Введение
В наши дни все больше товаров и услуг продаются через интернет. Зеркальным ответом стало появление рекламы в интернете. Это один из самых быстрых способов донесения коммерческого контента до потребительской аудитории.
Реклама устроена таким образом, что оплата рассчитывается в зависимости от количества кликов по рекламным объявлениям, а не за количество или длительность показов, как это бывает с классической рекламой по телевидению, радио или на билбордах. Ежедневно бюджет рекламной кампании ограничен внесенной суммой, при окончании бюджета показ рекламы прекращается. Рекламная кампания – это комплекс мероприятий по донесению визуального рекламного контента в интернете до конечных потребителей.
Рекламные площадки, продающие услуги показа рекламы, ранжируют объявления, чтобы не допускать перевесов в показах и кликах. Например, в поисковой выдаче выше показываются рекламные объявления, получившие наиболее высокий ранг из пула объявлений, подходящих под запрос. На этой почве появляются мошенники, желающие «поднять» свои объявления, увеличив их показы и «опустить» объявления конкурентов, минимизировав переходы по ним.
Скликивание, кликфрод (англ. click fraud – мошенничество с кликами) — это процесс намеренного (автоматизированного) увеличения количества нецелевых переходов по рекламной кампании (таким образом, бюджет скликивается). Защита от скликивания – комплекс мер по предотвращению появления нецелевых кликов и минимизации ущерба от атак. Защита чаще всего строится на блокировке пользователей или групп пользователей в рекламных системах по ip, id на основе cookie или иным способом.
Подходы к защите от скликивания у наиболее популярных в России рекламных площадок, таких, как Яндекс.Директ и GoogeAds, эффективны не против всех видов атак. Чаще всего они признают автоматизированными только заходы с применением Selenium webdriver. Современные боты помимо маскировки использования Selenium webdriver (или применения других средств автоматизации управления браузером) также могут имитировать действия реальных пользователей, делая себя почти не отличимыми от обычных посетителей сайта с точки зрения систем обнаружения, встроенных в рекламные объявления.

Классические подходы к защите от скликивания, основанные на условном анализе формальных параметров сессий, становятся все менее эффективными в силу нескольких причин. Во-первых, все чаще корпорации, имеющие значительное влияние на тенденции развития веб-технологий (компании, создающие и поддерживающие браузеры, популярные библиотеки и фреймворки, языки программирования, поисковые и рекламные системы и т.д.), продвигают идеи анонимизации пользователей [1]. Они затрудняют или и вовсе делают невозможным сбор некоторой информации о личности пользователя или технических характеристиках его компьютера. Такие данные могут быть использованы не только для идентификации пользователя без необходимости его регистрации и входа в систему или для показа определенного контента на основе определенных ранее предпочтений, но и в мошеннических целях. Чтобы усложнить задачу мошенникам, пользователя обезличивают и представляют его как некий набор характерных черт или как принадлежность к одному классу из некоторого разбиения.
Во-вторых, разработчики ботов создают все новые методы обхода защит. Появляются боты, которые «блуждают» в интернете. Посещая случайные страницы, они имитируют действия пользователя: передвигают указатель мыши, нажимают на кнопки, переходят по ссылкам, имитируют прокрутку колёсика мыши. Некоторые боты могут повторять человеческие сценарии поведения, составляя корзину, оставляя заявки на обратный звонок, переходя по ссылкам со схожей тематикой, при заходе на сайт дав согласие на сбор всех cookie файлов и разрешив получение уведомлений от сайта. Своими действиями боты создают себе историю и набор cookie файлов, характерных для обычного человека. Они буквально очищают себя почти ото всех формальных параметров (в т.ч. и некоторых алгоритмически вычисляемых), отличающих их от человека.
Разработанная нами служба комплексно анализирует открытые параметры пользователей при помощи методов машинного обучения. Данный поход позволяет обойти проблему отсутствия формальных отличительных параметров у ботов и использовать анонимизацию в борьбе против мошенников при защите от скликивания.
В связи с наступлением пандемии коронавируса нового типа в 2020-м году и сопутствующим введением карантинного режима многие предприниматели, работающие в сфере B2C[1], были вынуждены ограничить работу своих точек продаж и предоставления услуг или и вовсе закрыть их. Не каждый бизнес оказался готов к таким значительным неожиданным изменениям условий рынка. Чтобы не допустить критического снижения доходов и банкротства своего бизнеса, некоторые бизнесмены частично или полностью перевели работу в онлайн. В том числе, начали выставлять рекламу в интернете [3].
Помимо увеличения количества рекламы в интернете некоторые недобросовестные предприниматели в своём стремлении обойти конкурентов стимулировали и развитие бот-сетей, покупая их услуги. Владельцы бизнесов прибегают к мошенничеству с целью влияния на алгоритмы рекламных систем, ранжирующих объявления в выдаче. Этот подход в действительности не имеет прямого влияния на ранжирование объявлений мошенников, они лишь опускают (или и вовсе удаляют из выдачи) скликиваемые объявления конкурентов.

В купе с этим повысился и спрос на защиту от скликивания, при том, требования к ней сильно возросли. Имеется в виду не только очевидное требование к способности обнаружения продвинутых ботов. Например, современный конкурентоспособный сервис защиты от скликивания должен уметь блокировать и другие источники нецелевых кликов помимо ботов, совершающих атаку на рекламу сайта. Нежелательными можно назвать любые клики, не приводящие к увеличению конверсии[2] сайта, такие как:
- Злонамеренные клики конкурентов и недоброжелателей,
- Клики одиночных ботов и ферм,
- Случайные клики обычных людей по рекламе [5].
