

В первой части статьи мы рассмотрели общие подходы к защите от скликивания. А сейчас перейдем к реализуемым нами механизмам борьбы с кликфродом.
Напомним, что кликфрод – это когда конкуренты за счёт бот-нет систем скликивают рекламу конкурентов на рекламных площадках, расходуя рекламный бюджет жертвы, тем самым «выбивая» его из рекламной выдачи. А нечестные на руку владельцы сайтов, размещающие у себя рекламу за плату, зарабатывают за счёт автоматизированных кликов. И те и другие приносят убыток и лишают сайт найти настоящих клиентов.
Для разработки системы защиты от скликивания рекламы, возьмём предложенную в предыдущей главе модель системы. Для создания минимально работающей модели в угоду скорости разработки было решено отказаться от интеллектуального модуля построения поведенческих карт, однако его разработка планируется в будущем. Также для первичного функционала было решено строить систему защиты от скликивания на рекламных площадках Яндекса.
1.1 Концепция разрабатываемой системы защиты от кликфрода
Чтобы понять, как защищать, нужно понять от чего защищаться. Система Яндекс Директа умеет защищаться от простых способов скликивания рекламы. Просто так с одно ip подряд скликать ничего не получится, Яндекс не засчитает эти клики, вернёт деньги и перестанет временно показывать рекламу. Однако важно понимать, что после возврата денег Яндекс больше не идентифицирует этого клиента как плохого, поэтому он может снова вернуться через некоторое время с кликами. Чтобы избежать детектирования со стороны Яндекса злоумышленники придумывают сложные схемы. В том числе перед кликом имитирую поведенческий трафик на сайте, переходя по ссылкам. Задачей разрабатываемой системы должно служить не только детектирование подозрительного трафика с рекламных площадок, но и возможность сохранить блокировку показа рекламы этому клиенту на долгое время. Чтобы решить это проблему необходимо все подозрительные сессии отметить в Директе, на основе этих пометок построить сегмент и выставить этому сегменту коэффициент в Яндекс Директе минус сто процентов.
1.2 Алгоритм работы системы защиты от скликивания
Напишем простой алгоритм, по которому может работать система:
- Сбор данных о посещении сайта.
- webdriver;
- идентификатор в рекламной системе (client id);
- Анализ полученного трафика, выявление подозрительного.
- существующие базы спам адресов;
- нецелевой рекламный трафик;
- наличие Webdriver.
- Фиксируем нежелательные сессии по client id.
- Отправляем полученные client id в Яндекс Метрику для формирования сегмента.
- В Яндекс Директе устанавливаем для этого сегмента коэффициент показа -100%.
Для начала работы определяем, как будут детектироваться автоматизированные сессии. Необходимо определить минимальные условия блокировки. Учитывая специфику блокировки скликивания, было решено сначала обратить внимание на сессии, которые являются кликами на рекламу. Так определим первое условие блокировки: посетитель пришёл с рекламы, находился на сайте менее 20 секунд, посетил только одну страницу, а его ip-адресс находится в одном из списков подозрительных адресов. Данное условие будет проверяться только на завершённых сессиях, с последнего действия в которых прошло более 30 мин. Надо понимать, что бот мог почистить cookie и снова зайти на сайт, поэтому следующим шагом ищем подобных в связке ip-адрес плюс отпечаток браузера (fingerprint), такая связка даст гарантию, что это именно тот же посетитель. Для системы мгновенной блокировки добавляем параметр webdriver, так как он нам говорит, что сессия точно автоматизированная и можно не ждать конца, по этому параметру также сверяем связку ip-отпечаток.
В итоге получаем следующий перечень из условий, которые будут первоначально учитываться в системе:
- параметр webdriver;
- приход с подозрительного ip адреса и моментальный отказ;
- блокировка по связке ip-отпечаток браузера.
Для следующих версий системы планируется добавить такие вещи как:
- блокировка на основе собственных списков ненадёжных ip-адресов, в которые будут добавляться найденные по другим алгоритмам ip,
- анализ на основе машинного обучения;
- блокировка по подсети.
1.3 Функциональные требования
Объектом разработки является группа процессов по обеспечению сбора, записи, хранению и обработке детальной информации о посетителях сайтов, на которых будет размещён скрипт с дальнейшей отправкой.
Информация, собираемая о посетителях сайтов, должна содержать данные позволяющие использовать максимальное количество инструментария по блокировке автоматизированного сбора.
