

В современном цифровом мире ваш сайт — это поле битвы, даже если вы этого не осознаете. Согласно исследованиям, почти половина всего интернет-трафика генерируется не людьми, а автоматизированными программами — ботами. Причем на долю вредоносных ботов приходится значительно больше трафика, чем на долю полезных.1 Это не просто фоновый шум. Это целенаправленная, постоянная атака на ваш бизнес. Боты — это не только назойливый спам в комментариях. Это изощренные инструменты, способные в считанные часы истощить ваш рекламный бюджет, украсть интеллектуальную собственность и клиентские базы, обрушить сервер и, что самое коварное, исказить всю вашу бизнес-аналитику до неузнаваемости, заставляя вас принимать неверные решения на основе ложных данных.2
Эта статья — не просто перечень советов. Это комплексный план боевых действий, разделенный на несколько эшелонов обороны. Мы начнем с самых основ — базовых методов, которые должен внедрить каждый владелец сайта, чтобы отсечь примитивные угрозы. Затем мы углубимся в более сложные, но критически важные техники, такие как ограничение частоты запросов на уровне веб-сервера. Мы разберем эволюцию CAPTCHA и научимся применять ее современные, невидимые для пользователя версии. Далее мы погрузимся в мир продвинутого обнаружения: цифровых отпечатков, поведенческой биометрии и хитроумных ловушек-приманок. Мы не обойдем стороной и арсенал противника, изучив, как современные боты обходят защиту с помощью безголовых браузеров. Наконец, мы рассмотрим профессиональные решения — от Web Application Firewall до систем на базе машинного обучения, а также проанализируем сложную юридическую практику, связанную с парсингом данных.
Прочитав это руководство, вы сможете не просто отражать атаки простейших ботов. Вы научитесь понимать логику работы самых изощренных из них, выстраивать многоуровневую, адаптивную систему защиты и выбирать инструменты, соответствующие вашему уровню риска и бюджету. Это знание, которое сохранит ваши деньги, данные и деловую репутацию в условиях невидимой цифровой войны.
Глава 1: Невидимая война: знакомство с миром ботов
Прежде чем строить оборону, необходимо изучить противника. Термин «бот» (сокращение от «робот») обозначает любую программу, выполняющую автоматизированные задачи в интернете.3 Однако далеко не все боты созданы со злым умыслом. Понимание их классификации и целей — первый шаг к построению эффективной защиты.
“Хорошие”, “плохие” и “нейтральные”: классификация ботов
Весь бот-трафик можно условно разделить на две большие категории: полезный и вредоносный.
Полезные боты
Это программы, которые выполняют важные и нужные для функционирования интернета задачи. К ним относятся:
- Поисковые краулеры: Самые известные представители — Googlebot и Bingbot. Эти боты систематически обходят веб-страницы, чтобы индексировать их контент и добавлять в поисковую выдачу. Без них поисковые системы не смогли бы работать.
- Сканеры уникальности контента: Сервисы для проверки на плагиат используют ботов для сканирования сети и сравнения текстов.1
- Мониторинговые боты: Сервисы мониторинга доступности сайтов (аптайма) периодически отправляют запросы, чтобы убедиться, что сайт работает корректно.
Важно понимать, что даже «хорошие» боты могут создавать проблемы. Слишком агрессивное сканирование сайта поисковым роботом или другим сервисом способно вызвать избыточную нагрузку на сервер. К счастью, поведением большинства полезных ботов можно управлять через файл robots.txt или настройки в их собственных панелях управления.1
Эта категория гораздо более разнообразна и представляет прямую угрозу для любого веб-ресурса. Их цели варьируются от мелкого хулиганства до крупномасштабного мошенничества и саботажа.1
- Боты-шпионы и парсеры (Content Scrapers): Эти боты методично сканируют сайты для сбора информации. Их цели могут быть разными: сбор адресов электронной почты и телефонов для спам-баз, кража уникального контента (статей, фотографий) для размещения на других ресурсах, парсинг цен и каталогов товаров для конкурентной разведки.1
- Клик-боты (Click Fraud): Одна из самых дорогостоящих угроз для бизнеса, использующего контекстную рекламу. Эти боты имитируют переходы по рекламным объявлениям (например, в Google Ads или Яндекс.Директ), «скликивая» бюджет и не принося никакой пользы. Часто используются недобросовестными конкурентами для истощения рекламных фондов друг друга.1
- Боты-взломщики (Credential Stuffing/Cracking): Эти программы автоматически подбирают пароли к учетным записям пользователей и администраторов. Они могут использовать как метод простого перебора (brute-force), так и более эффективный метод подстановки учетных данных (credential stuffing), когда бот проверяет на вашем сайте пары логин/пароль, утекшие из баз данных других сервисов.3
- Боты-спамеры: Их основная задача — распространение спама. Они автоматически регистрируют фейковые аккаунты, заполняют формы обратной связи мусорными сообщениями и оставляют рекламные комментарии со ссылками на фишинговые или вредоносные сайты.1
- Боты для DDoS-атак: Эти боты работают в составе сети (ботнета) и по команде отправляют огромное количество запросов на целевой сервер. Их цель — полностью исчерпать ресурсы сервера (пропускную способность канала, процессорное время, память) и сделать сайт недоступным для реальных пользователей.3
- Боты для атак на интернет-магазины: Сравнительно новый, но коварный вид атаки. Боты заходят в интернет-магазин, добавляют дефицитные товары в корзину, но не завершают покупку. Это резервирует товар, и для реальных покупателей он отображается как отсутствующий на складе, что приводит к упущенной выгоде и недовольству клиентов.3
Последствия для бизнеса: скрытый ущерб от бот-активности
Влияние вредоносных ботов не ограничивается очевидными проблемами вроде спама. Они наносят глубокий и многогранный ущерб, затрагивающий финансы, маркетинг, IT-инфраструктуру и репутацию компании.
- Искажение веб-аналитики: Это одна из самых опасных и недооцененных проблем. Боты создают фиктивный трафик, который полностью искажает данные в системах аналитики, таких как Google Analytics и Яндекс.Метрика. Вы можете видеть резкий рост посещаемости, но при этом количество лидов и продаж остается на прежнем уровне или даже падает. Это приводит к неверным выводам об эффективности рекламных кампаний, качестве контента и поведении пользователей, заставляя бизнес вкладывать деньги в неработающие каналы.2 Признаками высокой бот-активности в отчетах могут быть:
- Резкий рост трафика при стагнации или падении конверсий.
- Аномально высокий показатель отказов (близкий к 100%) или, наоборот, аномально низкий (близкий к 0%) при большом количестве сессий от одного источника.6
- Всплески посещений в нетипичное время, например, глубокой ночью.2
- Большое количество прямых заходов, в то время как раньше доминировал трафик из поиска.7
- Вред для SEO: Поисковые системы постоянно совершенствуют свои алгоритмы для оценки качества сайтов, и поведенческие факторы играют в этом ключевую роль. Массовый бот-трафик с высоким показателем отказов и минимальным временем на сайте посылает поисковикам негативный сигнал. В результате сайт может быть пессимизирован, то есть его позиции в поисковой выдаче упадут, что приведет к потере органического трафика.2
- Перегрузка сервера и рост расходов: Каждый запрос к сайту, будь то от человека или бота, потребляет ресурсы сервера: процессорное время, оперативную память, пропускную способность сети. Армия ботов, генерирующая тысячи запросов, может серьезно замедлить работу сайта для реальных пользователей или даже привести к его полной недоступности. Это не только ухудшает пользовательский опыт, но и может привести к прямым финансовым затратам, так как для компенсации нагрузки придется переходить на более дорогой тарифный план хостинга.2
- Прямые финансовые потери: Это наиболее очевидный ущерб. Он складывается из нескольких составляющих:
- Бюджет, слитый на кликфрод в рекламных системах.
- Упущенная выгода из-за атак на доступность товаров в интернет-магазинах.
- Ущерб от кражи интеллектуальной собственности (уникального контента, баз данных).
- Финансовые и репутационные потери в случае успешного взлома и утечки данных пользователей.
Для лучшего понимания угроз, сведем информацию в единую таблицу.
Таблица 1: Классификация вредоносных ботов и их влияние
| Тип бота | Основная цель | Метод работы | Потенциальный ущерб |
| Парсер контента | Кража контента, цен, контактных данных | Последовательный обход страниц, извлечение данных из HTML-кода | Потеря уникальности контента, снижение SEO, утечка коммерческой информации, создание спам-баз 1 |
| Клик-фрод бот | Скликивание рекламных бюджетов | Имитация кликов по рекламным блокам, переходы по ссылкам | Прямые финансовые потери, искажение статистики рекламных кампаний, неэффективное расходование маркетингового бюджета 1 |
| Спам-бот | Размещение спам-ссылок, фишинг | Автоматическое заполнение форм, регистрация аккаунтов, публикация комментариев | Ухудшение репутации сайта, пессимизация в поиске, юридические риски, введение пользователей в заблуждение 3 |
| Бот-взломщик | Получение несанкционированного доступа | Перебор паролей, подстановка учетных данных из утечек (credential stuffing) | Взлом аккаунтов пользователей и администраторов, кража персональных данных, компрометация системы 3 |
| DDoS-бот | Вывод сайта/сервера из строя | Генерация массовых запросов с множества устройств (ботнет) | Полная недоступность сайта, потеря клиентов и дохода, репутационный ущерб 1 |
| Атакующий E-commerce | Саботаж продаж | Массовое добавление товаров в корзину без покупки | Искусственное создание дефицита, упущенная выгода, недовольство реальных покупателей 3 |
Глава 2: Первая линия обороны: простые, но необходимые меры
Прежде чем разворачивать тяжелую артиллерию, важно выстроить базовый уровень защиты. Эти методы не остановят серьезные, целенаправленные атаки, но они способны отсеять самых примитивных ботов и заложить фундамент для более сложных систем обороны. Многие из этих мер не требуют специальных знаний и могут быть реализованы практически на любом сайте.
Файл robots.txt: вежливая просьба, а не приказ
Файл robots.txt — это текстовый файл, размещаемый в корневой директории сайта. Его основное назначение — давать инструкции поисковым роботам и другим «законопослушным» ботам о том, какие страницы или разделы сайта не следует сканировать или индексировать.8 Например, можно запретить индексацию административной панели, личных кабинетов пользователей или результатов внутреннего поиска.
Однако здесь кроется фундаментальное заблуждение многих начинающих вебмастеров. robots.txt — это не инструмент безопасности, а скорее джентльменское соглашение. Протокол его использования является добровольным. Полезные боты от крупных компаний (Google, Яндекс, Bing) будут следовать этим правилам. Но вредоносные боты, созданные для парсинга, спама или поиска уязвимостей, его полностью проигнорируют.10
Полагаться на robots.txt для защиты конфиденциальной информации — все равно что вешать на дверь дома табличку с надписью «Пожалуйста, не входите» и надеяться, что она остановит грабителя. Запрет в robots.txt не только не защищает от атак, но и не дает стопроцентной гарантии, что страница не попадет в поисковый индекс. Если на запрещенную страницу ведут внешние ссылки, поисковая система может узнать о ее существовании и добавить в выдачу, хоть и без описания.11 Для надежного запрета индексации следует использовать мета-тег
robots со значением noindex непосредственно в HTML-коде страницы.
Таким образом, robots.txt остается важным инструментом для управления SEO-краулерами и снижения нагрузки от них, но его нельзя рассматривать как меру защиты от вредоносной активности.