Также защита от скликивания необходима и сайтам, предоставляющим место для размещения рекламы (рекламным площадкам), чтобы боты не могли скликивать ее, тем самым понижая рейтинг площадки в глазах рекламной системы и рекламирующихся брендов. Это может привести к отказам от размещения рекламы на данном сайте и снижению доходов его владельца [6].
Таким образом, ущерб от скликивания рекламы в действительности весьма велик и затрагивает не только скликиваемые рекламные кампании, но и рекламные площадки. В теории возможность скликивания объявлений рекламной системы должна влиять и на популярность самой системы, но в сложившейся неконкурентной монополистической обстановке это маловероятно [9]. Большинство рекламных мест поделено между крупными корпорациями и у них нет рисков их потерять. Это реклама на интернет-страницах и порталах с большим ежедневным потоком пользователей. Среди «гарантированных» рекламных мест можно перечислить:
- Реклама в поисковой выдаче,
- Реклама в медиа ресурсах,
- Реклама в социальных сетях.
Единственной сферой, в которой рекламные системы могут конкурировать – независимые площадки. К независимым площадкам относятся:
- Частные сайты и порталы
- Частные мобильные приложения
Также существует интегрированная реклама, но скликивание на ней не имеет смысла, так как она почти не относится к рекламным площадкам.
Существующие решения по защите от скликивания
На данный момент на рынке представлено несколько решений для защиты от скликивания. В Таблице 1 приведены некоторые сервисы (включая и наш), работающие и в России, и за рубежом [11].
Таблица 1. Сервисы защиты от скликивания
| № | Название | Количество отзывов | Краткое описание, особенности |
| ClickCease | > 200 | Крупный западный сервис, ориентированный на защиту рекламы в Google Ads и Bing. Заявлена эффективность против любых форм скликивания. Не поддерживает Яндекс.Директ. | |
| ClickGUARD | > 120 | Сервис, разработанный международной компанией, отличается возможностью контроля за всем платным трафиком. Заявлена передовая интеллектуальная система, обнаруживающая любых ботов. | |
| PPC Protect | > 70 | Международный сервис, ограничивающий клики мошенников по рекламе с помощью специального алгоритма и базы известных ботов. | |
| Clickfraud.ru | > 10 | Наше собственное решение для защиты от скликивания. Работает с Яндекс.Директ и Google Ads. | |
| Clickfrog.ru | > 3 | Отечественный сервис с более широким функционалом. Защита от скликивания – не основная его часть, заявлены оптимизация рекламных кампаний и отслеживание их работы. |
Как хорошо видно из Таблицы 1, отечественный рынок не содержит спектр решений для удобного интеллектуального мониторинга скликивания для всех популярных в России рекламных систем.

Цель нашего сервиса
Мы разрабатываем отдельный сервис для системы защиты от скликивания, позволяющий в режиме реального времени анализировать интернет-трафик и выделять нежелательные сессии среди общего потока. При том, необходимо удостовериться в эффективности предлагаемого анализа против нежелательных кликов, которые не поддаются классическому условному анализу формальных параметров. Также сервис должен гарантировать уменьшение текущей погрешности. В данном случае текущей погрешностью является погрешность работы существующей части сервиса. Погрешность работы оценивается при помощи отношения 1.
| δ = m + n / k | (1) |
Здесь δ – погрешность, m и n – количество ложно заблокированных пользователей и количество незаблокированных ботов соответственно, а k – общее количество блокировок.
Какие есть требования к сервису защиты от кликфрода?
В процессе проектирования и реализации необходимо учитывать, что создается не полностью автономный самодостаточный сервис, а компонент системы, выполняющий конкретную задачу. Существующая система имеет свою архитектуру и построена на основе определенного стека технологий, так что надо выбирать технологии и стандарты (связи, формата данных) для обеспечения совместимости разрабатываемого сервиса с ней. Также требуется обеспечить сохранение совместимости сервиса с системой после возможного обновления стека технологий системы в будущем.
Анализ должен производиться в режиме реального времени с достаточной скоростью, чтобы не вызывать задержек в работе системы. При увеличении количества анализируемых сессий в n раз суммарный срок их обработки должен увеличиваться менее, чем в n раз. Не допускается и чрезмерное использование памяти. Сервис не должен хранить в ОЗУ длительное время данные, если нет необходимости в частом обращении к ним (как минимум раз в несколько сессий анализа).
Анализ не должен быть основан на условном сравнении параметров и должен возвращать некоторую вероятность того, что заход выполнен ботом (т. н. уровень подозрительности сессии). Система должна носить детерминированный [3] характер. [7] При необходимости при подготовительных к анализу работах допускается использование сторонних открытых источников данных (в том числе базы данных, датасеты и API). Обращаться к ним можно только в двух случаях:
- Обращение требуется только один раз при создании сервиса;
- Обращение к ним не влечет серьезных изменений в скорости работы сервиса и его ресурсоёмкости.
Конечный сервис должен быть оформлен как отдельное приложение под операционную систему Windows для возможности установки на одном сервере с остальными частями системы. Для унификации запусков, обработки ошибок и логирования [4] необходимо предусмотреть возможность регистрации сервиса как службы Windows, определив обработку таких событий, как:
- Старт службы,
- Остановка службы,
- Возобновление работы службы,
- Запись лога в системную папку для возможности просмотра через Windows Event Viewer [8].