Описание процессов, подлежащих автоматизации, приведено в таблице 1.
Таблица 1 – Процессы, подлежащие автоматизации
| № | Наименование автоматизируемого процесса (функций) | Обоснование необходимости автоматизации | Границы организационного охвата |
| 2 | Сбор данных о посещении сайта пользователем. | Накопленные данные позволят провести глубокий статистический анализ поведения. | Сбор действий посетителя на сайте. Сбор уникальных маркеров, посетителя. Проверка использования selenium webdriver или других средств автоматизации. |
| 3 | Обработка полученных «сырых» данных | Сырые данные трудно интерпретируемы. | Ограничение получаемых данных только необходимыми для дальнейшего использования. Приведение данных в объекты соответствующие базе данных. |
| 4 | Передача обработанной информации в базу данных | Хранение, накопление данных для будущего анализа. | Быстрая передача большого массива данных. |
| 5 | Сбор и анализ накопленных данных | Ручной анализ не обеспечивает быстродействия | Анализ новых сессий методами мгновенного детектирования. Анализ законченных сессий методами отложного детектирования. |
| 6 | Отправка идентификаторов подозрительных сессий в Яндекс.Метрику | Ручная отправка этих данных трудоёмка и не обеспечивает нужного быстродействия | Идентификаторы отправляются порциями по мере выявления. |
Разрабатываемая система должна включать в себя:
- веб-сервер, собирающий «сырые» данные о посещениях;
- базу данных, настроенную на высокопроизводительную выдачу данных, которые могут быть использованы в ходе будущего анализа;
- модуль скриптов, размещаемых на сайте.
- микросервис, позволяющее быстро получить, обработать сырые данные и записать в базу данных;
- микросервис анализа и блокировки;
Создание сегментов в Яндекс Метрике, а также выставление отрицательных коэффициентов для этих сегментов в Директе на данном будет производиться вручную.
1.4 Архитектура разрабатываемой системы
Проектируемая система будет представлять собой набор совместно взаимодействующих систем:
- Целевой сайт, для которого предполагается защита от автоматизированного сбора информации.
- Платформа сбора информации о посетителях ресурса.
- Локальная база данных, хранящая отформатированные данные.
Учитывая набор взаимодействующих систем, а также требования к характеристикам разрабатываемой системы, была спроектирована следующая архитектура системы (рисунок 11).
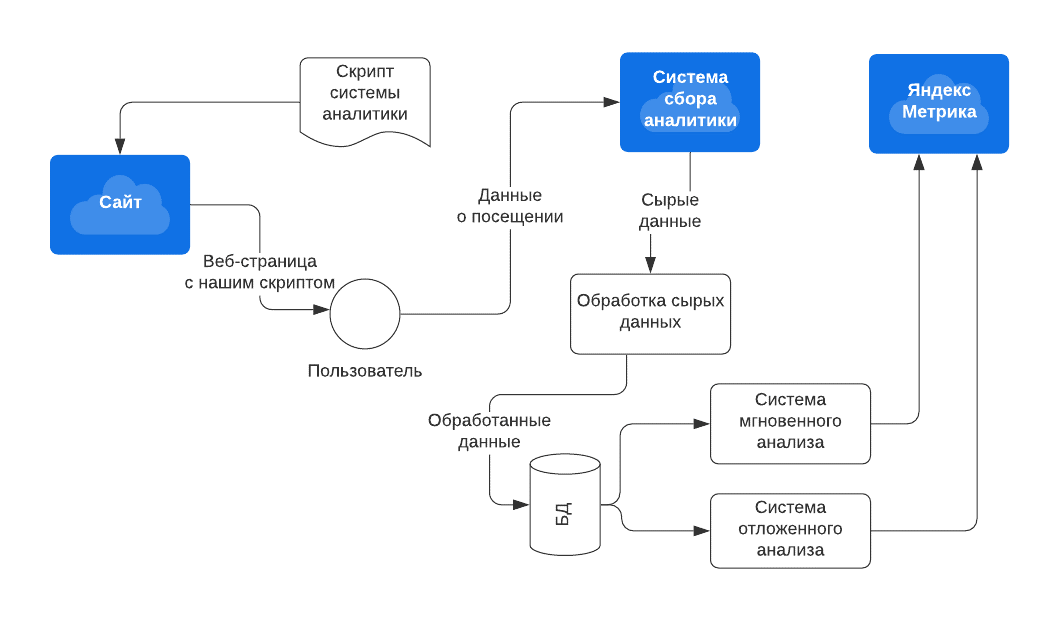
Рисунок 11 – Архитектура системы защиты от скликивания
Разработанная архитектура системы позволяет быстро настроить минимально работающее , а также в будущем масштабировать решение путем добавления новых обрабатывающих серверов, сервисов и баз данных. А выбранные средства разработки позволяют контролировать все этапы сбора информации, анализа и блокировки.