Блокировка по IP-адресу и User-Agent: быстрые, но ограниченные победы
Когда в логах сервера обнаруживается очевидная вредоносная активность с одного IP-адреса, первой инстинктивной реакцией является его блокировка. Это можно сделать на разных уровнях: в файле .htaccess для серверов Apache, в конфигурации NGINX или через панель управления хостингом.
Блокировка по IP
Этот метод эффективен против одиночных, несложных атак. Если один и тот же IP-адрес генерирует тысячи запросов в секунду или пытается подобрать пароль, его блокировка — быстрое и логичное решение. Однако у этого подхода есть серьезные ограничения:
- Динамические IP и прокси: Продвинутые боты редко работают с одного IP. Они используют огромные сети прокси-серверов или целые ботнеты (сети зараженных компьютеров), постоянно меняя свой IP-адрес. Ручная блокировка в таких условиях превращается в бесконечную и безрезультатную игру в “кошки-мышки”.13
- Ограничения платформ: Рекламные системы, где защита от ботов особенно важна, имеют строгие лимиты на количество блокируемых IP. Например, Яндекс.Директ позволяет добавить в черный список всего 25 IP-адресов, а Google Ads — до 500. Этого катастрофически мало для противодействия даже небольшой бот-сети.15
- Риск блокировки реальных пользователей: За одним IP-адресом (особенно у мобильных операторов или в корпоративных сетях) могут находиться сотни и тысячи реальных пользователей. Заблокировав один “плохой” IP, можно случайно отрезать доступ легитимным клиентам.
Фильтрация по User-Agent
Каждый браузер или бот при обращении к сайту передает HTTP-заголовок User-Agent, который сообщает информацию о себе (например, Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36…). Некоторые примитивные боты используют уникальные или легко идентифицируемые строки User-Agent, и их можно заблокировать по этому признаку.13
Проблема в том, что заголовок User-Agent очень легко подделать. Большинство современных ботов маскируются под популярные браузеры, отправляя точно такой же User-Agent, как у обычного пользователя Google Chrome или Firefox. Поэтому фильтрация по этому заголовку эффективна лишь против самых ленивых или устаревших ботов.16
Анализ логов сервера: ручной поиск аномалий
Лог-файлы веб-сервера (access logs) — это бесценный источник информации о том, кто, когда и как обращался к вашему сайту. Регулярный анализ этих логов может помочь выявить подозрительную активность на ранней стадии.
На что следует обращать внимание при анализе логов:
- Частота запросов: Огромное количество запросов с одного IP-адреса за короткий промежуток времени — классический признак парсера или попытки DDoS-атаки. Человек физически не может просматривать десятки страниц в секунду.
- Коды ответа сервера: Массовые запросы, приводящие к ошибкам 404 (Not Found), могут указывать на то, что бот пытается найти уязвимости, сканируя сайт на наличие известных служебных файлов или страниц (например, /wp-admin/).
- Неестественная навигация: Люди обычно перемещаются по сайту последовательно: с главной на категорию, с категории на товар. Боты же могут обращаться к страницам в хаотичном порядке или напрямую запрашивать глубоко вложенные URL, о которых они узнали из карты сайта (sitemap.xml).
- География запросов: Если ваш бизнес ориентирован на Россию, а вы видите шквал запросов из Азии или Африки, это повод для беспокойства.
- Подозрительные User-Agent: Несмотря на легкость подделки, иногда в логах можно встретить User-Agent’ы, явно указывающие на автоматизированные инструменты, например, содержащие слова bot, spider, crawler (не относящиеся к известным поисковым системам).
Ручной анализ логов — трудоемкий процесс, но он дает глубокое понимание происходящего на вашем сервере и помогает выявить аномалии, которые могут быть упущены автоматизированными системами.
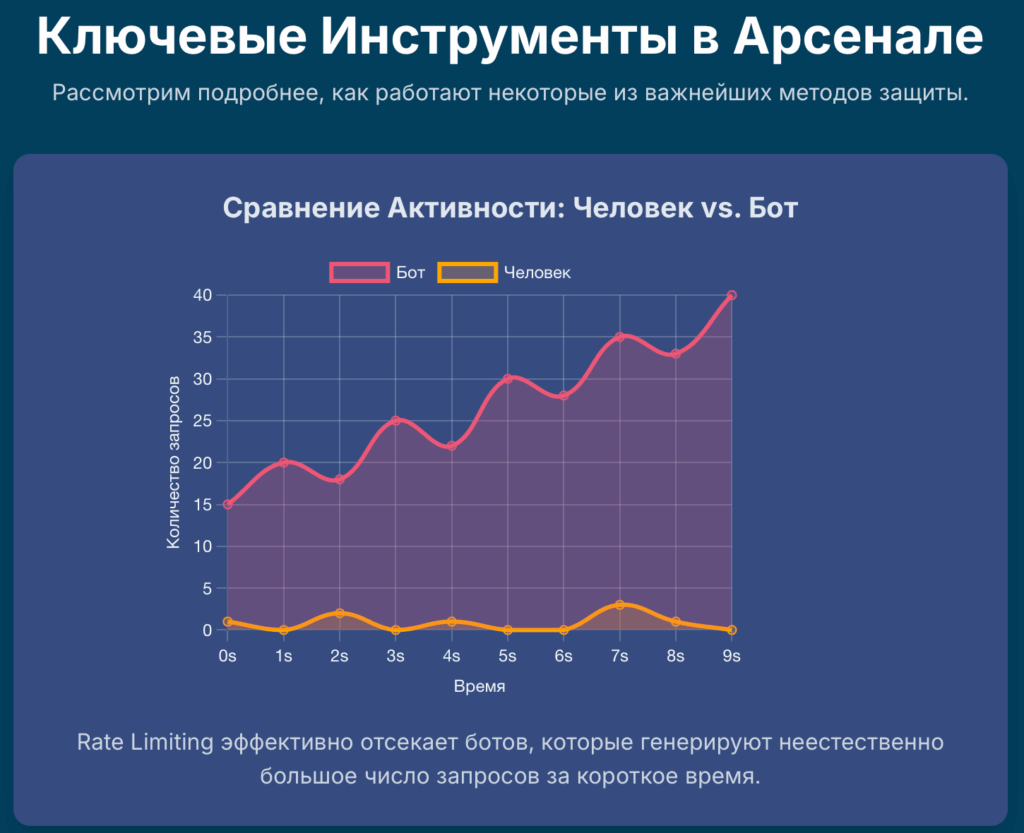
Глава 3: Укрепление периметра: ограничение частоты запросов (Rate Limiting)
Если базовые методы — это замок на двери, то Rate Limiting — это система контроля доступа, которая не просто блокирует нежелательных посетителей, а регулирует сам поток входящего трафика. Это один из самых эффективных способов защиты от брутфорс-атак, агрессивного парсинга и некоторых видов DDoS-атак. Идея проста: ограничить количество запросов, которое один клиент (обычно идентифицируемый по IP-адресу) может сделать за определенный промежуток времени.
Теория “Дырявого ведра” (Leaky Bucket Algorithm): объяснение на пальцах
Большинство современных систем Rate Limiting, включая те, что используются в NGINX, работают на основе алгоритма “дырявого ведра” (Leaky Bucket).17 Этот принцип легко понять на простой аналогии.
Представьте себе ведро, в которое сверху наливают воду. Эта вода — входящие запросы от пользователей. В дне ведра есть небольшое отверстие, через которое вода вытекает с постоянной, фиксированной скоростью. Эта скорость — максимальная частота запросов, которую ваш сервер готов обрабатывать (например, 1 запрос в секунду).
- Если вода (запросы) поступает в ведро медленнее, чем вытекает, все в порядке. Ведро не наполняется, все запросы обрабатываются немедленно.
- Если на короткое время происходит всплеск (кто-то резко вылил стакан воды), ведро начинает наполняться. Вода в ведре — это очередь запросов. Они не отбрасываются, а ждут своей очереди, чтобы вытечь через отверстие с заданной скоростью.
- Если же воду лить в ведро непрерывно и с большой скоростью, оно в конце концов переполнится. Вся вода, которая не поместилась в ведро, проливается мимо. Это запросы, которые сервер отклоняет, обычно с ошибкой 503 Service Temporarily Unavailable.
Таким образом, алгоритм “дырявого ведра” позволяет сглаживать пиковые нагрузки и обеспечивать стабильную, предсказуемую нагрузку на сервер, отсекая при этом чрезмерно активных клиентов, которыми чаще всего и являются боты.
Практическая реализация в NGINX
NGINX предоставляет мощные и гибкие встроенные инструменты для реализации Rate Limiting. Основная настройка выполняется с помощью двух директив: limit_req_zone и limit_req.
Основы
Сначала в секции http конфигурационного файла NGINX необходимо определить зону, в которой будут храниться состояния клиентов. Это делается с помощью limit_req_zone:
Nginx
http {
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=1r/s;
...
}
Разберем эту строку 18:
- $binary_remote_addr: Это ключ, по которому NGINX будет идентифицировать клиентов. $binary_remote_addr — это бинарное представление IP-адреса клиента. Оно используется вместо текстового $remote_addr, так как занимает меньше памяти (4 байта для IPv4), что критично для высоконагруженных систем.
- zone=mylimit:10m: Здесь мы создаем зону в разделяемой памяти (shared memory) с именем mylimit и размером 10 мегабайт. В этой зоне будут храниться счетчики запросов для каждого IP-адреса. Размер в 10 МБ позволяет хранить состояния примерно для 160 000 IP-адресов.
- rate=1r/s: Это и есть та самая “скорость вытекания из ведра”. Мы устанавливаем лимит в 1 запрос в секунду (r/s). Можно использовать и запросы в минуту, например, 30r/m (30 запросов в минуту).
После определения зоны, ее нужно применить к конкретному location или server:
Nginx
server {
location /login/ {
limit_req zone=mylimit;
...
}
}
Теперь для всех запросов к /login/ будет действовать ограничение в 1 запрос в секунду с одного IP.
Управление всплесками (Burst)
В базовой конфигурации любой запрос, пришедший раньше, чем через секунду после предыдущего, будет отклонен. Это слишком жестко для реальных пользователей, так как браузер при загрузке страницы может одновременно запрашивать несколько ресурсов (CSS, JS, картинки). Для решения этой проблемы используется параметр burst:
Nginx
location /api/ {
limit_req zone=mylimit burst=5;
}
Параметр burst=5 создает “ведро” размером в 5 запросов. Это означает, что если с одного IP придет 6 запросов одновременно, первые 5 из них будут поставлены в очередь, а 6-й будет обработан немедленно (если “ведро” было пусто). Остальные запросы из очереди будут обрабатываться с задержкой, чтобы соответствовать установленному лимиту в 1r/s.19
Отключение задержки (Nodelay)
Иногда задержка обработки запросов нежелательна. Мы хотим, чтобы сайт работал максимально быстро для легитимных пользователей, но при этом отсекал откровенные атаки. В этом поможет параметр nodelay:
Nginx
location /images/ {
limit_req zone=mylimit burst=10 nodelay;
}
Комбинация burst=10 nodelay работает иначе. Она позволяет пользователю сделать 10 “лишних” запросов сверх установленного лимита rate, и все они будут обработаны немедленно, без задержки. Однако 11-й “лишний” запрос будет сразу же отклонен с ошибкой, а не поставлен в очередь.