Сервис должен либо иметь возможность настройки чувствительности анализа, либо предоставлять окончательный выбор, блокировать сессию или нет, тому, кто обращается к сервису. В первом случае сервис должен ожидать на вход некий параметр, линейно влияющий на результат его работы. Такой параметр может задаваться вручную или являться результатом некоторого анализа конверсии на сайте. При втором же варианте построения интерфейса взаимодействия с сервисом от него ожидается некая рекомендация, на основании которой может быть вынесено окончательное решение. Такой функционал необходим, так как реклама каждого отдельного сайта скликивается в разной степени и их владельцы могут ожидать разной работы от системы защиты от скликивания.
Краткое описание системы защиты
Создаваемый сервис предполагает защиту от скликивания с использованием кластеризации. Такую службу можно продумать, разбив на 3 основные части следующим образом:
- Сбор данных пользователей. Сперва на основе стороннего интернет-сервиса создается клиентское приложение, собирающее данные пользователей, заходящих на сайт. Необходимо также продумать, как формально отличать хороших пользователей от плохих. Например, можно использовать достижение хотя бы одной цели конверсии как факт того, что сессия хорошая; и наличие средств автоматизации тестирования и/или действий браузера как факт того, что сессия плохая. В существующей системе (для которой разрабатывается сервис) уже есть некоторые способы определения качества сессий, также допускается их использование.
- Создание аппарата вынесения решений. Следующий этап – подготовка данных. При помощи подготовленных данных сгруппируем похожие сессии и определим группы, в которые с большей вероятностью попадут боты. Группировать будем посредством методов кластеризации машинного обучения с применением алгоритма k-средних. Количество кластеров заранее неизвестно, но необходимо, чтобы их было не менее трёх для сохранения нечёткости логики вынесения решений. Необходимо также подобрать оптимальное количество кластеров (подойдет и локальный оптимум при рассмотрении не менее десяти последовательных вариантов).
- Блокировка по полученной модели. После получения обученной модели необходимо настроить конвейер для распределения новых сессий по кластерам в режиме реального времени. Таким образом, в конвейер также необходимо встроить обработку сырых данных для подачи на вход алгоритму. Также потребуется модуль вынесения решений на основании работы алгоритма. Он может входить либо в разрабатываемый сервис, либо в существующую систему. В дополнение можно продумать систему кеширования данных, если в процессе разработки возникнет необходимость в повышении производительности или скорости работы сервиса [10].
Техническая сводка системы защиты от кликфрода
Сервис будет состоять из нескольких частей, обеспечивающих разные этапы (или отдельные процессы) в его работе. Архитектура, как и более подробное описание технических средств, будут описаны ниже, в Таблице 2 лишь перечислены конкретные способы реализации отдельных модулей с кратким описанием.
Таблица 2. Используемые технологии
| № | Модуль применения | Название технологии | Описание технологии |
| Сбор данных | Matomo | Открытый сервис для анализа посещений сайта | |
| Клиентская часть | GTM | Менеджер тегов для html-страниц | |
| Серверная часть | .NET 5 | Фреймворк для кросплатформенной разработки | |
| Обращение к сервису | gRPC | Платформа удаленного вызова процедур | |
| Подготовка данных | HTTP | Протокол передачи данных | |
| Машинное обучение | ML.NET | Платформа для машинного обучения |
Резюмируя, сформулируем постановку задачи. Необходимо создать отдельный независимый сервис вынесения решений о качестве интернет-сессий пользователей на основе отнесения их к одной из групп. Также требуется реализовать автоматизированный сбор всех необходимых данных, а разделение посетителей на группы осуществить при помощи методов машинного обучения. Полученный сервис должен иметь возможность работы в реальном времени.
Используемые технологии для защиты
Для реализации проекта необходимо собирать открытые данные пользователей во время их визитов на защищаемый от скликивания сайт. Данное утверждение основывается на предположении, что существует возможность отличить бота от реального человека, опираясь на открытые параметры его сессии (в т.ч. с нахождением и учётом скрытых связей). Сбор должен осуществляться при помощи установки скрипта (или набора скриптов) на клиенте, который бы запускался во время открытия страницы в браузере, считывал различную информацию о пользователе, сессии и устройстве и отправлял ее на хранение на удаленный ресурс.
Для таких целей используются интернет-сервисы веб-аналитики, рассмотрим некоторые из них.
- Google Analytics. Это бесплатная платформа веб-аналитики, разработанная компанией Google (платный аналог с расширенным функционалом – Google Analytics Premium). В описании данной платформы заявлена возможность сбора всесторонней информации и набор инструментов для анализа эффективности интернет-маркетинга, основанного на ней. Для удобства использования сервиса через веб-интерфейс его разработчики предоставляют интеллектуальную помощь, затрагивающую настройку интерфейса и сбора данных и составление отчета по ним. Подсказки генерируются на основе данных машинного обучения таким образом, чтобы максимально эффективно использовать собранную информацию.
Google Аналитика имеет возможность привязки к другим сервисам Google, связанным с электронной коммерцией, таким как Google Ads (бывш. Google AdWords, сервис для выставления рекламы в интернете) и Google AdSense (сервис для монетизации творчества). - Яндекс.Метрика. Это бесплатная отечественная платформа веб-аналитики от компании Яндекс. Сервис рассчитан на построение разнообразных разносторонних наглядных отчетов об активности на сайте. Он предоставляет ряд инструментов для отслеживания источников любого трафика и оценки рекламных кампаний. При том, особенностью является ряд возможностей для анализа эффективности не только интернет-рекламы, но и рекламы, выставляемой классическими способами (офлайн-рекламы). Также в Метрике есть функция просмотра видеозаписи действий пользователя на сайте, так называемый Вебвизор. За дополнительную плату Яндекс.Метрика предоставляет только один инструмент – целевой звонок. Он позволяет проводить анализ звонков и строить на основе него статистические отчёты по эффективности разных способов донесения рекламы до конечных потребителей предоставлением виртуальных номеров телефонов, переадресовывающих звонки на основной. Аналогично Google Ads Яндекс.Метрика полностью интегрирована в родительскую экосистему и позволяет дополнительно анализировать рекламные кампании, проводимые при помощи сервиса Яндекс.Директ.
