЗ устанавливает строгие требования к такой деятельности, включая необходимость получения согласия субъектов данных на их обработку. Сбор и использование персональных данных без законных оснований является серьезным правонарушением.85
- Закон о базах данных: Если ваш контент структурирован и представляет собой базу данных (например, каталог товаров, справочник компаний), он может быть защищен как отдельный объект интеллектуальной собственности. Несанкционированное извлечение и использование существенной части такой базы данных также является нарушением.
Таким образом, хотя сам технический процесс парсинга в России формально не запрещен, использование полученных данных в большинстве случаев будет незаконным, если они защищены авторским правом или являются персональными данными.18
Часть 8: Практический пример: Защита интернет-магазина от атаки парсера цен
Чтобы объединить все рассмотренные концепции в единую картину, рассмотрим вымышленный, но реалистичный сценарий.
Сценарий: Интернет-магазин электроники «ГаджетГалактика» запускает новую линейку товаров. В течение нескольких часов после запуска команда замечает, что конкурирующий магазин предлагает те же товары по цене на 1% ниже. Анализ веб-аналитики показывает аномальную активность: резкий всплеск просмотров страниц новых товаров с огромного количества разных IP-адресов, при этом показатель конверсии равен нулю, а время на странице минимально.
Шаг 1: Идентификация угрозы
Команда анализирует логи веб-сервера и подтверждает наличие тысяч быстрых последовательных запросов к страницам товаров. Попытка заблокировать несколько наиболее активных IP-адресов не дает результата — атака продолжается с новых. Становится очевидно, что это распределенный бот-парсер, использующий прокси-сеть.
Шаг 2: Фундаментальное укрепление
Первым делом системные администраторы внедряют ограничение скорости на сервере NGINX, используя конфигурацию, описанную в Части 3. Они устанавливают жесткий лимит на API-эндпоинты, которые отдают информацию о ценах и наличии товаров. Это замедляет атаку, но не останавливает ее полностью. Злоумышленник просто увеличивает количество используемых IP-адресов, чтобы оставаться в рамках лимита для каждого из них.
Шаг 3: Интеллектуальное обнаружение
Следующим шагом разработчики добавляют приманку (honeypot). В форму «Сообщить о поступлении», которая есть на каждой странице товара, они добавляют скрытое CSS-поле website_url, как было показано в Части 4. Почти сразу же система начинает фиксировать попытки заполнения этой формы от ботов, которые автоматически заполняют все поля. Это позволяет собрать базу данных IP-адресов и цифровых отпечатков атакующего бота и заблокировать их.
Шаг 4: Эскалация и внедрение коммерческого решения
Через некоторое время атакующий адаптируется: его бот становится умнее и перестает заполнять скрытые поля. Производительность сайта все еще страдает из-за большого количества запросов. Руководство «ГаджетГалактики» понимает, что постоянная игра в «кошки-мышки» отнимает слишком много ресурсов у команды разработки. Принимается решение внедрить комплексное коммерческое решение. После анализа рынка выбор падает на Cloudflare и его тарифный план с функцией Bot Management, как описано в Части 6.
Результат:
После перевода сайта на Cloudflare его система поведенческого анализа немедленно идентифицирует аномальный трафик. Система замечает, что запросы, хотя и идут с разных «чистых» резидентных IP, имеют одинаковый цифровой отпечаток браузера и демонстрируют абсолютно нечеловеческое поведение (мгновенные переходы между страницами без движений мыши). Этому трафику присваивается высокая «оценка бота». Команда настраивает правило: всем посетителям с оценкой бота выше определенного порога показывать управляемый вызов (managed challenge) — невидимый для человека тест, который бот пройти не может.
Атака парсера полностью прекращается. Конкурент больше не может автоматически отслеживать цены. Легитимные пользователи не испытывают никаких неудобств. Этот пример демонстрирует важность многоуровневой стратегии: от базовой серверной гигиены до продвинутых управляемых сервисов, которые берут на себя самую сложную часть работы.