1.5 Выбор средств разработки
Решение задачи производилось на мощностях нашей компании, поэтому некоторые решения обусловлены доступностью инфраструктуры:
- Платформа для размещения кода на сайте клиента – Google Tag Manager.
- Система сбора данных о действиях пользователя – Matomo.
- База данных – Microsoft SQL Server.
- Платформа разработки ПО – .NET Framework, язык – C#.
Google Tag Manager – диспетчер тегов. Сервис позволяет из одного интерфейса управлять всеми тегами различных сервисов. На сайт интегрируется только один код, а остальные коды маркетолог самостоятельно добавляет в Диспетчер без участия IT-специалиста. В нашем случае данное решение помогает минимизировать контакты с клиентами при необходимости обновления кода скрипта и расширения его возможностей.
Matomo – это бесплатная система веб-аналитики с открытым исходным кодом. Система устанавливается на сервер владельца. Основное преимущество данной платформы перед такими онлайн сервисами как Яндекс Метрика является возможность полного контроля над хранящимися данными, удобный доступ ко всем данным через api, а также возможность отслеживания ip адресов и собственных параметров, в то время как решения от Яндекса не предоставляют информацию о ip, а собственные параметры обрабатываются больше дня.
Microsoft SQL Server – система управления реляционными базами данных, разработанная корпорацией Microsoft. СУБД масштабируется, поэтому работать с ней можно на портативных ПК или мощной мультипроцессорной технике. Размер страниц – до 8 кб, поэтому данные извлекаются быстро, подробную и сложную информацию хранить удобнее. Система позволяет обрабатывать транзакции в интерактивном режиме. Реализован поиск по фразам, тексту, словам, можно создавать ключевые индексы – что является особым преимуществом для нашей задачи.
1.6 Скрипт получения данных от пользователя
Система аналитики Matomo позволяет предавать для каждого визита или действия дополнительные пользовательские параметры, внедрив специальный js код на сайт. Данный инструмент позволит нам расширить базовые возможности сервиса и использовать параметры повышения точности детектирования пользователей за счёт таких средств как вычисление fingerprint браузера, вычисление использования средств автоматизации (таких как selenium web driver). Также для повышения точности, если сайт параллельно использует систему аналитики Яндекс Метрика, то мы можем в Matomo передать уникальный идентификатор, вычисленный самой метрикой.
Для того чтобы собрать все скрипты вместе, освободить клиента от установки множества файлов и дать нам возможность совершать будущие обновления в одностороннем порядке было решено использовать специальный менеджер тэгов. Таким был выбран Google tag Manager ввиду удобства и функциональности, наличию средств гибкой кастомизации (рисунок 13).
В менеджер тэгов было добавлено три скрипта: «Fingerprint», «Matomo+Ycid», «WebdriverDetect».
«Matomo+Ycid» – это основной скрипт инициализации, он запускает сбор действий на клиенте и отправляет в matomo. В дополнение к этому скрипт id Яндекс Метрики и также отправить его в matomo.
Для детектирования отпечатка браузера было выбрано свободно распространяемое решение fingerprintjs2. Данный скрипт позволяет не только получить уникальный идентификатор для браузера на основе множества параметров, но и гибко регулировать используемые параметры. Проведя некоторое время над скриптом, было решено оставить, только те параметры, которые сложно было подделать или изменить, а именно рендеринг изображений, аудиозаписей и другие параметры.