Выбор между конфигурацией с nodelay и без него зависит от цели. Для защиты API, где важна стабильная и предсказуемая нагрузка на бэкенд, лучше использовать burst без nodelay для сглаживания пиков. Для защиты обычных веб-страниц, где важна скорость загрузки для пользователя, лучше подходит burst с nodelay, чтобы разрешить короткие легитимные всплески активности, не замедляя работу сайта.20
Продвинутые техники: белые списки
Часто возникает необходимость исключить из-под действия ограничений определенные IP-адреса, например, IP-адреса поисковых ботов, офисной сети или внутренних сервисов мониторинга. Это можно сделать с помощью директив geo и map 22:
Nginx
geo $limit {
default 1;
192.168.1.0/24 0; # Ваша локальная сеть
8.8.8.8 0; # Пример IP-адреса
}
map $limit $limit_key {
0 "";
1 $binary_remote_addr;
}
limit_req_zone $limit_key zone=mylimit:10m rate=5r/s;
server {
location / {
limit_req zone=mylimit burst=10 nodelay;
...
}
}
В этом примере блок geo присваивает переменной $limit значение 0 для IP-адресов из белого списка и 1 для всех остальных. Блок map на основе значения $limit формирует ключ $limit_key. Если IP в белом списке, ключ будет пустой строкой, и limit_req_zone не будет учитывать такой запрос. Для всех остальных ключ будет равен их IP-адресу, и ограничение сработает.
Практическая реализация в Apache
Хотя NGINX часто считается более удобным инструментом для Rate Limiting, в Apache также есть способы реализовать подобные ограничения, хотя они могут потребовать установки дополнительных модулей.
mod_ratelimit
Начиная с версии 2.4, в Apache появился встроенный модуль mod_ratelimit. Его основное назначение — ограничение скорости скачивания контента, а не частоты запросов. Он полезен, чтобы один пользователь не мог занять всю пропускную способность канала, скачивая большой файл.23
Apache
<Location "/downloads">
SetOutputFilter RATE_LIMIT
SetEnv rate-limit 400
</Location>
Эта конфигурация ограничит скорость скачивания для всех файлов в директории /downloads до 400 КБ/с.
mod_qos
Это сторонний, но очень мощный модуль, предоставляющий гораздо более широкие возможности по контролю трафика. Он позволяет ограничивать не только скорость, но и количество одновременных соединений, частоту запросов к определенным URL, и все это — с возможностью задавать разные правила для разных IP-адресов или виртуальных хостов.24
Пример конфигурации mod_qos:
Apache
<IfModule mod_qos.c>
# Максимум 50 одновременных соединений с одного IP
QS_SrvMaxConnPerIP 50
# Ограничить частоту запросов к странице входа
<Location /login.php>
# 1 запрос в 2 секунды
SetEnvIf Request_URI "/login.php" QS_Limit
QS_SetEnvIf QS_Limit 10
</Location>
</IfModule>
Конфигурация mod_qos может быть довольно сложной, но его гибкость позволяет реализовать практически любые сценарии ограничения.
mod_security
ModSecurity — это, по сути, Web Application Firewall (WAF) для Apache. Хотя его основная задача — защита от атак на веб-приложения (SQL-инъекции, XSS), его гибкая система правил позволяет реализовать и Rate Limiting.24
Пример, ограничивающий количество запросов до 60 в минуту с последующей блокировкой:
Apache
<LocationMatch "^/api/">
SecAction "initcol:ip=%{REMOTE_ADDR},pass,nolog,id:101"
SecAction "phase:5,deprecatevar:ip.apicounter=1/60,pass,nolog,id:102"
SecRule IP:APICOUNTER "@gt 60" "phase:2,deny,status:429,log,msg:'Rate limit exceeded',id:103"
SecAction "phase:2,pass,setvar:ip.apicounter=+1,nolog,id:104"
</LocationMatch>
Этот подход очень гибок, но требует хорошего понимания синтаксиса и логики работы ModSecurity.
Сравнивая подходы, можно отметить, что NGINX предлагает наиболее простую, производительную и “родную” реализацию Rate Limiting. В мире Apache для достижения схожей функциональности часто приходится прибегать к более сложным или сторонним модулям. Это одна из причин, почему в современной веб-разработке часто используется связка, где NGINX выступает в роли обратного прокси-сервера перед Apache, беря на себя задачи по балансировке нагрузки, кешированию и ограничению трафика.24
Глава 4: Тест Тьюринга 2.0: современные CAPTCHA и пользовательские проверки
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) — это общее название для тестов, которые призваны отличить человека от компьютера. На протяжении многих лет CAPTCHA была основным и самым узнаваемым инструментом для защиты веб-форм от спам-ботов. Однако технологии не стоят на месте, и сама CAPTCHA прошла значительную эволюцию.
Эволюция CAPTCHA: от кривых букв до невидимого анализа
- Текстовые CAPTCHA: Это самый старый и классический вид. Пользователю показывается изображение с искаженными, перечеркнутыми или зашумленными буквами и цифрами, которые нужно ввести в поле. Идея заключалась в том, что человеческий мозг легко распознает такие символы, а компьютерные программы (OCR — оптическое распознавание символов) — нет. Однако с развитием нейронных сетей современные алгоритмы научились распознавать даже сильно искаженный текст, что сделало этот вид CAPTCHA практически бесполезным против серьезных угроз.5
- CAPTCHA на основе изображений: Следующим шагом стала reCAPTCHA v2 от Google. Вместо распознавания текста пользователю предлагается выполнить более сложную с точки зрения семантики задачу. Сначала это был простой чекбокс “Я не робот”. При нажатии на него Google в фоновом режиме анализировал множество параметров (движение мыши к чекбоксу, IP-адрес, cookie и т.д.) и, если пользователь казался подозрительным, предлагал дополнительное задание: выбрать на картинках все светофоры, автомобили или дорожные знаки. Такая задача требует не простого распознавания, а классификации объектов, что для ботов значительно сложнее.5
- Аудио-CAPTCHA: В качестве альтернативы для людей с нарушениями зрения была разработана аудио-версия. Пользователю проигрывается аудиозапись с произносимыми цифрами или буквами, которые также искажены фоновым шумом, чтобы затруднить автоматическое распознавание речи.5
- Невидимая CAPTCHA (reCAPTCHA v3): Это вершина эволюции на данный момент. Эта технология полностью избавляет пользователя от необходимости выполнять какие-либо действия. Она работает в фоновом режиме, анализируя поведение пользователя на сайте и выставляя ему “оценку доверия”. Это позволяет обеспечить защиту, не создавая барьеров и не ухудшая пользовательский опыт.28
Глубокое погружение в reCAPTCHA v3
reCAPTCHA v3 кардинально меняет подход к защите. Вместо бинарного ответа “человек/бот”, она предоставляет владельцу сайта более тонкий инструмент.
Принцип работы
После установки на сайт скрипт reCAPTCHA v3 начинает собирать данные о поведении пользователя: как он двигает мышью, с какой скоростью и ритмом печатает, как скроллит страницу, по каким ссылкам переходит. На основе этого комплексного анализа каждому действию пользователя присваивается оценка (score) от 0.0 до 1.0. Оценка 1.0 означает, что взаимодействие с высокой вероятностью совершено человеком, а 0.0 — что это, скорее всего, бот.30
Концепция “Действий” (Actions)
Для повышения точности reCAPTCHA v3 вводит понятие “действий”. Разработчик может разметить ключевые этапы взаимодействия на сайте специальными тегами. Например, action: ‘login’ для страницы входа, action: ‘comment’ для отправки комментария, action: ‘add_to_cart’ для добавления товара в корзину. Это позволяет аналитической системе понимать контекст. Поведение пользователя на странице входа и на странице чтения статьи может сильно различаться, и разметка действий помогает reCAPTCHA строить более точные поведенческие модели для каждого сценария и эффективнее выявлять аномалии.28
Сложности внедрения
Несмотря на кажущуюся простоту, внедрение reCAPTCHA v3 имеет важный нюанс, который часто упускают из виду. В отличие от предыдущих версий, где Google сам принимал решение о блокировке, reCAPTCHA v3 перекладывает эту ответственность на владельца сайта. Сервис лишь предоставляет оценку, а что с ней делать дальше — решает разработчик. Это открывает гибкие возможности, но и создает сложности.32
Например, получив оценку, можно реализовать разную логику:
- Оценка > 0.7: Пропустить действие без каких-либо проверок.
- Оценка от 0.3 до 0.7: Потребовать дополнительную верификацию (например, подтверждение по email или SMS) или показать пользователю старую добрую reCAPTCHA v2.
- Оценка < 0.3: Заблокировать действие или отправить контент (например, комментарий) на ручную модерацию.
Главная проблема заключается в выборе этих пороговых значений (thresholds). Слишком низкий порог пропустит ботов, а слишком высокий — будет блокировать реальных пользователей, что приведет к потере клиентов. Поэтому правильное внедрение reCAPTCHA v3 — это итеративный процесс. Сначала ее запускают в “пассивном” режиме, не выполняя никаких блокировок, а лишь собирая статистику по оценкам для разных действий в консоли администратора. После анализа этих данных и выявления закономерностей можно аккуратно выставлять пороги и внедрять реальные защитные меры.32
hCaptcha и другие альтернативы
Рынок CAPTCHA не ограничивается решениями от Google.
- hCaptcha: Это главный конкурент reCAPTCHA, который делает упор на конфиденциальность данных пользователей. Принцип работы похож на reCAPTCHA v2: пользователю предлагается решить задачу по распознаванию и классификации изображений. Важным преимуществом является полная API-совместимость с reCAPTCHA, что позволяет разработчикам переключиться с одного сервиса на другой с минимальными изменениями в коде.35 hCaptcha также анализирует поведенческие факторы, такие как движения мыши и скролл, для первичной оценки.36
- Простая капча от Clickfraud.ru: Это пример интегрированного решения, где CAPTCHA является частью комплексного сервиса защиты от ботов. Ее особенность — максимальная простота для пользователя (часто достаточно одного клика) и использование собственных алгоритмов машинного обучения, которые анализируют траекторию движения мыши для выявления ботов. Это хороший вариант для тех, кто ищет готовое решение, не требующее сложной настройки.37
Влияние на SEO и пользовательский опыт (UX)
Любая видимая CAPTCHA — это препятствие на пути пользователя. Она прерывает его действия, заставляет тратить время и умственные усилия, что может вызывать раздражение и приводить к снижению конверсии. Исследования показывают, что отключение CAPTCHA на формах может увеличить количество успешных отправок на несколько процентов.38
С точки зрения SEO, главная опасность заключается в неправильном применении CAPTCHA. Если для доступа к контенту страницы необходимо сначала решить капчу, то поисковый робот Googlebot не сможет пройти эту проверку и, соответственно, не проиндексирует содержимое страницы. Это приведет к ее выпадению из поисковой выдачи. Поэтому критически важно, чтобы CAPTCHA защищала только конкретные действия (отправку формы, нажатие кнопки), а сам контент страницы всегда был доступен для сканирования поисковыми системами.38
Таблица 2: Сравнение современных решений CAPTCHA
| Решение | Принцип работы | Видимость для пользователя | Уровень защиты | Влияние на UX | Сложность внедрения |
| reCAPTCHA v2 Checkbox/Images | Интерактивная задача (выбор картинок) + фоновый анализ | Видимая | Средний (уязвима к сервисам распознавания) | Негативное (прерывает действие) | Низкая |
| reCAPTCHA v3 | Поведенческий анализ в фоновом режиме, выдача оценки | Невидимая | Высокий | Минимальное | Средняя/Высокая (требует настройки серверной логики) |
| hCaptcha | Интерактивная задача (выбор картинок), фокус на приватности | Видимая | Высокий | Негативное (прерывает действие) | Низкая |
| Простая CAPTCHA (Clickfraud.ru) | Анализ движения мыши, простая интерактивная задача | Минимально видимая | Средний/Высокий | Низкое | Низкая (в рамках сервиса) |
Глава 5: Мыслить как бот: продвинутые методы пассивного обнаружения
Самые эффективные методы защиты — те, которые невидимы для пользователя и не требуют от него никаких действий. Пассивные методы обнаружения работают в фоновом режиме, собирая и анализируя данные о каждом посетителе, чтобы выявить тонкие различия между поведением человека и машины. Эти технологии лежат в основе современных антибот-систем.