Заключение: Проектирование устойчивой и перспективной стратегии защиты
Борьба с вредоносными ботами и парсерами — это не разовая задача, а непрерывный процесс. Ландшафт угроз постоянно меняется: боты становятся умнее, их инструменты — совершеннее, а цели — разнообразнее. Построить абсолютно непробиваемую стену невозможно. Цель состоит в том, чтобы сделать автоматизированные атаки на ваш сайт настолько сложными и дорогостоящими, чтобы они стали экономически невыгодными для злоумышленника.
Ключевой принцип построения такой защиты — эшелонированная оборона (defense-in-depth). Не существует единого «серебряного» решения. Устойчивая стратегия всегда состоит из нескольких уровней защиты, которые дополняют и страхуют друг друга.
- Фундаментальный уровень (Сервер): Начните с основ. Правильно настроенное ограничение скорости (rate limiting) на веб-сервере — это самый эффективный шаг, который вы можете сделать самостоятельно. Он отсечет самых простых и назойливых ботов с минимальными затратами.
- Уровень правил (WAF): Используйте межсетевой экран для веб-приложений для блокировки известных угроз по сигнатурам и IP-адресам. Это хороший второй эшелон, который фильтрует очевидный вредоносный трафик.
- Интеллектуальный уровень (Приложение): Внедряйте умные ловушки (honeypots) для выявления и анализа ботов. Используйте современные, невидимые для пользователя CAPTCHA (например, reCAPTCHA v3) на самых критичных участках (формы, API), чтобы отделить людей от машин на основе поведения.
- Стратегический уровень (Управляемые сервисы): Для сайтов, где данные и производительность являются критически важными, использование специализированных коммерческих сервисов — это не роскошь, а необходимость. Платформы вроде Cloudflare, Akamai, Imperva или специализированные решения, как clickfraud.ru, предоставляют доступ к передовым технологиям (поведенческий анализ, машинное обучение, глобальные базы данных угроз), которые невозможно воспроизвести в одиночку.
- Юридический уровень: Убедитесь, что ваши Условия предоставления услуг (Terms of Service) четко запрещают автоматический сбор данных. Это ваш главный правовой щит.
Ниже приведена таблица, которая поможет вам спланировать внедрение защиты, оценив каждый метод по его эффективности и сложности реализации.
| Метод защиты | Оценка эффективности (1-5) | Сложность реализации (1-5) | Основной сценарий использования |
| robots.txt | 1 | 1 | Управление SEO, не для безопасности |
| Блокировка IP-адресов вручную | 1 | 2 | Реакция на единичные инциденты, неэффективно в масштабе |
| Ограничение скорости (Rate Limiting) | 4 | 3 | Защита от перебора, DDoS низкой интенсивности, агрессивного парсинга |
| WAF (на основе правил) | 3 | 3 | Блокировка известных атак и простых ботов |
| CAPTCHA (видимая) | 3 | 2 | Защита форм, но с высоким трением для пользователя |
| Приманки (Honeypots) | 4 | 3 | Обнаружение и анализ наивных и средних ботов |
| Цифровые отпечатки | 4 | 5 | Идентификация продвинутых ботов, обходящих простые проверки |
| Поведенческий анализ | 5 | 5 | Обнаружение самых изощренных ботов, имитирующих человека |
| Управляемый сервис (например, Cloudflare) | 5 | 2 | Комплексная защита для любого сайта, от малого до крупного |
Помните, что ваша защита должна развиваться вместе с угрозами. Регулярный мониторинг логов, анализ аномалий трафика и готовность к адаптации — вот что отличает по-настоящему защищенный веб-ресурс от легкой мишени.
Приложение: Мини-FAQ
- Можно ли полностью заблокировать всех ботов на моем сайте?
Нет, и это не было бы желательным. Цель состоит в том, чтобы управлять ботами: разрешать доступ полезным (например, поисковым системам) и блокировать вредоносные. Полная блокировка всего автоматизированного трафика приведет к исчезновению вашего сайта из поисковой выдачи. - Замедляют ли эти методы защиты мой сайт для реальных пользователей?