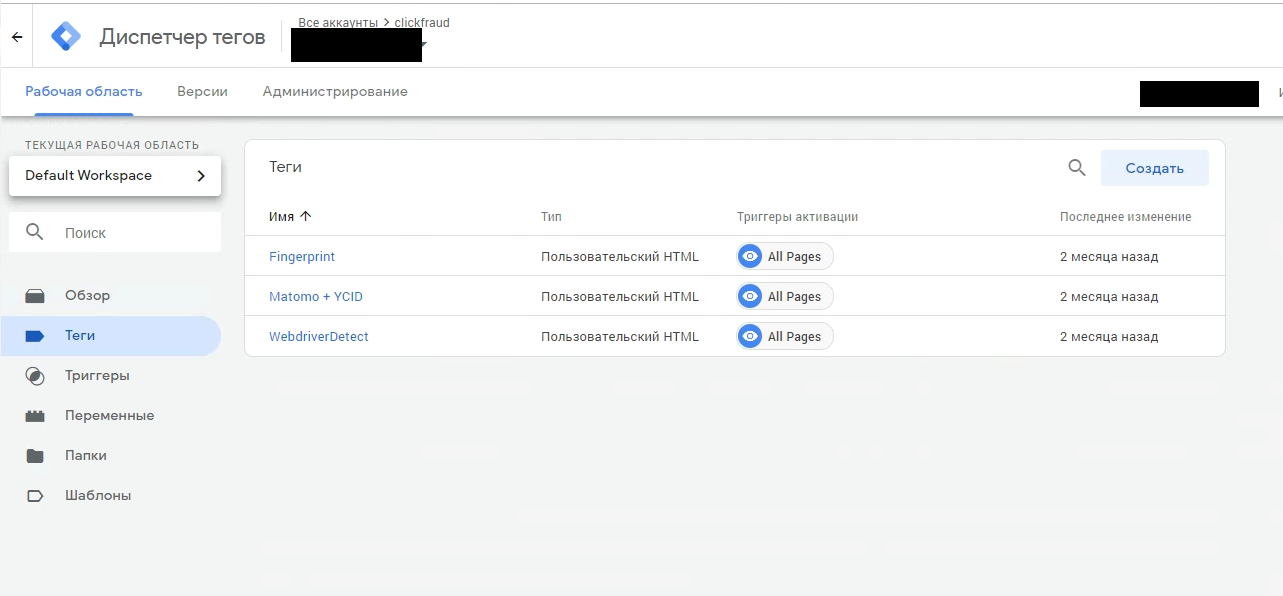
Рисунок 13 – Интерфейс Google Tag Manager
Скрипт «WebdriverDetect» написан с целью быстрого выявления браузеров, использующих средства автоматизации. Многие системы автоматизации браузеров (такие как Selenium Webdriver) внедряют для правильной работы служебные переменные, которые можно отследить с помощью js кода. Код был написан на основе сбора и компоновки воедино разных приёмов детектирования автоматизации.
Для правильной передачи данных из Matomo в локальную базу данных мы сделали программу-обработчик, которая будет каждую минуту параллельно в цикле проходить по результатам, приходящим от сервера, обрабатывать поля и вызывать написанную нами хранимую процедуру для записи в базу данных.
Следующим важнейшим модулем являются системы мгновенной и отложенной блокировки, для того чтобы уменьшить время написания кода и сделать проектируемую систему более гибкой, системы были объединены в общую систему, параметры для которой хранятся в базе данных. По сути, мгновенная блокировка отличается от отложенной, только тем какой должен быть минимальный возраст сессии. Мгновенная блокировка берет последние сессии, которые даже не закончены, а отложенная берет законченные или старше. Все эти параметры хранятся в базе и инициализируются при запуске программы. Чтобы достичь масштабируемости, ведь методы блокировки будут совершенствоваться и меняться с каждым днём, код был поделён на отдельные элементы:
- анализаторы;
- вспомогательные критерии для анализа;
- блокировщики.
Для связи друг с другом каждой группе были написаны интерфейсы, через которые они общаются. Получившуюся схему внутренней логики работы блокировщика можно посмотреть на рисунке 16.