- Matomo (бывш. Piwik) – сервис веб-аналитики с открытым исходным кодом, созданный множеством разработчиков по всему миру. Это гибкая платформа с множеством расширений и плагинов, среди которых есть и платные, и бесплатные. Благодаря открытому исходному коду также есть возможность самостоятельного написания плагинов. Этот инструмент полностью устанавливается на сервере, и данные, собранные с сессий пользователей, всецело хранятся там же, а разработчики, развивающие сервис, не имеют доступа к ним. Также особенностью является полностью настраиваемый веб-интерфейс, в котором можно не просто менять местами графики и разные метрики, но и добавлять информеры[5] сторонних плагинов. В том числе, есть возможность на одном аккаунте анализировать несколько сайтов, быстро переключаться между ними и даже просматривать единую сводную статистику по ним на одном экране.
Для наших целей более всего подходит Matomo, так как все данные будут храниться на нашем сервере. Например, Google Analytics открыто заявляет, что будет использовать полученные данные в «собственных целях», что недопустимо при работе с реальными клиентами. Также Matomo предоставляет наиболее простое, но при том полное API. Программный интерфейс других перечисленных сервисов стандартизирован, и от того более сложен. Быстрота и простота настройки – немаловажные факторы при создании приложения. Еще одно преимущество Matomo – высокая степень гибкости. Для кластерного анализа потребуются некоторые данные, которые не собирают сервисы веб-аналитики «из коробки». Выбранный сервис поддерживает широкий спектр расширений, позволяющих собирать необходимые данные. Google Аналитика и Яндекс.Метрика больше нацелены на анализ рекламных кампаний, который не требуется в нашем случае.
Клиентская часть системы защиты от скликивания
Как было указано в предыдущем параграфе, необходимый сбор данных осуществляется установкой скрипта на клиенте. Однако помимо самого сценария веб-аналитики в нашей работе могут понадобиться и некоторые другие, такие как:
- Google reCAPTCHA v3 – бесплатное программное обеспечение (ПО) для выделения ботов на основе оценки, высчитываемой в фоновом режиме. Капча не дает гарантий точности работы и, следовательно, может быть использована лишь как часть анализа.
- Счётчик Яндекс.Метрики – часть экосистемы Яндекс.Метрики, собирающая информацию для веб-аналитики. Помимо сбора информации о сессии также выдает каждому посетителю уникальный идентификатор – yandex client id (yaClId) на основе Cookie-файлов, давая возможность вызывающему её скрипту получить этот id. Используется для блокировки пользователей по их yaClId при помощи составления сегмента в Яндекс.Метрике и отключения показа рекламы членам данного сегмента.
- FingerprintJS – бесплатное ПО для идентификации анонимных пользователей. Составляет так называемый «отпечаток пальца» браузера – строку-хеш с зашифрованной информацией о системе. Идеально работает данный подход только в теории, так как в идентичных системах такой отпечаток будет одинаковым. Также разработчики браузеров всячески препятствуют вычислению фингерпринтов для анонимизации пользователей, подменяя анализируемую информацию и лишая отпечаток детерминированности. Таким образом, данный анализ тоже может быть использован лишь как часть цепочки аналитики.
- Определение использования Selenium Webdriver при заходе на страницу – необходимая часть анализа, так как положительный результат данной метрики гарантирует, что сессия выполнена при помощи средств автоматизации (ботом). Также используется как часть анализа.
Интеграция перечисленных скриптов в систему Matomo не предусмотрена изначально, однако гибкость данного сервиса позволяет отправлять пользовательские переменные как дополнительные параметры сессий в веб-аналитику. Результаты работы скриптов и будут отправляться как пользовательские переменные. Для Google reCAPTCHA v3 это вынесенная оценка, для счётчика Яндекс.Метрики – yaClId, для FingerprintJS – сам фингерпринт, а для скрипта определения Selenium Webdriver – буль, определяющий наличие средств автоматизации тестирования.
Таким образом, необходимо разработать сценарии-обёртки над перечисленными скриптами, инициализирующие и вызывающие их и передающие выходные значения в Matomo. Для обеспечения бесперебойной работы при обнаружении багов в самописных скрипах и при необходимости их обновления (например, в случае обновления условий использования браузеров или версии языка JavaScript) используются так называемые менеджеры тегов. Менеджер тегов – сервис, позволяющий удаленно добавлять и изменять добавленные теги в HTML разметку сайта (или разметку мобильного приложения). Такой подход дает возможност править фрагменты кода (теги) без необходимости непосредственного редактирования HTML файлов.
Google Tag Manager (GTM) – менеджер тегов от компании Google. Его код устанавливается на страницу и при ее рендеринге добавляет заранее определенные теги в разметку. Данный сервис предоставляет удобную систему управления версиями тегов и возможность создания нескольких рабочих областей, что может быть полезно для одновременной работы по доработке функционала несколькими членами команды. Еще в GTM есть возможность управления очередностью запуска тегов или определения триггеров для их активации. Также реализован функционал создания глобальных переменных и их инициализации.