Это зависит от метода. Серверные защиты, такие как ограничение скорости, работают очень быстро и практически не влияют на производительность. Тяжелые JavaScript-скрипты для снятия отпечатков или плохо реализованные CAPTCHA могут добавить задержку. Управляемые коммерческие сервисы обычно оптимизированы для максимальной производительности и минимального влияния на скорость загрузки. - Законно ли блокировать ботов, включая поисковые системы?
Да, это ваш сервер, и вы вправе решать, кому предоставлять доступ. Однако блокировка поисковых систем, таких как Googlebot или YandexBot, приведет к тому, что ваш сайт будет исключен из результатов поиска, что для большинства бизнесов крайне нежелательно. - Сколько стоит хорошее решение для защиты от ботов?
Стоимость варьируется в огромном диапазоне: от бесплатных встроенных инструментов на вашем сервере до десятков тысяч долларов в месяц за корпоративные решения от ведущих поставщиков. Многие сервисы, как Cloudflare, предлагают бесплатные или недорогие тарифы, которые обеспечивают хороший базовый уровень защиты. - Мой сайт очень маленький. Мне действительно нужно беспокоиться о ботах?
Да. Даже небольшие сайты становятся целями для спам-ботов, сканеров уязвимостей и парсеров контента. Внедрение фундаментальных мер защиты, таких как ограничение скорости на сервере, всегда является хорошей практикой, независимо от размера сайта. - Какой самый эффективный метод я могу внедрить самостоятельно?
Серверное ограничение скорости (rate limiting). Оно обеспечивает наилучший баланс между эффективностью и сложностью реализации для самостоятельной настройки и дает немедленный результат в борьбе с простейшими автоматизированными угрозами. - Чем сервис clickfraud.ru отличается от такого сервиса, как Cloudflare?
clickfraud.ru — это узкоспециализированный инструмент, основная задача которого — защита рекламного бюджета от мошеннических кликов путем интеграции с рекламными платформами (Яндекс.Директ, Google Ads). Cloudflare — это широкая платформа безопасности, которая защищает всю инфраструктуру вашего сайта от огромного спектра угроз, включая DDoS-атаки, взломы и вредоносных ботов, но защита от скликивания не является ее основной функцией.
Источники
- 2023 Imperva Bad Bot Report, дата последнего обращения: августа 22, 2025, https://www.imperva.com/resources/reports/2023-Imperva-Bad-Bot-Report.pdf
- Imperva: почти половину всей-интернет деятельности в 2023 году составили боты, дата последнего обращения: августа 22, 2025, https://www.tssonline.ru/news/imperva-pochti-polovinu-vsey-internet-deyatelnosti-v-2023-godu-sostavili-boti
- Как проверить трафик сайта на ботов: 7 способов выявления и борьбы – Monodigital, дата последнего обращения: августа 22, 2025, https://monodigital.ru/seo/bot-trafik-na-sajte
- How Attacks from Bad Bots Impact Your Business – F5, дата последнего обращения: августа 22, 2025, https://www.f5.com/resources/white-papers/how-bad-bots-impact-your-business
- Боты – что это такое: виды, применение, обучение и защита от угроз – Skillfactory media, дата последнего обращения: августа 22, 2025, https://blog.skillfactory.ru/glossary/bot/
- Чат-боты: виды, возможности, преимущества, сценарии использования, гайд по настройке – Carrot quest, дата последнего обращения: августа 22, 2025, https://www.carrotquest.io/chatbot/chatbot-types/
- Что такое парсинг, зачем он нужен и законно ли парсить данные | Unisender, дата последнего обращения: августа 22, 2025, https://www.unisender.com/ru/glossary/chto-takoe-parsing/
- ClickFraud – База знаний eLama, дата последнего обращения: августа 22, 2025, https://help.elama.ru/article/51531