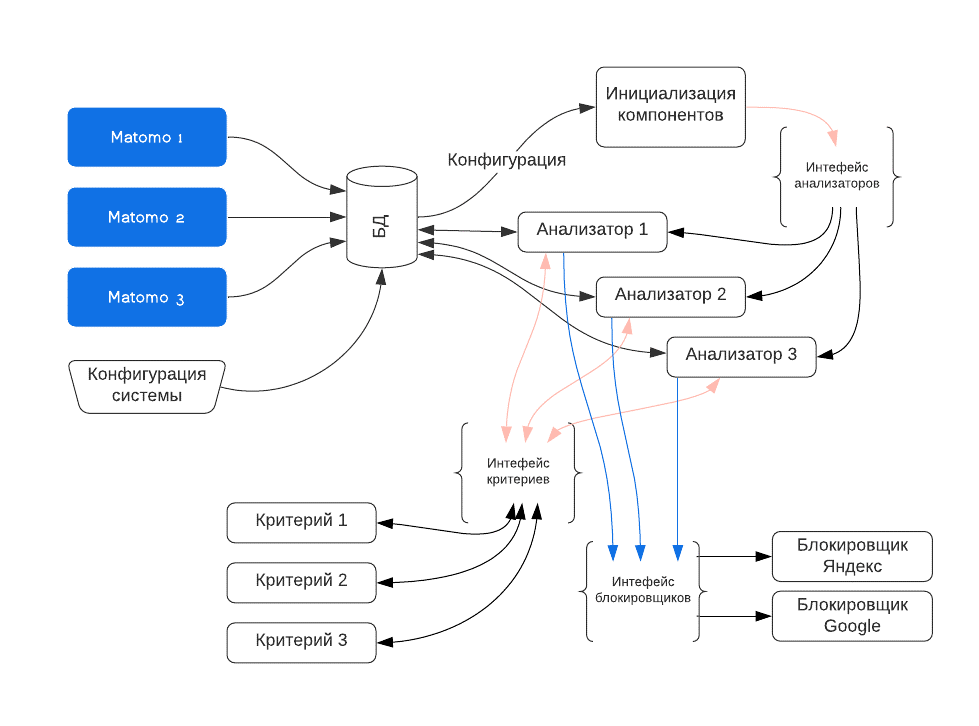
Рисунок 16 – Схема внутренней логики работы блокировщика
Получившаяся схема позволяет добавлять любое количество анализаторов. Учитывать множество критериев и способов блокировки. При необходимости можно будет добавить новый компонент-блокировщик и соответствующие ему анализаторы и настроить систему блокировать уже не только на рекламных площадках, но и на самом сайте, защитив его от парсинга. Полученная схема также позволяет в будущем, при добавлении достаточного количества критериев, вовсе отказаться от участия в блокировке программиста, так как все параметры гибко будут настраиваться через веб-интерфейс.
1.7 Тестирование системы защиты от скликивания
Для тестирования системы был подключен веб-ресурс с ежедневной посещаемостью примерно триста тысяч посещений в день. На сайте был установлен наш GTM скрипт, который начал передавать данные в реальном времени. В ходе работы сервиса мы убедились в его работоспособности, пример записанных данных можно увидеть на рисунке 17.
Рисунок 17 – Пример запроса на выборку
Разработанные решения по оптимизации записи в базу данных, позволили добиться максимальной производительности системы и обрабатывать большие массивы поступающих данных. На данный момент к системе подключено более сорока сайтов, для распределения нагрузки используется 3 сервера Matomo. В связи чем можно сделать выводы, что разработанное решение показывает высокую работоспособность и масштабируемость.
Чтобы убедиться, что блокируются именно автоматизированные сессии мы можем вывести список заблокированных сессий с параметрами и отсортировать их по ip-адресу (рисунок 18). На рисунке видно, что хоть мы и не используем пока алгоритмов по блокировке подсети, но заблокированные сессии находятся в одной подсети, все они кликают по рекламе и сразу же уходят. Можно обратить внимание, что есть сессии с одинаковыми отпечатками браузера в разные даты, что говорит о том, что бот использует одни и те же машины на протяжении нескольких дней.