Цифровые “отпечатки” (Fingerprinting)
Концепция “цифрового отпечатка” (fingerprinting) заключается в сборе уникальной комбинации технических характеристик браузера и устройства пользователя. Эта комбинация настолько уникальна, что позволяет с высокой точностью идентифицировать одного и того же пользователя при повторных визитах, даже если он удалил cookie или использует режим инкогнито.39
В “отпечаток” могут входить десятки параметров:
- Строка User-Agent (тип и версия браузера, ОС).
- IP-адрес и данные провайдера.
- Разрешение экрана и глубина цвета.
- Установленные в системе шрифты.
- Список активных плагинов браузера.
- Языковые настройки и часовой пояс.
- Технические параметры аудио- и видеокарты.
Боты, особенно простые, часто имеют неполные или аномальные “отпечатки”. Например, у них может отсутствовать список плагинов или шрифтов, или их User-Agent может не соответствовать другим характеристикам. Продвинутые боты пытаются подделывать эти параметры, но создать полностью консистентный и уникальный отпечаток для каждого запроса — сложная задача. Системы защиты анализируют эти отпечатки и могут блокировать посетителей с подозрительными или часто повторяющимися комбинациями.
Canvas Fingerprinting
Это один из самых мощных и надежных методов фингерпринтинга. Он использует элемент <canvas> из HTML5, который предназначен для отрисовки графики в браузере. Технология работает следующим образом 40:
- С помощью JavaScript на странице создается невидимый для пользователя элемент <canvas>.
- Браузеру дается команда отрисовать на этом холсте определенное изображение или строку текста со специфическими параметрами (шрифт, цвет, тени).
- Из-за мельчайших различий в реализации графических подсистем на уровне операционной системы, драйверов видеокарты и самого браузера, итоговое изображение у каждого пользователя будет немного отличаться на уровне отдельных пикселей.
- Полученное изображение преобразуется в строку данных (например, через base64), от которой затем вычисляется хэш-сумма.
- Этот хэш и является уникальным и очень стабильным “отпечатком” Canvas, который сложно подделать.
Боты, работающие на headless-браузерах, часто либо вообще не могут корректно отрисовать canvas, либо выдают одинаковый результат для всех своих экземпляров, что позволяет их легко идентифицировать.41
Важно отметить, что технологии фингерпринтинга имеют двойное назначение. Они эффективно используются для защиты от мошенничества, но также применяются в рекламных сетях для отслеживания пользователей, что создает определенные юридические риски, особенно в контексте законодательства о защите персональных данных, такого как GDPR.39
Поведенческая биометрия
Если фингерпринтинг отвечает на вопрос “кто ты?”, то поведенческая биометрия отвечает на вопрос “как ты себя ведешь?”. Этот метод основан на том, что каждый человек взаимодействует с компьютером или смартфоном уникальным образом. Системы защиты анализируют этот “цифровой почерк”, отслеживая микро-паттерны поведения.43
Анализируются следующие параметры:
- Динамика движения мыши: Траектория, скорость, ускорение, количество пауз. У человека движения мыши плавные, слегка изогнутые, в то время как у простого бота они могут быть идеально прямыми и мгновенными.
- Ритм набора текста (Keystroke dynamics): Скорость печати, время удержания клавиш, паузы между нажатиями. Эти параметры формируют уникальный ритмический рисунок.
- Взаимодействие с сенсорным экраном: Сила нажатия, площадь касания, угол наклона устройства (данные с акселерометра и гироскопа).
- Особенности скроллинга и навигации: Как пользователь прокручивает страницу, на какие элементы наводит курсор, прежде чем кликнуть.
Преимущество поведенческой биометрии в том, что эти характеристики крайне сложно подделать. Бот может скопировать статический отпечаток браузера, но имитировать естественное, хаотичное и уникальное поведение живого человека — на порядок более сложная задача. Современные системы, используемые, например, в банковской сфере, способны отличить человека от бота всего за несколько секунд по первым же его действиям на странице.45
Ловушки “Honeypot” (“Горшочек с медом”)
Honeypot — это элегантная и простая в реализации техника, основанная на обмане. Идея заключается в создании приманки для ботов, которую не должен заметить и использовать обычный человек.46
Самый распространенный пример — скрытое поле в форме. Реализация выглядит так:
- В HTML-код формы (например, контактной формы или формы комментариев) добавляется дополнительное поле ввода (например, <input type=”text” name=”comment”>).
- Это поле скрывается от глаз пользователя с помощью CSS. Самый надежный способ — не display: none; (некоторые боты научились это определять), а позиционирование элемента далеко за пределами видимой области экрана.
- Человек, заполняя форму, не видит это поле и, соответственно, оставляет его пустым.
- Простой спам-бот, который не анализирует CSS, а просто ищет в HTML все поля <input> и пытается их заполнить, впишет в это скрытое поле какие-то данные.
- На сервере, при обработке формы, добавляется простая проверка: если скрытое поле ($_POST[‘comment’]) не пустое, значит, форму отправил бот. Такой запрос можно молча отклонить или пометить как спам.
Пример реализации:
- HTML/CSS:
HTML
<style>
.honeypot-field {
position: absolute;
left: -9999px;
top: -9999px;
}
</style>
<form action="/submit.php" method="post">
<input type="text" name="name" placeholder="Ваше имя">
<input type="email" name="email" placeholder="Ваш Email">
<input type="text" name="comment" class="honeypot-field" autocomplete="off" tabindex="-1">
<button type="submit">Отправить</button>
</form> - PHP (проверка на сервере):
PHP<?php
if (!empty($_POST['comment'])) {
// Это бот, запрос отклоняется. Можно ничего не выводить.
http_response_code(400);
exit();
}
// Если поле пустое, продолжаем обработку формы для реального пользователя
//...
?>
- Python (для фреймворка Flask):
Pythonfrom flask import Flask, request, abort
app = Flask(__name__)
@app.route('/submit', methods=)
def submit_form():
if request.form.get('comment'):
# Это бот, возвращаем ошибку
abort(400, description="Spam detected")
# Продолжаем обработку
#...
return "Form submitted successfully!"
Техника Honeypot невидима для пользователей, не ухудшает UX и легко реализуется. Она эффективна против простых и средне-сложных ботов. Существуют и более сложные реализации Honeypot, которые могут имитировать уязвимые сервисы или целые системы для изучения тактик атакующих. Проекты, такие как OWASP Honeypot Project, и специализированные библиотеки на Python предоставляют инструменты для создания таких продвинутых ловушек.48
Глава 6: Гонка вооружений: как современные боты обходят защиту
Пока разработчики систем защиты создают все более изощренные барьеры, создатели ботов не сидят сложа руки. Современный ландшафт угроз — это постоянная гонка вооружений, в которой боты эволюционируют, чтобы как можно точнее имитировать поведение человека и обходить защиту.
Безголовые (Headless) браузеры и фреймворки автоматизации
Ключевым технологическим скачком, который кардинально изменил мир ботов, стало появление “безголовых” браузеров. Headless-браузер — это полноценный веб-браузер, такой как Google Chrome или Mozilla Firefox, но работающий без графического пользовательского интерфейса (GUI). Он управляется не кликами мыши, а программно, через код или команды в терминале.54
Для управления такими браузерами были созданы мощные фреймворки автоматизации:
- Selenium: Изначально созданный для автоматизированного тестирования веб-приложений, Selenium стал де-факто стандартом для создания ботов. Он позволяет писать скрипты на разных языках (Python, Java, C#) для управления браузером, имитируя любые действия пользователя: клики, ввод текста, скроллинг, выполнение JavaScript.54
- Puppeteer: Это библиотека для Node.js, разработанная командой Google Chrome. Она предоставляет высокоуровневый API для управления Chrome или Chromium в headless-режиме и является чрезвычайно популярным инструментом для веб-скрейпинга и автоматизации.56
- Playwright: Разработанный Microsoft, этот фреймворк похож на Puppeteer, но поддерживает управление не только Chromium, но и Firefox, и WebKit (движок Safari), что делает его еще более гибким инструментом для создания ботов.54
Появление headless-браузеров стерло грань между ботом и человеком на техническом уровне. Раньше ботов можно было легко обнаружить, так как они были простыми HTTP-клиентами, не способными выполнять JavaScript. Защита могла просто потребовать от клиента выполнить небольшой JS-скрипт, и если он этого не делал — заблокировать его. Теперь же боты используют тот же самый движок рендеринга (Blink в Chrome, Gecko в Firefox), что и реальные пользователи. Они полностью обрабатывают DOM-дерево страницы, исполняют все скрипты, отправляют AJAX-запросы и могут делать все то же самое, что и обычный браузер. Это сделало примитивные методы защиты, основанные на проверке поддержки JavaScript, практически бесполезными.
В ответ на это защитные системы были вынуждены эволюционировать. Вместо вопроса “Может ли клиент выполнить JS?” они начали задавать вопрос “КАК он его выполняет?”. Это привело к расцвету методов поведенческого анализа и фингерпринтинга, описанных в предыдущей главе. Стандартные headless-браузеры, запущенные “из коробки”, все еще оставляют определенные следы, по которым их можно обнаружить (например, переменная navigator.webdriver в JavaScript имеет значение true, что является прямым указанием на автоматизацию).
Продвинутые техники обхода
Создатели ботов быстро адаптировались к новым методам защиты и разработали инструменты для маскировки своих творений.
- Специализированные инструменты для маскировки: Появились модифицированные версии фреймворков, такие как Puppeteer Stealth и Undetected ChromeDriver. Эти инструменты специально разработаны для того, чтобы скрывать признаки автоматизации. Они подменяют значения переменных вроде navigator.webdriver, удаляют специфические для автоматизации свойства из объектов JavaScript и имитируют другие характеристики обычного браузера, чтобы пройти проверки систем защиты.55 Существуют и коммерческие антидетект-браузеры (например, Kameleo), которые идут еще дальше, предоставляя комплексные решения для подмены цифровых отпечатков и обхода самых сложных систем защиты.55
- Ротация IP-адресов через прокси-сети: Чтобы обойти блокировку по IP, боты используют прокси-серверы. Самыми эффективными являются резидентные и мобильные прокси. Резидентные прокси используют IP-адреса реальных домашних интернет-провайдеров, а мобильные — IP-адреса сотовых операторов. Для систем защиты такие запросы выглядят как трафик от обычных пользователей, сидящих дома или использующих мобильный интернет. Это делает блокировку по IP не только бесполезной, но и опасной, так как можно заблокировать легитимных пользователей.