Серверная часть системы защиты от скликивания
Серверная часть разрабатываемого сервиса создавалась с учетом особенностей существующей системы распознавания и блокировки ботов по формальным параметрам. Существующая часть написана на языке C# версии 6 под платформу .NET Framework 4.7.2. Однако помимо совместимости важным параметром является современность технологий (для обеспечения безопасности и бесперебойности работы) и возможность предоставления длительной поддержки. Также в будущем планируется контейнеризация [6] всей системы, и для того, чтобы не зависеть от ранее выбранной ОС (Windows 10), более правильным подходом будет выбор кроссплатформенного фреймворка для разработки сервиса.
Наиболее современный фреймворк кроссплатформенной разработки из экосистемы .NET – .NET 5, ставший наследником двух ранее развиваемых раздельно фреймворков – кроссплатформенного .NET Core и .NET Framework под ОС Windows. Он позволяет также использовать существующий код, написанный под более старую платформу. Тем не менее, кроссплатформенность и поддержка старого кода – не единственные причины выбора данного фреймворка. Существуют фундаментальные различия между перечисленными платформами, обратимся к рекомендациям Microsoft (компания, выпускающая .NET) по выбору фреймворка. Среди случаев рекомендованного использования .NET Framework – если приложение уже разработано под .NET Framework (именно само приложение или проект, для которого выбирается платформа, а не другие сервисы в системе или проекты в решении) или если приложение использует некоторые технологии, платформы или библиотеки, не поддерживаемые .NET Core/5+ (имеются в виду .NET Core и .NET версии 5 и более поздних версий). .NET Core/5+ же рекомендуется использовать в случаях, когда требуется кроссплатформенность, создается приложение, ориентированное на микросервисную архитектуру, планируется контейнеризировать приложение при помощи Docker (докеризировать) или требуется возможность сохранения высокой производительности при масштабировании системы. Также поводом для применения .NET 5 может стать необходимость поддержки кода под разные версии .NET.
Как видно, для наших целей наиболее подходящей платформой является .NET 5, так как выполняются все условия, при которых Microsoft рекомендует её использование.
При выборе версии языка C# было решено использовать версию 8, так как в ней были добавлены некоторые особенности синтаксиса, которые помогают улучшить внятность кода и ускорить процесс разработки приложения. Также данная версия языка по умолчанию поставляется с компилятором .NET 5, что облегчает её использование.
Обращение с сервису защиты
Разрабатываемый сервис с машинным обучением будет использоваться как вычислитель параметра, определяющего необходимость блокировки показа рекламы конкретному пользователю. Похожие вычислители уже используются в существующей системе, но они имеют ряд особенностей, отличающих их от нового сервиса. Во-первых, они просто анализируют формальные параметры, производя ряд несложных вычислений лишь по необходимости. Во-вторых, при их создании не требовалось длительной настройки, сложного анализа, создания и проведения более одного теста (пусть и с несколькими кейсами[7]). В-третьих, для их работы нет необходимости в заблаговременной подготовке некоторых данных.
Существующие вычислители (критерии подозрительности сессии) оформлены как классы, чьи методы вызываются прямо в пайплайне[8] анализа и блокировки. Такой же подход к использованию разрабатываемого функционала допустим, но не оптимален. Новый сервис будет в разы более ресурсоёмким, будет оперировать набором сущностей и требовать предварительного обучения с сохранением полученных в результате него файлов на жёстком диске. Также, чтобы не блокировать работу основного пайплайна, он должен вызываться в отдельном потоке. Вдобавок понадобится составление тестов и создание некоторого функционала, который будет использоваться только при разработке сервиса.
Перечисленные особенности можно реализовать в рамках одного класса, однако логичнее разместить их за пределами основного пайплайна в отдельном микросервисе.
Остальные микросервисы существующей системы, состоящие в основном пайплайне, используют базу данных как способ передачи данных друг между другом. Разрабатываемый сервис отличается от существующих тем, что он должен выполнять некоторые действия по запросу от других микросервисов и возвращать ответ, а не циклично проводить некоторые действия, опираясь на полученные ранее данные. Таким образом, требуется некоторая система удаленного вызова методов через протокол HTTP, на основе которой можно будет создать службу; рассмотрим некоторые из существующих решений. Приведены не взаимозаменяемые технологии, выполняющие одинаковые функции, а лишь возможные подходы к решению поставленной задачи.
- Windows Communication Foundation (WCF) – гибкий фреймворк, позволяющий создавать приложения под .NET Framework и ОС Windows с возможностью передачи данных между ними. Сообщения могут быть представлены в формате XML или как поток данных в двоичном виде. Компания Microsoft, разрабатывающая данную платформу, предлагает несколько шаблонов форматов обмена сообщениями, среди которых:
- Одностороннее сообщение – простой шаблон, в котором одна точка (приложение) посылает запрос на другую точку и не ожидает при этом ответа;
- «Запрос-ответ» – самый часто используемый шаблон, в котором одна точка посылает запрос другой точке и получает ответ;
- Двустороннее общение – более сложный шаблон, при котором две точки устанавливают соединение и обмениваются сообщениями, доставляемыми мгновенно;
- И некоторые другие.
Также WCF предоставляет широкий функционал для обеспечения безопасности обмена сообщениями, их бесперебойности, расширяемости разрабатываемых сервисов, интеграции с другими инструментами Microsoft (в т.ч. использование классов C# как основы для автоматического построения формата обмена данными) и многое другое.[16]
- SOAP HTTP API – совокупность протокола передачи данных (HTTP) и их формата (SOAP-XML). Формат обмена сообщениями SOAP не обязательно используется с транспортным протоколом HTTP. Подразумевает передачу чётко структурированных данных и обязательных метаданных в формате XML, включающих:
- Конверт (envelope) – корневой элемент, определяющий структуру данных и пространство имён;
- Заголовок (header) – некоторые атрибуты посылаемого сообщения;
- Тело (body) – сами передаваемые данные;
- Ошибки (fault) – опциональный элемент, содержащий информацию об ошибках.