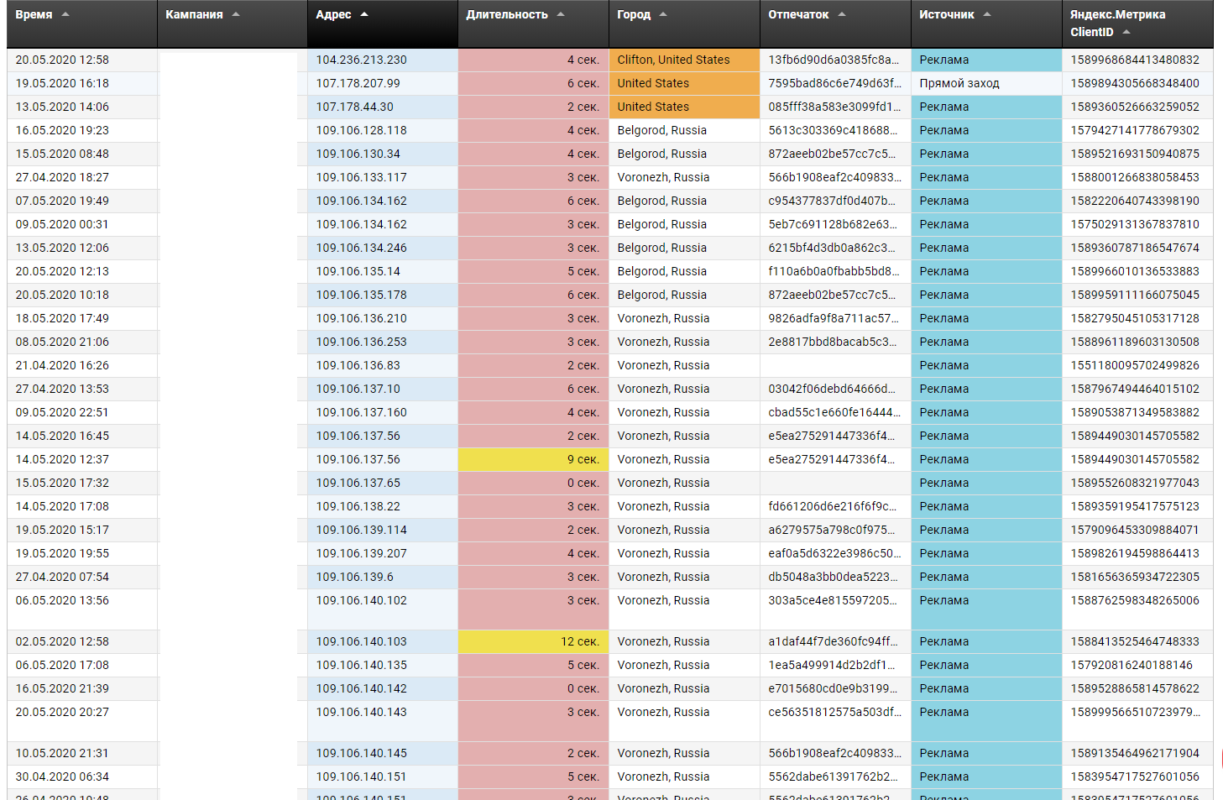
Рисунок 18 – Заблокированные сессии отсортированные по ip-адресу
Конечно, обычный человек не будет на протяжении двух месяцев упорно кликать по рекламе и уходить с сайта, при этом всё время используя новые ip – это нам даёт ясно понять, что все эти сессии автоматизированные, значит решение работает правильно, блокируя злоумышленников, вследствие чего им приходится использовать новые ip.
Для того чтобы убедиться в эффективности работы системы выгрузим дневную статистику по сайтам (рисунок 19). Выделим среди сайтов три типовых: крупный – site_id равное 7, средний site_id 3 и маленький site_id 15.
Дневная посещаемость у этих сайтов 281101 посетитель, 28617 и 1580 соответственно. В последней колонке приведено общее количество заблокированных сессий за выделенный день. А в колонке visits_adv_count содержится информация о общем количестве переходов с рекламы. Посчитаем для этих сайтов относительное процентное соотношение заблокированных сессий к числу визитов с рекламы.