- Сервисы по распознаванию CAPTCHA: Даже самые сложные CAPTCHA, требующие распознавания изображений, сегодня не являются непреодолимым препятствием. Существуют так называемые “фермы CAPTCHA” — сервисы, где тысячи низкооплачиваемых работников (или, все чаще, нейросети) в реальном времени решают капчи. Бот, столкнувшись с CAPTCHA на сайте, отправляет картинку через API на такой сервис, получает в ответ правильное решение и вставляет его в форму. Стоимость решения одной капчи может составлять доли цента, что делает этот метод экономически выгодным для массовых атак.33
Эта непрекращающаяся гонка вооружений означает, что статичные, основанные на жестких правилах системы защиты обречены на провал. Эффективная оборона должна быть динамической, адаптивной и способной обучаться на лету, чтобы противостоять постоянно меняющимся тактикам атакующих.
Глава 7: Профессиональный арсенал: комплексные решения для защиты
Когда базовых мер и ручной настройки становится недостаточно, а атаки ботов приобретают систематический и изощренный характер, на помощь приходят профессиональные инструменты и комплексные решения. Они объединяют множество методов обнаружения и реагирования в единую, управляемую систему.
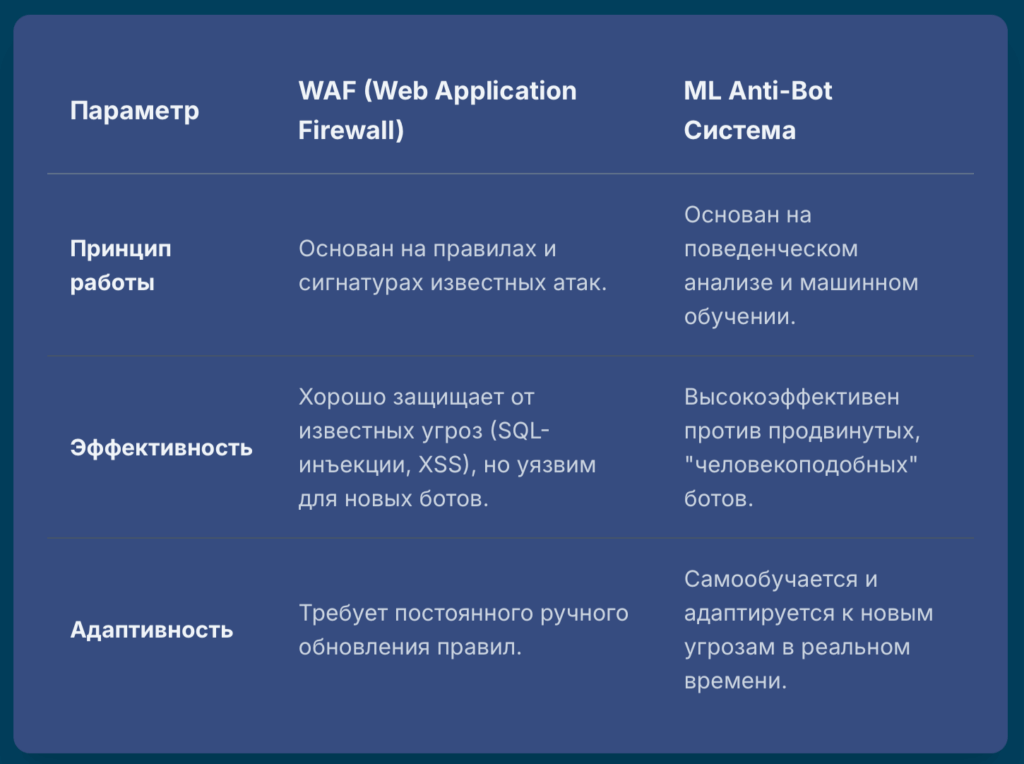
Web Application Firewall (WAF)
Web Application Firewall (WAF) — это специализированный межсетевой экран, который работает на уровне приложений (L7 модели OSI). Его основная задача — анализировать HTTP-трафик между пользователями и веб-приложением и блокировать запросы, содержащие признаки известных атак.59 В отличие от обычного сетевого экрана, который оперирует IP-адресами и портами, WAF “понимает” протокол HTTP и может инспектировать содержимое запросов и ответов.
Роль и функции WAF:
- Защита от известных уязвимостей: WAF эффективно блокирует распространенные векторы атак, такие как SQL-инъекции, межсайтовый скриптинг (XSS), подделка межсайтовых запросов (CSRF) и другие угрозы из списка OWASP Top 10.61
- Контроль доступа: WAF позволяет настраивать гибкие правила доступа на основе IP-адресов (включая геоблокировку), HTTP-заголовков, типов запросов и других параметров.59
- Виртуальный патчинг: Если в вашем веб-приложении обнаружена уязвимость, а разработчики еще не выпустили исправление, WAF может временно закрыть эту “дыру” с помощью специального правила, блокирующего эксплуатацию уязвимости.
WAF как защита от ботов:
Многие современные WAF, особенно облачные решения от таких провайдеров, как Cloudflare, AWS и Azure, включают в себя базовые модули для защиты от ботов. Они могут 59:
- Блокировать запросы с IP-адресов, находящихся в глобальных репутационных “черных списках”.
- Идентифицировать и блокировать известных вредоносных ботов и сканеры по их сигнатурам (например, по уникальным строкам User-Agent).
- Применять правила Rate Limiting для предотвращения брутфорс-атак и агрессивного парсинга.
Однако важно понимать ограничения традиционных WAF. Они, как правило, работают на основе сигнатур и статических правил. Это делает их эффективными против известных, “шумных” ботов, но практически бесполезными против продвинутых угроз. Изощренный бот, работающий через headless-браузер с “чистого” резидентного прокси и имитирующий поведение человека, не нарушит ни одного формального правила и легко пройдет через стандартный WAF.65
Сила искусственного интеллекта: специализированные антибот-системы
Для борьбы с продвинутыми ботами были созданы специализированные решения (Anti-Bot Solutions), которые ставят во главу угла не статические правила, а поведенческий анализ и машинное обучение (ML). Ведущие игроки на этом рынке, такие как Akamai, DataDome и Cloudflare (с их продуктом Bot Management), предлагают многоуровневый подход к обнаружению.65
Эти системы в реальном времени собирают и анализируют сотни сигналов для каждого запроса, комбинируя все ранее рассмотренные нами методы:
- Сигнатурный анализ: Проверка по постоянно обновляемым базам данных известных вредоносных IP-адресов, прокси-серверов и отпечатков ботов.
- Технический анализ: Глубокий фингерпринтинг браузера, устройства и TLS/HTTP-соединения для выявления аномалий и признаков подделки.
- Поведенческий анализ: Анализ биометрических данных — траектории движения мыши, ритма клавиатурного ввода, паттернов навигации по сайту.
- Статистический анализ и обнаружение аномалий: Система строит модель “нормального” поведения для сайта в целом и для каждого пользователя в отдельности. Любые резкие отклонения от этой модели (например, всплеск регистраций из одной подсети или аномальное соотношение просмотров и добавлений в корзину) помечаются как подозрительные.65
Все эти данные поступают в модель машинного обучения, которая вычисляет для каждого запроса “оценку вероятности бота”. На основе этой оценки система принимает решение: пропустить запрос, заблокировать его или выдать дополнительную проверку (challenge), которая будет невидима для человека, но сложна для бота (например, криптографическая задача, требующая ресурсов CPU).67
Ключевое преимущество такого подхода — адаптивность. Модели машинного обучения постоянно дообучаются на новых данных, поступающих со всех защищаемых сайтов. Это позволяет им выявлять новые, ранее неизвестные паттерны атак и адаптироваться к меняющимся тактикам ботов в режиме реального времени. В отличие от WAF, который нужно постоянно обновлять новыми правилами, ML-система эволюционирует сама, обеспечивая проактивную защиту.65
Специализированные сервисы: пример clickfraud.ru
Помимо комплексных систем, защищающих от всех видов ботов, существуют и узкоспециализированные сервисы, нацеленные на решение конкретных бизнес-задач. Ярким примером является сервис clickfraud.ru, который фокусируется на одной из самых болезненных проблем — защите рекламного бюджета от скликивания (кликфрода).71
Механизм работы:
Сервис работает в тесной интеграции с сайтом и рекламными системами (Яндекс.Директ, Google Ads), создавая замкнутый контур защиты 15:
- Сбор данных: На все страницы защищаемого сайта устанавливается специальный счетчик (похожий на счетчик веб-аналитики). Он собирает подробную информацию о каждом визите, который пришел с платной рекламы.15
- Анализ: Собранные данные в реальном времени анализируются алгоритмами машинного обучения. Система оценивает десятки поведенческих факторов: время, проведенное на сайте, количество просмотренных страниц, движения мыши, заполнение форм и т.д. На основе этого анализа каждому визиту присваивается оценка “человек” или “бот”.15
- Блокировка: Если система идентифицирует посетителя как бота, его IP-адрес автоматически, через API, добавляется в список исключений (минус-площадок или заблокированных IP) в соответствующей рекламной кампании в Яндекс.Директ или Google Ads.
- Результат: В будущем реклама просто не будет показываться этому боту, что предотвращает бесполезные траты бюджета.
Помимо основной функции, сервис предлагает и дополнительные возможности, такие как собственная простая в использовании CAPTCHA для защиты форм и возможность блокировать ботов не только на уровне рекламных кампаний, но и на самом сайте.37 Отзывы клиентов часто отмечают значительное (до 40%) снижение расходов на рекламу после подключения сервиса при сохранении количества реальных заказов.73
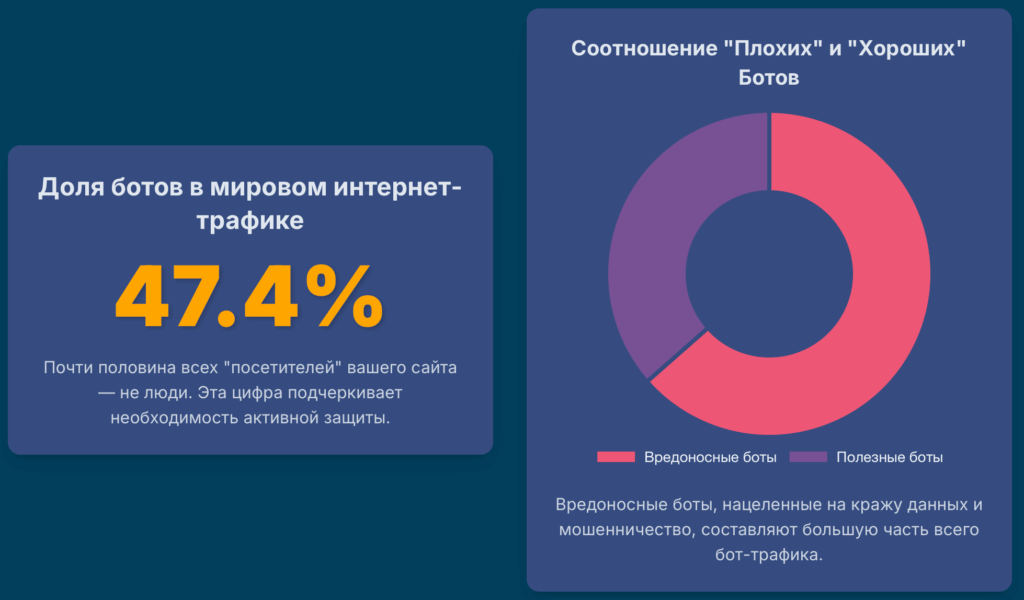
Таблица 3: Сводная таблица методов защиты от ботов
Чтобы систематизировать все рассмотренные подходы, представим их в виде сводной таблицы, которая поможет оценить их сильные и слабые стороны.
| Метод защиты | Принцип действия | Эффективность против простых ботов | Эффективность против продвинутых ботов | Сложность реализации | Влияние на UX и производительность |
| robots.txt | Инструкция для “послушных” краулеров | Низкая | Нулевая | Очень низкая | Нет |
| Блокировка IP/UA | Прямая блокировка по известным адресам/сигнатурам | Средняя | Низкая | Низкая | Нет (риск ложных срабатываний) |
| Rate Limiting | Ограничение частоты запросов с одного IP | Высокая | Средняя | Средняя | Низкое |
| CAPTCHA | Интерактивный тест “человек-бот” | Высокая | Низкая/Средняя (в зависимости от типа) | Низкая/Средняя | Высокое (v2) / Минимальное (v3) |
| Fingerprinting | Идентификация по уникальным параметрам браузера/устройства | Высокая | Средняя | Высокая | Низкое |
| WAF | Сигнатурный анализ HTTP-трафика | Высокая | Низкая | Средняя | Низкое |
| ML Anti-Bot | Комплексный поведенческий и технический анализ | Очень высокая | Высокая | Низкая (как сервис) | Минимальное |
Глава 8: Поле битвы — закон: скрейпинг, данные и судебная практика
Борьба с ботами ведется не только на техническом, но и на юридическом фронте. Вопросы о том, законно ли собирать общедоступные данные, какие данные считаются персональными и где проходит грань между сбором информации и несанкционированным доступом, стали предметом громких судебных разбирательств, формирующих правила игры для всей индустрии.