- CLICKFRAUD — обзор сервиса – Startpack, дата последнего обращения: августа 22, 2025, https://startpack.ru/application/clickfraud
- Hyper-volumetric DDoS attacks skyrocket: Cloudflare’s 2025 Q2 DDoS threat report, дата последнего обращения: августа 22, 2025, https://blog.cloudflare.com/ddos-threat-report-for-2025-q2/
- DDoS Reports – The Cloudflare Blog, дата последнего обращения: августа 22, 2025, https://blog.cloudflare.com/tag/ddos-reports/
- Targeted by 20.5 million DDoS attacks, up 358% year-over-year: Cloudflare’s 2025 Q1 DDoS Threat Report, дата последнего обращения: августа 22, 2025, https://blog.cloudflare.com/ru-ru/ddos-threat-report-for-2025-q1/
- Cloudflare отразила рекордную DDoS-атаку мощностью 5,6 Тбит/с – Habr, дата последнего обращения: августа 22, 2025, https://habr.com/ru/news/875590/
- Самая мощная DDoS-атака в истории: Cloudflare отбила удар в 7,3 Тбит/с, дата последнего обращения: августа 22, 2025, https://www.anti-malware.ru/news/2025-06-20-111332/46405
- Cloudflare предотвратил рекордное количество DDoS-атак в 2024 году, в том числе гиперобъёмных – 3DNews, дата последнего обращения: августа 22, 2025, https://3dnews.ru/1122000/cloudflare-predotvratil-rekordnoe-kolichestvo-ddosatak-v-2024-godu-v-tom-chislegiperobyomnih
- Веб-скрейпинг: что это такое и зачем он нужен, чем отличается от парсинга и как безопасно извлечь данные с сайта с помощью сервисов – Топвизор–Журнал, дата последнего обращения: августа 22, 2025, https://journal.topvisor.com/ru/seo-kitchen/web-scraping/
- Вредоносные боты на сайте – как их обнаружить и заблокировать • Hostpro Wiki, дата последнего обращения: августа 22, 2025, https://hostpro.ua/wiki/security/how-to-detect-and-block-malicious-bots/
- Антиботы для сайта: ТОП-5 лучших способов защиты от ботов – DTF, дата последнего обращения: августа 22, 2025, https://dtf.ru/luchshii-rating/3123711-antiboty-dlya-saita-top-5-luchshih-sposobov-zashity-ot-botov
- What Are Web Robots and how do they affect SEO? – Network Solutions, дата последнего обращения: августа 22, 2025, https://www.networksolutions.com/help/article/what-are-robots-txt-files
- Robots.txt for SEO: The Ultimate Guide – Conductor, дата последнего обращения: августа 22, 2025, https://www.conductor.com/academy/robotstxt/
- What is Robots.txt and why does it matter in SEO? – TBS Marketing, дата последнего обращения: августа 22, 2025, https://tbs-marketing.com/what-is-robots-txt-and-why-does-it-matter-in-seo/
- Master Robots.txt: Command SEO Success & Secure Your Site | Romain Berg, дата последнего обращения: августа 22, 2025, https://www.romainberg.com/blog/seo/how-does-robots-txt-file-work/
- What is a Robots.txt file (and how does it affect SEO?) – Miles IT, дата последнего обращения: августа 22, 2025, https://www.milesit.com/what-is-a-robots-txt-file-and-how-does-it-affect-seo/
- О файлах robots.txt | Центр Google Поиска | Documentation, дата последнего обращения: августа 22, 2025, https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=ru
- Robots Txt что это правильный файл – настройка – Rush Analytics, дата последнего обращения: августа 22, 2025, https://www.rush-analytics.ru/blog/sozdanie-i-optimizaciya-robotstxt-kontroliruem-indeksaciyu-sayta
- Robots.txt – как пользоваться и каких ошибок избегать – WhitePress.com, дата последнего обращения: августа 22, 2025, https://www.whitepress.com/ru/baza-znaniy/430/robots-txt-kak-polzovatsya-i-kakikh-oshibok-sleduyet-izbegat-vo-vremya-sozdaniya
- Robots.txt – что это, как настроить и как файл влияет на индексирование – Продвижение сайтов в поисковых системах – iSEO, Москва, дата последнего обращения: августа 22, 2025, https://www.iseo.ru/chto-takoe-fajl-robots-txt-i-zachem-on-nuzhen/