Несмотря на очевидные плюсы высокой структурированности данных, такие как надежность и простота интерпретации, есть и существенные минусы. Например, объем самих сообщений значительно увеличивается при использовании такого подхода, следовательно, возрастают и накладные расходы на их передачу и чтение.[17]
- JSON REST API – совокупность формата передачи данных (JSON) и архитектурного стиля взаимодействия (REST API), при том REST API не всегда используется совместно с форматом JSON, однако он самый популярный. REST представляет собой набор строгих правил, которым должен соответствовать API, чтобы называться RESTful (созданным по архитектуре REST). Данная архитектура подразумевает использование протокола HTTP для передачи сообщений.[17]
- Google Remote Procedure Call (gRPC) – платформа с открытым кодом, предоставляющая возможность удаленного вызова процедур. Существуют реализации для десяти самых популярных языков программирования, в том числе, C#. По умолчанию поддерживает одиночные вызовы и стриминг[9] в качестве форматов обмена сообщениями между приложениями. Также есть возможность отправки метаданных, что может использоваться, например, для передачи идентификаторов сессии или краткой информации об ошибке (например, ее кода). Обмен данными идет при по wire-протоколу, работающему «поверх» протокола HTTP/2. Формат данных описывается при помощи специального языка описания интерфейса (Interface Definition Language, IDL), в качестве которого в реализации под .NET используется язык proto3. Для отправки сообщений используются объекты классов, по структуре соответствующих моделям данных, описанным на proto3. Данный формат поддерживает широкий спектр типов как скалярных, так и векторных (например, массивы байт, строки). Также полем сообщения может являться другое сообщение, что открывает возможности для передачи сложной иерархии объектов. Важной особенностью является поддержка таймаутов[10] запросов их отмены. Причем отменить запрос можно как с клиентской стороны, так и с серверной.[18]
Документация платформы .NET 5, используемой для создания нового сервиса, предоставляет свободно распространяемый шаблон для проектов ASP.NET Core, работающих на основе технологии gRPC. Microsoft позиционирует эту платформу как кроссплатформенного потомка WCF, расширяющую её возможности. Данный подход довольно прост, он работает на основе технологии .NET Core Workers, регистрируя специальный класс работы, обрабатывающий сообщения. При том полезной будет функция добавления таймаутов ожидания ответов. Благодаря ним можно синхронизировать запросы и обрабатывать их порциями, по нескольку за один такт. Это необходимо для бесперебойной работы сервиса. Также метаданные в сообщениях будут служить для передачи кодов ошибок.
Подготовка данных для машинного обучения
Для машинного обучения может не всегда быть достаточно имеющихся данных. Некоторая информация нуждается в уточнении или интерпретации. Целью данного этапа является извлечение значащих данных из собранной информации более высокого уровня абстракции и формирование датасета машинного обучения. Однако функционал, разработанный для подготовки первоначального датасета также будет использоваться при штатной работе сервиса, так как и данные новых сессий пользователей необходимо будет приводить к одному виду. Например, название страны надо будет преобразовать в её код в соответствие с какой-либо системой; более полное перечисление применений будет описано ниже. Как легко видеть, такие данные не всегда можно преобразовать, ограничиваясь внутренними вычислениями, требуются какие-то дополнительные ресурсы. Среди широко распространенных открытых источников такой информации можно перечислить:
- Открытые датасеты. В интернете можно найти множество открытой полезной информации и использовать её в своих целях. Например, распространены наборы данных с бесплатным доступом, которые можно использовать в качестве основы для тренировки алгоритмов машинного обучения. Также существуют открытые наборы данных, описывающие некоторые стандарты, спецификации, документации (например, список кодов ошибок компилятора с пояснениями, таблицу ASCII c символами и их кодами, список всех стран с кодами из стандарта ISO 3166-1 и т.д.). В любом случае, такие данные могут быть использованы для уточнения или наоборот обобщения имеющихся сведений. На их основе строятся специальные сущности, интерпретирующие входные данные в удобную форму при помощи сопоставления с данными, полученными из открытых источников. Датасеты чаще всего распространяются в одном из наиболее популярных форматов текстового представления информации – JSON, XML, CSV, YML. Также иногда предоставляют файл с базой данных (с одной или несколькими таблицами), например в формате .sqlite3.
- Парсинг сайтов. Это процесс считывания открытой информации со страниц в интернете при помощи анализа HTML разметки. Это может производиться при помощи большинства современных языков программирования (ЯП) множеством различных способов. Подходы могут основываться на простой отправке запросов и получении HTML разметки либо на реальной симуляции работы браузера с возможностью интерактивных взаимодействий. Искомые данные могут находиться либо применением регулярных выражений, либо при помощи парсинга HTML разметки и нахождения нужных тегов по CSS селекторам. При том, парсинг сайтов может проводиться либо единовременно при создании статической базы данных, либо постоянно (с некоторыми интервалами) при штатной работе сервиса для поддержания актуальности данных. Парсинг используется для получения тех данных, которые не выложены в открытый доступ в более удобном формате, так как это более ресурсоёмкий процесс, чем работа с файлами в файловой системе.
- Открытые API – веб-сервисы, предоставляющие доступ к информации при помощи ответов на запросы в определенном формате. Чаще всего предоставляется какой-то URL адрес и правила формирования запроса. Ответ также чаще всего возвращается в формате JSON, API нередко работают по архитектуре REST. Данный формат доступа к открытым данным чаще всего используется в течение всей работы приложения. Однако необходимо кешировать ответы API, чтобы не перегружать обрабатывающие сервера и не провоцировать бан.