Прецедент hiQ Labs vs. LinkedIn: можно ли парсить публичные данные?
Это дело стало одним из самых знаковых в истории веб-скрейпинга и прошло несколько инстанций, включая Верховный суд США.
Суть дела:
Компания hiQ Labs занималась “кадровой аналитикой”: она парсила (собирала) данные из публичных профилей пользователей LinkedIn (имя, должность, опыт работы) и на их основе создавала для своих клиентов-работодателей отчеты о том, какие сотрудники могут скоро уволиться или каких специалистов ищут конкуренты. В 2017 году LinkedIn отправил hiQ официальное требование прекратить эту деятельность (cease-and-desist letter) и заблокировал доступ их ботам, ссылаясь на нарушение своего Пользовательского соглашения. В ответ hiQ подала в суд на LinkedIn, требуя предоставить ей доступ к публичным данным.74
Ключевые решения и их интерпретация:
Изначально суд встал на сторону hiQ. Девятый окружной апелляционный суд США постановил, что сбор данных, которые являются общедоступными и для доступа к которым не требуется авторизация (ввод логина и пароля), не является нарушением американского закона о компьютерном мошенничестве и злоупотреблениях (CFAA). Суд провел аналогию: CFAA наказывает за “взлом”, подобный проникновению в чужой дом. Но нельзя “взломать” то, что и так открыто для всех, как, например, витрина магазина. Это решение было воспринято как огромная победа для всей индустрии сбора данных.74
Однако дьявол, как всегда, оказался в деталях. Хотя уголовный закон (CFAA) был признан неприменимым, оставался вопрос о гражданско-правовых отношениях. Финальное урегулирование дела в конце 2022 года произошло уже не в пользу hiQ. Компания согласилась на постоянный судебный запрет на парсинг LinkedIn и выплату компенсации, фактически признав нарушение Пользовательского соглашения (User Agreement).78
Это создает важнейший прецедент. Легальность скрейпинга зависит не только от публичности данных, но и от того, принимал ли скрейпер (или его сотрудники/подрядчики) условия использования сайта. Если в Пользовательском соглашении прямо запрещен автоматизированный сбор данных, а пользователь (или бот, создавший фейковый аккаунт) поставил галочку “Согласен”, то этот запрет становится юридически обязывающим договором. И хотя за это не последует уголовного преследования по CFAA, компания-владелец сайта может подать гражданский иск о нарушении контракта и взыскать ущерб. Это ставит под удар бизнес-модели многих компаний, занимающихся скрейпингом, так как доказать, что ни один из их процессов никогда не “соглашался” с условиями сайта, практически невозможно.
Исторический контекст: Southwest Airlines vs. FareChase
Борьба с парсингом имеет долгую историю. Еще в 2003-2004 годах авиакомпании American Airlines и Southwest Airlines подали в суд на компанию FareChase. FareChase создавала ПО, которое собирало с сайтов авиакомпаний информацию о рейсах и ценах для туристических агентств. Суды тогда также встали на сторону авиакомпаний, вынеся судебные запреты на скрейпинг. Решения основывались на нарушении условий использования сайтов и на доктрине “trespass to chattels” (нарушение владения движимым имуществом), где серверам авиакомпании был нанесен ущерб из-за чрезмерной нагрузки от ботов.80 Эти ранние дела заложили основу для юридической защиты от нежелательного парсинга.
Юридические тонкости: GDPR и Fingerprinting
С введением в Европе Общего регламента по защите данных (GDPR) возник еще один сложный юридический аспект.
Проблема:
Технологии фингерпринтинга, которые собирают уникальные характеристики браузера и устройства, попадают в “серую зону” законодательства. Сам по себе “цифровой отпечаток” может не быть персональными данными. Однако в комбинации с IP-адресом и другими идентификаторами он позволяет с очень высокой вероятностью выделить конкретного человека из общей массы и отслеживать его действия. В этом случае, согласно широкой трактовке GDPR, такой “отпечаток” может быть признан персональными данными.39
Требования GDPR:
Если “отпечаток” признается персональными данными, то для его сбора и обработки требуется законное основание. Чаще всего таким основанием является явное и информированное согласие пользователя. Это означает, что владелец сайта должен:
- Прозрачно информировать пользователя в своей Политике конфиденциальности о том, что он использует технологии фингерпринтинга.
- Четко объяснить, для каких целей собираются эти данные (например, “для обеспечения безопасности и защиты от мошенничества”).
- Получить от пользователя активное согласие на такую обработку (например, через баннер cookie-согласия).39
Это создает фундаментальный конфликт интересов. С одной стороны, фингерпринтинг — мощный и необходимый инструмент для защиты от ботов. С другой стороны, его использование сопряжено с выполнением строгих юридических требований. Владельцам сайтов, работающим с аудиторией из Европейского союза, необходимо тщательно прорабатывать юридическую документацию и механизмы получения согласия, чтобы не нарушить GDPR и не столкнуться с многомиллионными штрафами.
Глава 9: Реальный пример: защита интернет-магазина от ботов и кликфрода
Теория важна, но лучше всего принципы защиты от ботов иллюстрирует практический пример. Рассмотрим кейс, основанный на реальных проблемах, с которыми сталкиваются многие компании в сфере электронной коммерции.
Описание проблемы (Кейс)
Клиент: Интернет-магазин потребительской электроники, работающий в высококонкурентной нише в крупном городе. Активно использует контекстную рекламу в Яндекс.Директ и Google Ads для привлечения клиентов.
Симптомы:
В течение нескольких месяцев владелец магазина столкнулся с рядом тревожных проблем:
- Стремительное расходование рекламного бюджета: Бюджет, выделенный на день в рекламных кампаниях, “сгорал” за первые 2-3 часа после утреннего запуска. При этом анализ отчетов в рекламных кабинетах показывал огромное количество кликов, но количество реальных заказов с рекламы не росло. Углубленный анализ выявил, что значительная часть кликов поступала из нецелевых и подозрительных регионов, в частности, из Китая, хотя таргетинг был настроен на один город.86 Это классический признак кликфрода.
- “Призрачные” товары: Во время старта продаж популярных и дефицитных товаров (например, новых моделей видеокарт или игровых консолей) весь запас раскупался в течение нескольких минут. Однако позже эти же товары появлялись на местных досках объявлений и в Telegram-каналах по завышенной цене. Это указывало на работу ботов-перекупщиков (скальперов), которые автоматизировали процесс покупки.
- Искаженная аналитика: Системы веб-аналитики показывали странные паттерны. Наблюдался высокий общий трафик, но при сегментации по некоторым источникам или географическим регионам показатель отказов приближался к 100%, а среднее время на сайте было равно нулю. Это делало невозможным адекватную оценку эффективности маркетинговых каналов.
Пошаговая стратегия защиты
Для решения этих проблем была разработана и внедрена комплексная, эшелонированная стратегия защиты.
- Шаг 1: Диагностика и базовая гигиена.
Первым делом был проведен глубокий анализ логов веб-сервера NGINX и данных из Яндекс.Метрики и Google Analytics. Это позволило подтвердить наличие аномальной активности, выявить диапазоны IP-адресов и строки User-Agent, генерирующие мусорный трафик. Наиболее “шумные” IP-подсети были временно заблокированы на уровне сервера. - Шаг 2: Внедрение Rate Limiting.
Для борьбы с парсерами и ботами-перекупщиками в конфигурацию NGINX были добавлены правила ограничения частоты запросов. Особое внимание было уделено страницам каталога, карточкам товаров и API-эндпоинтам, отвечающим за проверку наличия и добавление в корзину. Был установлен умеренный лимит (например, 10 запросов в секунду с одного IP) с параметрами burst и nodelay, чтобы не мешать реальным пользователям, но замедлить автоматизированные скрипты. - Шаг 3: Защита ключевых форм.
На формы регистрации, входа в личный кабинет и, что самое важное, на страницу оформления заказа была установлена невидимая reCAPTCHA v3. Изначально она была запущена в пассивном режиме для сбора данных. Через неделю, после анализа оценок в Admin Console, была настроена активная логика: запросы с оценкой ниже 0.4 помечались как высокорискованные, и для завершения заказа таким пользователям предлагалось пройти дополнительную проверку (например, решить простую CAPTCHA от сервиса clickfraud.ru, который был подключен на следующем шаге). - Шаг 4: Специализированная защита от кликфрода.
Для решения главной проблемы — слива рекламного бюджета — был подключен сервис clickfraud.ru. Процесс интеграции был простым и занял около часа 15:
- Регистрация в личном кабинете сервиса.
- Добавление домена интернет-магазина.
- Предоставление сервису гостевого доступа к аккаунтам Яндекс.Метрики, Яндекс.Директа и Google Ads через безопасную авторизацию.
- Генерация уникального JavaScript-счетчика и его установка на все страницы сайта через Google Tag Manager.
- Шаг 5: Мониторинг и корректировка.
После внедрения всех систем был запущен процесс постоянного мониторинга. Ежедневные отчеты в clickfraud.ru показывали, сколько ботовых кликов было обнаружено и сколько IP-адресов было автоматически заблокировано в рекламных кампаниях. Статистика в консоли reCAPTCHA позволила более точно настроить пороговые значения для блокировки.
Результаты
Результаты комплексного подхода проявились уже в первый месяц:
- Экономия рекламного бюджета: Расходы на контекстную рекламу снизились примерно на 35%. Рекламный бюджет перестал “сгорать” в первые часы, показы распределились равномерно в течение дня, а стоимость привлечения реального заказа (CPO) значительно уменьшилась.73
- Очистка аналитики: “Мусорный” трафик был отфильтрован. Показатели отказов и время на сайте в отчетах веб-аналитики пришли в норму. Маркетологи смогли получать достоверные данные и принимать взвешенные решения об оптимизации кампаний.