- Защита сайта от парсинга: эффективные методы 2025 | Рувеб – RuWeb, дата последнего обращения: августа 22, 2025, https://ruweb.net/articles/kak-zashitit-sajt-ot-parsinga
- NGINX Rate Limiting: The Basics and 3 Code Examples | Solo.io, дата последнего обращения: августа 22, 2025, https://www.solo.io/topics/nginx/nginx-rate-limiting
- Rate Limiting with NGINX – NGINX Community Blog, дата последнего обращения: августа 22, 2025, https://blog.nginx.org/blog/rate-limiting-nginx
- Limiting Access to Proxied HTTP Resources | NGINX Documentation, дата последнего обращения: августа 22, 2025, https://docs.nginx.com/nginx/admin-guide/security-controls/controlling-access-proxied-http/
- How to add rate limiting in Ngnix – YouTube, дата последнего обращения: августа 22, 2025, https://www.youtube.com/watch?v=TfZlXBHtyzE
- Protecting Against Bot Attacks Using Nginx Rate Limits | by Irtiza Hafiz – Medium, дата последнего обращения: августа 22, 2025, https://irtizahafiz.medium.com/protecting-against-bot-attacks-using-nginx-rate-limits-12872fcbaafd
- Как ограничить скорость скачивания в Apache и Nginx – Unihost.FAQ, дата последнего обращения: августа 22, 2025, https://unihost.com/help/ru/how-to-limit-bandwidth-in-apache-and-nginx/
- ТОП 5 сервисов защиты сайта от ботов – лучшие антиботы в 2025 году – DTF, дата последнего обращения: августа 22, 2025, https://dtf.ru/luchshii-rating/3094288-top-5-servisov-zashity-saita-ot-botov-luchshie-antiboty-v-2025-godu
- Как защитить сайт от ботов: советы и рекомендации – lz media, дата последнего обращения: августа 22, 2025, https://lz.media/blog/dev/kak-zashhitit-sajt-ot-botov-sovety-i-rekomendaczii
- 6 лучших решений и программ для защиты от ботов – Защита от …, дата последнего обращения: августа 22, 2025, https://clickfraud.ru/6-luchshih-reshenij-i-programm-dlya-zashhity-ot-botov/
- Эффективные способы защиты от парсинга сайта – MegaIndex, дата последнего обращения: августа 22, 2025, https://ru.megaindex.com/blog/stop-bots
- Что такое капча? Типы, триггеры и преимущества – Bright Data, дата последнего обращения: августа 22, 2025, https://ru-brightdata.com/blog/web-data-ru/what-is-a-captcha
- Антикапча – лучшие сервисы автоматического распознавания и обхода капчи | Блог SEO.RU, дата последнего обращения: августа 22, 2025, https://seo.ru/blog/10-luchshih-servisov-dlya-raspoznavaniya-kapchi/
- Best Bot Attack Prevention Strategies for Your Website – SpdLoad, дата последнего обращения: августа 22, 2025, https://spdload.com/blog/bot-attack-prevention/
- Avoiding Honeypot Traps in Scraping: Advanced Detection and Evasion Techniques, дата последнего обращения: августа 22, 2025, https://www.smile-comfort.com/en/media/avoiding-honeypot-traps-in-scraping
- What are Honeypots and How to Avoid Them in Web Scraping – Scrapfly, дата последнего обращения: августа 22, 2025, https://scrapfly.io/blog/posts/what-are-honeypots-and-how-to-avoid-them
- Honeypot: What is it and how to bypass it for webscraping ?, дата последнего обращения: августа 22, 2025, https://stabler.tech/blog/honeypot-what-is-it-and-how-to-bypass-it-for-webscraping
- Better Honeypot Implementation (Form Anti-Spam) – Stack Overflow, дата последнего обращения: августа 22, 2025, https://stackoverflow.com/questions/36227376/better-honeypot-implementation-form-anti-spam
- Embed the Honeypot link in your web application (optional) – Security Automations for AWS WAF, дата последнего обращения: августа 22, 2025, https://docs.aws.amazon.com/solutions/latest/security-automations-for-aws-waf/embed-the-honeypot-link-in-your-web-application-optional.html