- Пакеты NuGet. Некоторые сервисы, предоставляющие API, также выпускают библиотеки для некоторых языков программирования (или платформ) для более удобного использования. Данный подход увеличивает простоту интеграции запросов API в систему и также облегчает использование. Удобным менеджером пакетов является библиотека пакетов NuGet для .NET. Этот менеджер пакетов по умолчанию встроен в интерфейс интегрированной среды разработки Microsoft Visual Studio.
Все перечисленные информационные ресурсы и способы получения данных были так или иначе использованы в разработке системы. Например, использовался NuGet пакет IsDayOff, предоставляющий удобный доступ к API одноименного сервиса и позволяющий определять, являлся ли указанный день выходным по производственному календарю.
После обработки исходной информации и составления датасета его необходимо сохранить в файловую систему (или на удаленный ресурс). Это требуется для того, чтобы при возникновении необходимости повторного обучения алгоритмов не приходилось снова преобразовывать все данные. Существует довольно много форматов хранения структурированных данных на диске. Рассмотрим некоторые наиболее популярные из них:
- XML – теговый формат хранения структурированных данных. Предоставляет широкий спектр возможностей, но заметно увеличивает размер файла из-за громоздкости синтаксиса;
- JSON – дословно объектная нотация языка JavaScript. Поддерживает довольно простой и при том гибкий синтаксис, это популярный формат для передачи данных в интернете, во многих языках для доступа информации в нем даже не требуется изначально знать структуру данных. Однако он тоже довольно значительно увеличивает размер файла в угоду типизации и структурированности и больше подходит для передачи небольших объемов информации, нежели хранения больших датасетов.
- YML – менее популярный формат данных, значительно уменьшает размер выходных файлов за счет упрощенности синтаксиса. Однако служит он скорее альтернативной JSON, так как в синтаксисе довольно часто используется перенос строки, что сделает большой датасет файлом со слишком большим числом строк. Возможно, это не повлияет на производительность, однако для визуального восприятия такой формат довольно неинтуитивен.
- CSV – наиболее простой табличный формат данных, не поддерживающий сложной структурированности, зато тратящий наименьшее количество места на одну запись. Также поддерживает возможность сохранения названий полей (столбцов). Он наиболее удачно подходит для хранения больших объемов данных.
Полученный в результате данного этапа датасет был сохранен в файловую систему в формате CSV, так как не требовалось высокой структуризации данных, и каждую запись можно было представить как вектор значений.
Машинное обучение защиты от скликивания рекламы
Для целей машинного обучения в данном проекте был выбран фреймворк ML.NET, который является современным инструментом, разработанным под .NET Core/5+, предоставляющим широкий спектр функций, полезных на разных этапах машинного обучения: загрузку данных из датасета, их фильтрацию, нормализацию, различные методы машинного обучения. Также полученную в результате машинного обучения модель можно сохранить в файловую систему в формате .zip и загрузить обратно, а также создать на ее основе объект, отвечающий за работу метода машинного обучения и возвращающего результат его работы (predictor, англ. предсказатель). Также очень ценной для нашей работы особенностью этого фреймворка является широкий ассортимент функций сериализации (приведения к унифицированному, закодированному виду – числовому значению) и нормализации (распределения множества значений в определенном числовом промежутке).
Вдобавок платформа ML.NET предоставляет широкий ассортимент методов машинного обучения, выбор из нескольких алгоритмов для каждого метода и возможность интеграции новых алгоритмов, в том числе из таких популярных библиотек машинного обучения как TensorFlow и ONNX. Среди методов машинного обучения, доступных по умолчанию при установке ML.NET можно перечислить следующие методы:
- Классификация и категоризация (например, разделение отзывов по их характеру);
- Регрессия, прогноз непрерывных значений (например, прогноз цен на недвижимость в зависимости от её параметров);
- Обнаружение аномалий (например, идентификация мошеннических денежных переводов);
- Рекомендации (например, системы построения предложений в интернет-магазинах);
- Временные ряды, последовательности (например, маркетинговые прогнозы, предсказания температуры воздуха);
- Классификация изображений (например, определение характера выражения лица и пола по фотографии).
Для наших целей был выбран алгоритм k-средних (k-means) метода кластеризации (clustering) машинного обучения. Он содержится в пакете ML.NET по умолчанию, также большинство необходимых нам средств сериализации и нормализации интегрированы в нее (остальные средства подготовки данных были применены в предыдущем пункте). Также данная платформа поддерживает необходимый функционал потоковых предсказаний на основе одного объекта, выносящего решения.
Также в проекте было использовано несколько других технологий, не так сильно повлиявших на ход реализации или являющихся классическими, рекомендованным в своих областях. Например, в качестве поставщика данных был использован пакет Microsoft.EntityFrameworkCore, для тестирования использовался фреймворк Microsoft.VisualStudio.TestTools.UnitTesting, а для создания визуального распределения сессий по кластерам использовалась классическая библиотека System.Drawing. Перечисленные пакеты были добавлены в проект через менеджер пакетов NuGet.
Выбранный стек технологий не является единственно верным, однако он наиболее подходит для поставленной задачи. Ключевыми факторами при выборе подходов были не только бесплатный доступ и свободное использование, но также функциональность, надежность и доверие к технологии.