(19898/117585)*100%=16,92% (1)
(2027/16399)*100%=12,17% (2)
(378/1285)*100%=29,42% (3)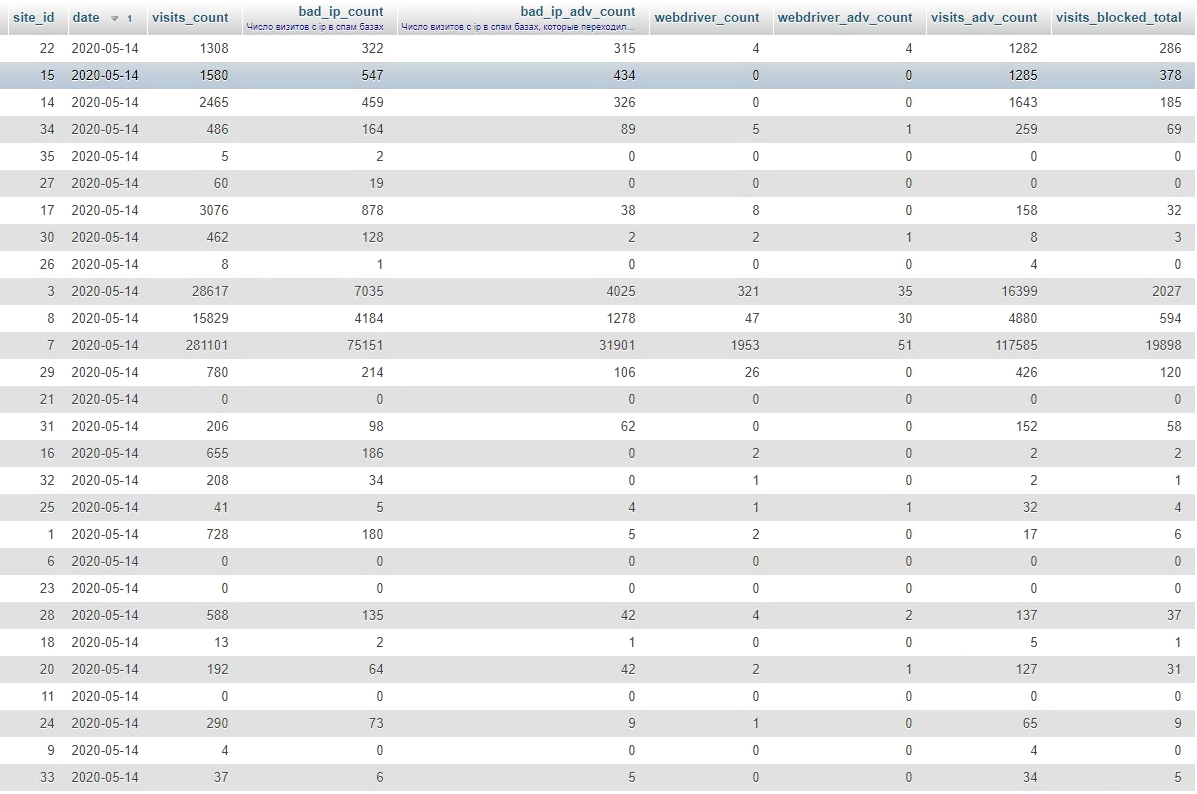
Рисунок 19 – Дневная статистика по сайтам
Из результатов подсчёта (формулы 1-3) видим, независимо от размера сайта процент заблокированных сессий достигает больше десяти-пятнадцати процентов для крупных и средних компаний, а для маленьких компаний этот показатель может достигать тридцати процентов. Это показывает нам то, что, используя простейшие алгоритмы можно отсечь большое количество автоматизированного трафика, за счёт чего сэкономить рекламный бюджет в будущем. Также это говорит, что есть ещё некоторое количество автоматизированного трафика, который скрывается более тщательно. И для борьбы с ними необходимо будет разработать алгоритмы машинного обучения, учитывания подсетей и других параметров, что значительно увеличит процент блокируемого автоматизированного трафика.
Заключение
В ходе проделанной аналитической работы нами были исследованы методы и способы борьбы с автоматизированным трафиком на веб ресурсах. На основе данной классификации реализована модель системы детектирования и блокировки автоматизированного трафика.
Проведённая классификация и предложенная модель являются инструментом для владельцев сайтов, которые хотят построить собственную систему защиты от автоматизированного трафика, с помощью них существенно можно ускорить разработку такой системы, учесть множество нюансов и сложных моментов и построить эффективную систему защиты.
Также нами разработана система защиты от скликивания рекламы – одного из видов мошенничества с помощью автоматизированного трафика. Система была нацелена показать эффективность и универсальность предложенной модели. В дополнение была разобрана эффективная масштабируемая схема программой части системы (рисунок 14), которая позволяет гибко настроить систему блокировки, выбирать разные схемы защиты, дополнять и дорабатывать алгоритмы, без сильного изменения программной части. А также при желании создать универсальный инструмент для борьбы с парсингом, скликиванием и со всеми другими видами автоматизированного трафика.
Результатом практической работы стала эффективная система борьбы со скликиванием рекламы, которая блокирует от десяти до тридцати процентов автоматизированных сессий по рекламе и имеет большой потенциал по развитию и усовершенствованию.