- Can anyone help me to fully understand how the honeypots works : r/it – Reddit, дата последнего обращения: августа 22, 2025, https://www.reddit.com/r/it/comments/1fdheo7/can_anyone_help_me_to_fully_understand_how_the/
- Browser Bot Detection Software – Fingerprint, дата последнего обращения: августа 22, 2025, https://fingerprint.com/products/bot-detection/
- Fingerprinting в интернете: что это, защита и конфиденциальность – Skypro, дата последнего обращения: августа 22, 2025, https://sky.pro/wiki/javascript/fingerprinting-v-internete-chto-eto-zashita-i-konfidencialnost/
- Bot Protection: Attack Examples & 8 Ways to Defend Your Network – Radware, дата последнего обращения: августа 22, 2025, https://www.radware.com/cyberpedia/bot-management/bot-protection/
- Обзор мирового и российского рынков систем защиты от вредоносных ботов (Bot), дата последнего обращения: августа 22, 2025, https://www.anti-malware.ru/analytics/Market_Analysis/Bot-Protection
- Bot detection 101: How to detect web bots? – Antoine Vastel Blog, дата последнего обращения: августа 22, 2025, https://antoinevastel.com/javascript/2020/02/09/detecting-web-bots.html
- Ecommerce Bot Protection: Stop Attacks, Safeguard Your Business – LexisNexis Risk Solutions, дата последнего обращения: августа 22, 2025, https://risk.lexisnexis.com/insights-resources/article/detect-and-mitigate-bot-attacks
- Методология обнаружения ботнетов в комментариях, дата последнего обращения: августа 22, 2025, https://factcheck.by/wp-content/uploads/2025/04/youtube_comments_botnet_methodology.pdf
- The Best Headless Chrome Browser for Bypassing Anti-Bot Systems – Kameleo, дата последнего обращения: августа 22, 2025, https://kameleo.io/blog/the-best-headless-chrome-browser-for-bypassing-anti-bot-systems
- How do I prevent detection of Headless Chromium by websites? – WebScraping.AI, дата последнего обращения: августа 22, 2025, https://webscraping.ai/faq/headless-chromium/how-do-i-prevent-detection-of-headless-chromium-by-websites
- How to detect Headless Chrome bots instrumented with Playwright? – The Castle blog, дата последнего обращения: августа 22, 2025, https://blog.castle.io/how-to-detect-headless-chrome-bots-instrumented-with-playwright/
- How to bypass bot detection | Browserless.io, дата последнего обращения: августа 22, 2025, https://docs.browserless.io/baas/avoid-bot-detection/stealth
- Headless Browser Detection: Techniques and Strategies to Outsmart Bots – Latenode, дата последнего обращения: августа 22, 2025, https://latenode.com/blog/headless-browser-detection-techniques-and-strategies-to-outsmart-bots
- How to Use Proxies for Web Scraping – Zyte, дата последнего обращения: августа 22, 2025, https://www.zyte.com/learn/use-proxies-for-web-scraping/
- Bright Data – All in One Platform for Proxies and Web Scraping, дата последнего обращения: августа 22, 2025, https://brightdata.com/
- Decodo: Award-Winning Proxy & Scraping Solutions, дата последнего обращения: августа 22, 2025, https://decodo.com/
- Best Proxy Solutions for Advanced Web Scraping : r/TheVpnEng – Reddit, дата последнего обращения: августа 22, 2025, https://www.reddit.com/r/TheVpnEng/comments/1l32d45/best_proxy_solutions_for_advanced_web_scraping/
- The Best Residential Proxies for Web Scraping in 2025: A Deep Dive – Reddit, дата последнего обращения: августа 22, 2025, https://www.reddit.com/r/PrivatePackets/comments/1jjeowm/the_best_residential_proxies_for_web_scraping_in/