- Стабилизация работы и справедливые продажи: Нагрузка на сервер снизилась, что положительно сказалось на скорости загрузки сайта для реальных покупателей. Во время следующих “горячих” распродаж дефицитные товары были доступны для покупки обычным клиентам, а не только ботам-перекупщикам.
Этот кейс наглядно демонстрирует, что эффективная защита от ботов — это не установка одного инструмента, а построение многоуровневой системы, где каждый элемент решает свою задачу.
Заключение: построение эшелонированной обороны
В мире кибербезопасности не существует “серебряной пули” — одного универсального решения, способного защитить от всех угроз. Борьба с ботами не является исключением. Как показало это исследование, современный ландшафт угроз слишком сложен и динамичен, чтобы полагаться на единственный метод защиты. Эффективная стратегия — это всегда эшелонированная оборона, многоуровневая система, где каждый последующий уровень защиты прикрывает слабые места предыдущего и нацелен на противодействие все более изощренным атакам.13
Построение такой обороны можно представить в виде нескольких последовательных рубежей:
- Первый эшелон (Базовый уровень): Это фундамент вашей безопасности. Сюда входит грамотная настройка веб-сервера с обязательным внедрением Rate Limiting. Этот простой, но мощный инструмент отсекает самый примитивный, но массовый вредоносный трафик — агрессивных парсеров, сканеры уязвимостей и простые брутфорс-атаки.
- Второй эшелон (Интерактивная защита): Этот рубеж защищает самые уязвимые точки взаимодействия с пользователем — формы регистрации, входа, отправки комментариев и оформления заказов. Здесь ключевую роль играет умное использование современных CAPTCHA. Выбор в пользу невидимой reCAPTCHA v3 позволяет обеспечить высокий уровень защиты, не создавая препятствий для легитимных пользователей и не ухудшая конверсию.
- Третий эшелон (Пассивный анализ): Этот уровень работает незаметно, постоянно анализируя поведение посетителей. Внедрение пассивных проверок, таких как Honeypots (ловушки для ботов) и базовый Fingerprinting, позволяет выявлять автоматизированные системы, которые успешно обошли первые два рубежа.
- Четвертый эшелон (Профессиональная защита): Для критически важных бизнес-приложений, сайтов с высоким трафиком или тех, кто несет серьезные финансовые потери от ботов (например, от кликфрода), необходим переход на профессиональные инструменты. Это может быть либо специализированный сервис (такой как clickfraud.ru для защиты рекламы), либо комплексное ML-решение (от Cloudflare, Akamai, DataDome), которое объединяет все возможные методы детекции и использует мощь машинного обучения для адаптации к новым угрозам в реальном времени.
Путь к надежной защите от ботов — это не разовый проект, а непрерывный процесс. Он начинается с аудита текущего трафика, выявления аномалий и последовательного внедрения описанных методов, начиная с самых простых и доступных. В условиях, когда боты становятся все умнее, а их активность — все более разрушительной, инвестиции в построение эшелонированной обороны — это не просто техническая необходимость, а стратегическое вложение в стабильность, прибыльность и безопасность вашего онлайн-бизнеса.
Мини-FAQ (Часто задаваемые вопросы)
- Достаточно ли одного robots.txt для защиты от вредоносных ботов?
Нет, абсолютно недостаточно. Файл robots.txt — это лишь рекомендация для “хороших”, законопослушных ботов (в основном, поисковых систем). Вредоносные боты, созданные для спама, парсинга или атак, полностью его игнорируют. Он не является инструментом безопасности.10 - Не повредит ли CAPTCHA моему SEO?
Может повредить, если она реализована неправильно. Главное правило: CAPTCHA не должна блокировать доступ к контенту страницы для поисковых роботов. Она должна защищать только конкретные действия, такие как отправка формы или нажатие кнопки. Если контент доступен для сканирования, а CAPTCHA появляется только в момент взаимодействия, негативного влияния на SEO не будет.38 - Можно ли случайно заблокировать полезных ботов, например, от Google?
Да, такой риск существует, особенно при агрессивной настройке Rate Limiting или WAF. Чтобы этого избежать, необходимо создавать “белые списки” для известных и доверенных ботов. Крупные поисковые системы, такие как Google, публикуют официальные списки своих IP-адресов, которые можно и нужно добавлять в исключения.16 - В чем разница между WAF и специализированным антибот-сервисом?
Основное различие в подходе. Традиционный WAF (Web Application Firewall) в основном работает на основе сигнатур и правил, защищая от известных типов атак (SQL-инъекции, XSS). Специализированный антибот-сервис использует машинное обучение и глубокий поведенческий анализ (движения мыши, ритм печати) для выявления продвинутых ботов, которые технически не нарушают никаких правил, но ведут себя не как люди.59 - reCAPTCHA v3 кажется сложной. Стоит ли ее использовать вместо v2?
Это зависит от ваших целей. Если вам нужна максимальная безопасность без ущерба для пользовательского опыта, и вы готовы потратить время на настройку серверной логики и анализ пороговых значений, то reCAPTCHA v3 — лучший выбор. Для простых сайтов с невысокими требованиями к безопасности (например, блог с формой комментариев) более простая в реализации reCAPTCHA v2 может быть достаточным решением.28 - Насколько эффективна блокировка по IP?
Блокировка по IP-адресу эффективна только против единичных, примитивных атак или для блокировки конкретного назойливого пользователя. Против современных распределенных ботнетов, которые используют тысячи и миллионы разных IP-адресов (особенно резидентных прокси), этот метод абсолютно неэффективен.15 - Что такое кликфрод и как сервисы вроде clickfraud.ru с ним борются?
Кликфрод (или скликивание) — это мошеннические клики по платной рекламе, совершаемые ботами или недобросовестными конкурентами с целью истощить ваш рекламный бюджет. Сервисы, подобные clickfraud.ru, устанавливают на сайт свой код, анализируют поведение каждого посетителя, пришедшего с рекламы, и с помощью алгоритмов машинного обучения выявляют ботов. IP-адреса этих ботов автоматически блокируются в настройках ваших рекламных кампаний, предотвращая дальнейшие показы им рекламы и экономя ваши деньги.15
Источники
- Как проверить трафик сайта на ботов: 7 способов выявления и борьбы – Monodigital, дата последнего обращения: августа 19, 2025, https://monodigital.ru/seo/bot-trafik-na-sajte
- Вредоносные Боты. Их разновидности и защита от них. | Статьи Qlever KG, дата последнего обращения: августа 19, 2025, https://kg.qlever.asia/ru/interest/vredonosnye-boty-kakie-oni
- Что такое боты и чем они опасны, как защититься от ботов в интернете – PRO32, дата последнего обращения: августа 19, 2025, https://pro32.com/ru/article/chto-takoe-boty-i-chem-oni-opasny/
- История и развитие CAPTCHA – Habr, дата последнего обращения: августа 19, 2025, https://habr.com/ru/articles/853748/
- Нашествие ботов: как его опознать и что с ними делать – Texterra, дата последнего обращения: августа 19, 2025, https://texterra.ru/blog/nakrutka-botov-i-ee-posledstviya.html
- Что делать, если боты портят поведенческие факторы сайта – Компания seo.ru, дата последнего обращения: августа 19, 2025, https://seo.ru/blog/nakrutka-povedencheskih-faktorov-botami-kak-vyyavit-posledstviya-i-kak-zaschititsya/
- Вредоносные боты на сайте – как их обнаружить и заблокировать • Hostpro Wiki, дата последнего обращения: августа 19, 2025, https://hostpro.ua/wiki/security/how-to-detect-and-block-malicious-bots/
- О файлах robots.txt | Центр Google Поиска | Documentation, дата последнего обращения: августа 19, 2025, https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=ru
- Robots.txt – как пользоваться и каких ошибок избегать – WhitePress.com, дата последнего обращения: августа 19, 2025, https://www.whitepress.com/ru/baza-znaniy/430/robots-txt-kak-polzovatsya-i-kakikh-oshibok-sleduyet-izbegat-vo-vremya-sozdaniya
- Robots Txt что это правильный файл – настройка – Rush Analytics, дата последнего обращения: августа 19, 2025, https://www.rush-analytics.ru/blog/sozdanie-i-optimizaciya-robotstxt-kontroliruem-indeksaciyu-sayta
- Что такое robots.txt и зачем он нужен – ᐈ Around WEB, дата последнего обращения: августа 19, 2025, https://around-web.com/ru/chto-takoe-robots-txt-i-zachem-on-nuzhen
- дата последнего обращения: января 1, 1970, https://hostpro.ua/wiki/security/how-to-detect-and-block-malicious-bots
- ТОП 5 лучших антиботов для сайта: Рейтинг способов защиты от ботов – VC.ru, дата последнего обращения: августа 19, 2025, https://vc.ru/services/1493049-top-5-luchshih-antibotov-dlya-saita-reiting-sposobov-zashity-ot-botov
- База знаний – Защита от скликивания рекламы – Clickfraud, дата последнего обращения: августа 19, 2025, https://clickfraud.ru/help/
- Полный список IP-адресов Googlebot – Защита сайта от ДДОС и поведенческих ботов, без капчи через Cloudflare, дата последнего обращения: августа 19, 2025, https://antiddos24.ru/blog/polnyy-spisok-ip-adresov-googlebot
- NGINX Rate Limiting: The Basics and 3 Code Examples | Solo.io, дата последнего обращения: августа 19, 2025, https://www.solo.io/topics/nginx/nginx-rate-limiting
- Rate Limiting with NGINX – NGINX Community Blog, дата последнего обращения: августа 19, 2025, https://blog.nginx.org/blog/rate-limiting-nginx
- Limiting Access to Proxied HTTP Resources | NGINX Documentation, дата последнего обращения: августа 19, 2025, https://docs.nginx.com/nginx/admin-guide/security-controls/controlling-access-proxied-http/
- Module ngx_http_limit_req_module – nginx, дата последнего обращения: августа 19, 2025,
- Protecting Against Bot Attacks Using Nginx Rate Limits | by Irtiza Hafiz – Medium, дата последнего обращения: августа 19, 2025, https://irtizahafiz.medium.com/protecting-against-bot-attacks-using-nginx-rate-limits-12872fcbaafd
- NGINX. Лимит частоты запросов. – Записки админа, дата последнего обращения: августа 19, 2025, https://sysadmin.pm/nginx-rate-limit/
- mod_ratelimit – Apache HTTP Server Version 2.4, дата последнего обращения: августа 19, 2025, https://httpd.apache.org/docs/current/mod/mod_ratelimit.html
- apache2 – How can I implement rate limiting with Apache? (requests …, дата последнего обращения: августа 19, 2025, https://stackoverflow.com/questions/131681/how-can-i-implement-rate-limiting-with-apache-requests-per-second
- Rate limiting with Apache and mod-security – John Leach, дата последнего обращения: августа 19, 2025, https://johnleach.co.uk/posts/2012/05/15/rate-limiting-with-apache-and-mod-security/
- URL-based request rate limiting in Apache – Server Fault, дата последнего обращения: августа 19, 2025, https://serverfault.com/questions/338869/url-based-request-rate-limiting-in-apache
- Что такое капча (captcha) и зачем она нужна – Компания seo.ru, дата последнего обращения: августа 19, 2025, https://seo.ru/seowiki/captcha/
- Представляем reCAPTCHA v3: новый инструмент защиты от роботов | Блог Центра Search Console, дата последнего обращения: августа 19, 2025, https://developers.google.com/search/blog/2018/10/introducing-recaptcha-v3-new-way-to?hl=ru
- reCAPTCHA – Google for Developers, дата последнего обращения: августа 19, 2025, https://developers.google.com/recaptcha
- reCAPTCHA v3 — скрытая защита вашего сайта от спама, дата последнего обращения: августа 19, 2025, https://megagroup.ru/post/recaptcha-v3-skrytaya-zashchita-vashego-sajta-ot-spama
- Google reCAPTCHA – Аспро, дата последнего обращения: августа 19, 2025, https://aspro.ru/docs/course/course38/lesson2539/
- reCAPTCHA v3 – Google for Developers, дата последнего обращения: августа 19, 2025, https://developers.google.com/recaptcha/docs/v3
- ReCAPTCHA v2 vs. v3: Efficient bot protection? [2024 Update] – DataDome, дата последнего обращения: августа 19, 2025, https://datadome.co/guides/captcha/recaptchav2-recaptchav3-efficient-bot-protection/
- Как установить reCAPTCHA V3?, дата последнего обращения: августа 19, 2025, https://bitoo.ru/blog/kak-ustanovit-recaptcha-v3
- Developer Guide | hCaptcha, дата последнего обращения: августа 19, 2025, https://docs.hcaptcha.com/
- Обзор hCaptcha – Techbear, дата последнего обращения: августа 19, 2025, https://techbear.ru/hcaptcha-review/
- Промо – Защита от скликивания рекламы – Clickfraud, дата последнего обращения: августа 19, 2025, https://clickfraud.ru/captcha/
- The Impact of reCAPTCHA on SEO – NoCode AI, дата последнего обращения: августа 19, 2025, https://www.nocodeai.jp/post/the-impact-of-recaptcha-on-seo
- Browser Fingerprinting and the GDPR • legalweb.io, дата последнего обращения: августа 19, 2025, https://legalweb.io/en/news-en/browser-fingerprinting-and-the-gdpr/
- Как Cloudflare определяет автоматический трафик: защита …, дата последнего обращения: августа 19, 2025, https://capmonster.cloud/ru/blog/Cloudflare/how-cloudflare-bot-challenge-and-turnstile-protect-web-traffic
- Как избежать утечки Canvas отпечатка – Блог AdsPower, дата последнего обращения: августа 19, 2025, https://blog.adspower-ru.com/docs/avoid-Canvas-fingerprinting
- 6 лучших решений и программ для защиты от ботов – Clickfraud, дата последнего обращения: августа 19, 2025, https://clickfraud.ru/6-luchshih-reshenij-i-programm-dlya-zashhity-ot-botov/
- Поведенческая биометрия – новый подход к безопасности онлайн банкинга – Softprom, дата последнего обращения: августа 19, 2025, https://softprom.com/ru/povedencheskaya-biometriya-novyiy-podhod-k-bezopasnosti-onlayn-bankinga
- Постороннего за компьютером выявляют за 8 минут, бота — за 2 секунды. Такая технология используется в «Ростелекоме» – iXBT.com, дата последнего обращения: августа 19, 2025, https://www.ixbt.com/news/2025/07/29/postoronnego-za-kompjuterom-vyjavljajut-za-8-minut-bota–za-2-sekundy-takaja-tehnologija-ispolzuetsja-v-rostelekome.html
- Как защитить форму с помощью honeypot поля – CleanTalk, дата последнего обращения: августа 19, 2025, https://cleantalk.org/ru/help/honeypot-field
- Невидимая защита веб-сайта от спам-ботов – технология Honeypot – IC Studio, дата последнего обращения: августа 19, 2025, https://icstudio.online/ru/post/nevidimaya-zashchita-veb-sajta-ot-spam-botov-tehnologiya-honeypot
- OWASP/Honeypot-Project – GitHub, дата последнего обращения: августа 19, 2025, https://github.com/OWASP/Honeypot-Project
- Building a Honeypot with Python. – Medium, дата последнего обращения: августа 19, 2025, https://medium.com/@info_82002/building-a-honeypot-with-python-1da5074819d1
- an awesome list of honeypot resources – GitHub, дата последнего обращения: августа 19, 2025, https://github.com/paralax/awesome-honeypots
- How to Build a Honeypot in Python: A Practical Guide to Security Deception, дата последнего обращения: августа 19, 2025, https://www.freecodecamp.org/news/build-a-honeypot-with-python/
- honeypots – PyPI, дата последнего обращения: августа 19, 2025, https://pypi.org/project/honeypots/
- Live Coding: Python Honeypot – YouTube, дата последнего обращения: августа 19, 2025, https://www.youtube.com/watch?v=77qj9o9pmek
- What is Headless Browser and Headless Browser Testing? | BrowserStack, дата последнего обращения: августа 19, 2025, https://www.browserstack.com/guide/what-is-headless-browser-testing
- The Best Headless Chrome Browser for Bypassing Anti-Bot Systems – Kameleo, дата последнего обращения: августа 19, 2025, https://kameleo.io/blog/the-best-headless-chrome-browser-for-bypassing-anti-bot-systems
- Getting Started with Headless Chrome | Blog, дата последнего обращения: августа 19, 2025, https://developer.chrome.com/blog/headless-chrome
- Web Scraping With a Headless Browser in Python [Selenium Tutorial] – ZenRows, дата последнего обращения: августа 19, 2025, https://www.zenrows.com/blog/headless-browser-python
- Selenium vs. Puppeteer: Which One to Use? – Medium, дата последнего обращения: августа 19, 2025, https://medium.com/@datajournal/selenium-vs-puppeteer-for-web-scraping-6bdef2f0a1c6
- Защита сайтов от ботов, атак и взлома (WAF) – Хостинг – База знаний – LITE.HOST, дата последнего обращения: августа 19, 2025, https://lite.host/faq/hosting/zashchita-saytov-ot-botov-atak-vzloma-waf
- WAF защита для вашего сайта и веб-сервисов – Гладиаторы ИБ, дата последнего обращения: августа 19, 2025, https://glabit.ru/services/waf-zashchita-dlya-saita-i-veb-servisov
- Облачная защита WAF | Сервисы безопасности – Cloudflare, дата последнего обращения: августа 19, 2025, https://www.cloudflare.com/ru-ru/application-services/products/waf/
- Модуль Web Application Firewall (WAF) – DDoS-Guard, дата последнего обращения: августа 19, 2025, https://ddos-guard.ru/waf
- Брандмауэр веб-приложений. Защита веб-API. AWS WAF. AWS – Amazon.com, дата последнего обращения: августа 19, 2025, https://aws.amazon.com/ru/waf/
- Настройка защиты от ботов для Брандмауэра веб-приложений Azure (WAF), дата последнего обращения: августа 19, 2025, https://learn.microsoft.com/ru-ru/azure/web-application-firewall/ag/bot-protection
- Multi-Layered AI: A New Requirement for Sophisticated Bot Protection – DataDome, дата последнего обращения: августа 19, 2025, https://datadome.co/bot-management-protection/multi-layered-machine-learning-a-new-requirement-for-sophisticated-bot-protection/
- Cloudflare Bot Management & Protection, дата последнего обращения: августа 19, 2025, https://www.cloudflare.com/application-services/products/bot-management/
- What Are Anti-Bot Tools? – Akamai, дата последнего обращения: августа 19, 2025, https://www.akamai.com/glossary/what-are-anti-bot-tools
- What is an anti-bot solution & how does it work? – DataDome, дата последнего обращения: августа 19, 2025, https://datadome.co/guides/bot-protection/anti-bot-solution/
- Monitoring machine learning models for bot detection – The Cloudflare Blog, дата последнего обращения: августа 19, 2025, https://blog.cloudflare.com/monitoring-machine-learning-models-for-bot-detection/
- Bot vs. Bot: Evading Machine Learning Malware Detection – Black Hat, дата последнего обращения: августа 19, 2025, https://www.blackhat.com/docs/us-17/thursday/us-17-Anderson-Bot-Vs-Bot-Evading-Machine-Learning-Malware-Detection.pdf
- ClickFraud – База знаний eLama, дата последнего обращения: августа 19, 2025, https://help.elama.ru/article/51531
- Как мы защищаем от скликивания – Clickfraud, дата последнего обращения: августа 19, 2025, https://clickfraud.ru/zashhita-ot-sklikivaniya/
- Clickfraud, дата последнего обращения: августа 19, 2025, https://clickfraud.ru/
- hiQ Labs v. LinkedIn – Wikipedia, дата последнего обращения: августа 19, 2025, https://en.wikipedia.org/wiki/HiQ_Labs_v._LinkedIn
- HiQ Labs, Inc. v. LinkedIn Corp. – Case Brief Summary for Law School Success – Studicata, дата последнего обращения: августа 19, 2025, https://studicata.com/case-briefs/case/hiq-labs-inc-v-linkedin-corp/
- HIQ LABS, INC. V. LINKEDIN CORPORATION, No. 17-16783 (9th Cir. 2022) – Justia Law, дата последнего обращения: августа 19, 2025, https://law.justia.com/cases/federal/appellate-courts/ca9/17-16783/17-16783-2022-04-18.html
- LinkedIn v. HiQ and the trans-Atlantic privacy divide – IAPP, дата последнего обращения: августа 19, 2025, https://iapp.org/news/a/linkedin-v-hiq-and-the-transatlantic-privacy-divide
- Web scraping case law: HiQ v. LinkedIn – Apify Blog, дата последнего обращения: августа 19, 2025, https://blog.apify.com/hiq-v-linkedin/
- hiQ v. LinkedIn Wrapped Up: Web Scraping Lessons Learned – ZwillGen, дата последнего обращения: августа 19, 2025, https://www.zwillgen.com/alternative-data/hiq-v-linkedin-wrapped-up-web-scraping-lessons-learned/
- Southwest Airlines Co. v. Farechase, Inc., 318 F. Supp. 2d 435 (N.D. Tex. 2004) – Justia Law, дата последнего обращения: августа 19, 2025, https://law.justia.com/cases/federal/district-courts/FSupp2/318/435/2472845/
- Preliminary injunction in American Airlines v. Farechase Inc. | Electronic Frontier Foundation, дата последнего обращения: августа 19, 2025, https://www.eff.org/document/preliminary-injunction-american-airlines-v-farechase-inc
- Court forbids ‘scraping’ of American Airlines web site, дата последнего обращения: августа 19, 2025, https://www.pinsentmasons.com/out-law/news/court-forbids-scraping-of-american-airlines-web-site
- Browser Fingerprinting and GDPR – Reddit, дата последнего обращения: августа 19, 2025, https://www.reddit.com/r/gdpr/comments/1dewvvl/browser_fingerprinting_and_gdpr/
- Processing biometric data? Be careful, under the GDPR – IAPP, дата последнего обращения: августа 19, 2025, https://iapp.org/news/a/processing-biometric-data-be-careful-under-the-gdpr
- DPA (GDPR) – Fingerprint, дата последнего обращения: августа 19, 2025, https://dev.fingerprint.com/docs/dpa-gdpr
- Кейсы наших клиентов – Защита от скликивания рекламы – Clickfraud, дата последнего обращения: августа 19, 2025, https://clickfraud.ru/kejsy-klientov/
- Google опубликовал полный список IP-адресов Googlebot – SEOnews, дата последнего обращения: августа 19, 2025, https://m.seonews.ru/events/google-opublikoval-polnyy-spisok-ip-adresov-googlebot/