- Residential Proxies for Ensuring Data Quality while Web Scraping – ScrapingAnt, дата последнего обращения: августа 22, 2025, https://scrapingant.com/blog/residential-proxies-data-quality
- CloudFlare vs Akamai vs Imperva Application Delivery Comparison …, дата последнего обращения: августа 22, 2025, https://www.saasworthy.com/compare/cloudflare-vs-akamai-vs-imperva-application-delivery?pIds=1597,1606,4237
- 【Защита от ботов 】. Мои ТОП-3 сервиса как заблокировать …, дата последнего обращения: августа 22, 2025, https://vc.ru/id593058/906086-zashita-ot-botov-moi-top-3-servisa-kak-zablokirovat-botov-na-saite
- Cloudflare Bot Management & Protection, дата последнего обращения: августа 22, 2025, https://www.cloudflare.com/application-services/products/bot-management/
- Imperva Bad Bot Report 2024: пять ключевых выводов – Softprom, дата последнего обращения: августа 22, 2025, https://softprom.com/ru/imperva-bad-bot-report-2024-pyat-klyuchevyih-vyivodov
- 2024 Bad Bot Report | Resource Library – Imperva, дата последнего обращения: августа 22, 2025, https://www.imperva.com/resources/resource-library/reports/2024-bad-bot-report/
- Imperva a Thales company: Отчет о плохих ботах 2025 – Softprom, дата последнего обращения: августа 22, 2025, https://softprom.com/ru/imperva-a-thales-company-otchet-o-plohih-botah-2025
- Как работает алгоритм обнаружения скликивания? – Clickfraud, дата последнего обращения: августа 22, 2025, https://clickfraud.ru/kak-rabotaet-algoritm-obnaruzheniya-sklikivaniya/
- Кликфрод: как распознать и побороть – UIS, дата последнего обращения: августа 22, 2025, https://www.uiscom.ru/blog/klikfrod-kak-raspoznat-i-poborot/
- База знаний – Защита от скликивания рекламы – Clickfraud, дата последнего обращения: августа 22, 2025, https://clickfraud.ru/help/
- Ninth Circuit Holds Data Scraping is Legal in hiQ v. LinkedIn – California Lawyers Association, дата последнего обращения: августа 22, 2025, https://calawyers.org/privacy-law/ninth-circuit-holds-data-scraping-is-legal-in-hiq-v-linkedin/
- LinkedIn Corp. v. hiQ Labs, Inc. – Epic.org, дата последнего обращения: августа 22, 2025, https://epic.org/documents/linkedin-corp-v-hiq-labs-inc/
- hiQ Labs v. LinkedIn – Wikipedia, дата последнего обращения: августа 22, 2025, https://en.wikipedia.org/wiki/HiQ_Labs_v._LinkedIn
- hiQ Labs, Inc. v. LinkedIn Corp – UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT, дата последнего обращения: августа 22, 2025, https://cdn.ca9.uscourts.gov/datastore/opinions/2022/04/18/17-16783.pdf
- HiQ Labs v. LinkedIn Corp. – Global Freedom of Expression, дата последнего обращения: августа 22, 2025, https://globalfreedomofexpression.columbia.edu/cases/hiq-labs-v-linkedin/
- HiQ v. LinkedIn: web scraping case law – Apify Blog, дата последнего обращения: августа 22, 2025, https://blog.apify.com/hiq-v-linkedin/
- Terms of Service – SigParser, дата последнего обращения: августа 22, 2025, https://www.sigparser.com/terms/terms-of-service
- Является ли веб-скрапинг законным? Все, что вам нужно знать – CapMonster Cloud, дата последнего обращения: августа 22, 2025, https://capmonster.cloud/ru/blog/scraping/is-web-scraping-legal
- Будет ли нарушением авторского права скрапинг сайта и размещение его информации на своём домене со ссылкой на источник без согласия вл-ца? – Яндекс, дата последнего обращения: августа 22, 2025, https://yandex.ru/q/smile/8932065025/
- Веб-скрапинг. Кибрарий – библиотека знаний по кибербезопасности. Всё самое важное и полезное о том, как защитить себя в цифровом мире – Сбербанк, дата последнего обращения: августа 22, 2025, https://www.sberbank.ru/ru/person/kibrary/vocabulary/veb-skraping