Методы машинного обучения для реализации сервиса
Для целей определения ботов необходимо анализировать параметры сессий и на основе них выносить решение о характере сессии. То есть, надо, получая на вход набор характеристик, классифицировать их как наиболее характерные для одного из выходных классов. Данная задача может быть решена при помощи машинного обучения. Рассмотрим основные методы машинного обучения:
- Нейронные сети. Это набор алгоритмов, имитирующих работу головного мозга человека. Состоят из нейронов, объединенных в слои и синапсов (связей между ними). Данные обрабатываются последовательно слева направо от входного слоя, последовательно проходя скрытые слои НС, и возвращаются в качестве значений нейронов выходного слоя. Нейроны внутри одного слоя могут обрабатывать информацию параллельно, обработка слоями выполняется последовательно. Нейросети применяются в множестве отраслей для целого спектра задач. Например, для машинного перевода, классификации характера текста, анализа рисков и т. д.
- Дерево решений. Алгоритмы, относящиеся к данному методу, классифицируя объекты, последовательно проверяют некоторые их параметры и в зависимости от результатов проверки выбирают дальнейший путь проверок. Последняя проверка приводит к листу дерева решений, который определяет принадлежность проверяемого объекта к одному из классов. Одиночному дереву решений иногда предпочитают «Случайный лес» – набор случайным образом созданных деревьев решений с разными наборами атрибутов. В таком лесу каждое дерево независимо выносит решение, и выбирается решение, которое станет самым популярным в лесу. Одиночные деревья применяются при автоматическом обслуживании клиентов (предоставление доступа к базе знаний, основываясь на ответах о проблеме клиентов), при прогнозировании значений цен и выборе объема выпускаемой продукции. «Случайный лес» – набор алгоритмов с наиболее широким спектром применения. Они позволяют находить скрытые связи в свойствах объектов.
- Поиск ассоциативных правил – метод, относящийся к обучению без учителя[11] и позволяющий находить скрытые отношения между переменными. Самый распространённый пример применения – построение рекомендаций в интернет-магазинах на основе составленной корзины и истории покупок.
- Кластеризация. Это тоже метод обучения без учителя, позволяет разбивать наборы данных на группы, называемые кластерами, на основе вектора характеристик каждого экземпляра данных. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Количество полученных групп либо задаётся на вход алгоритму, либо заранее неизвестно. Примеры использования – сегментирование пользовательской аудитороии, рекомендация статей в журналах.
Легко видеть, наиболее походящим для поставленной задачи методом машинного обучения является кластеризация. Форма обучения хорошо встраивается в систему, так как параметры анализируемых сессий легко могут быть представлены как вектор характеристик. Также логично использовать этот метод как наиболее популярный в задачах разбиения пользователей [12].
Кластеризация для поиска ботов
Существует множество алгоритмов кластеризации, все они принимают n-мерный вектор числовых характеристик на вход и на их основе определяют ближайшие объекты. При том, все характеристики расположены в одном числовом промежутке (чаще всего [0, 1] или [-1, 1]). Существует множество алгоритмов кластеризации, чаще всего их разделяют на иерархические и плоские или на чёткие и нечёткие [13].
- Иерархические и плоские. Плоские алгоритмы лишь выполняют разбиение всего множества входных данных на непересекающиеся кластеры. Из-за рандомизации [12] начальных приближений в некоторых методах плоские алгоритмы могут быть недетерминированными, то есть даже при одинаковых входных данных в двух разных запусках алгоритма могут получиться отличные значения. Иерархические же алгоритмы строят древовидное разбиение на кластеры, где в корне находится всё множество данных, а в листьях – самые мелкие кластеры. Такие алгоритмы являются более ресурсоёмкими, но и представляют исследователю больше полезной информации. Также иерархические алгоритмы часто являются детерминированными, что тоже может представлять некую ценность [14].
- Чёткие и нечёткие. Чёткие алгоритмы кластеризации ставят в соответствие каждому объекту один из кластеров. Нечёткие же в свою очередь определяют вероятность вхождения каждого объекта в каждый из кластеров.
Для поставленной задачи кластеризации пользователей не требуется с какой-либо вероятностью относить сессии ко всем кластерам, достаточно отнесения к одному из кластеров, определяющему конкретную вероятность недоброкачественности сессии. Также не требуется иерархичности разбиения, а делать выбор в сторону иерархических алгоритмов только для достижения детерминированности среды неразумно, так как это влечет серьезные накладные расходы. Существуют и иные способы достичь этого. Таким образом, будем выбирать алгоритм среди чётких алгоритмов плоского разбиения.
Алгоритм кластеризации k-средних
Для данной работы был выбран алгоритм k-средних (k-means). Он относится к алгоритмам квадратичной ошибки (плоский, чёткий), подразумевает минимизацию среднеквадратичной ошибки по формуле 2.
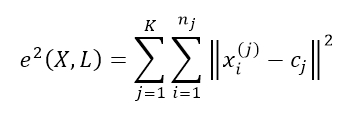
Здесь cj — «центр масс» кластера j, x – расстояние от экземпляра данных xi до cj. Этот алгоритм строит заданное число кластеров, расположенных как можно дальше друг от друга, итеративно подбирая их центры. В качестве критерия остановки работы алгоритма может выступать критерий минимизации ошибки. В алгоритме k-средних алгоритм не переходит на n+1-ю итерацию и возвращает полученное распределение, если распределения, полученные в n-ной и n-1-й итерации неотличны. Недостатком данного алгоритма является необходимость изначального задания количества кластеров.
Методы оценки кластера
В некоторых случаях заранее невозможно определить выходное количество кластеров, так что необходим метод определения оптимального их количества. Среди наиболее популярных методов побора можно выделить метод локтя и анализ силуэта.
- Метод локтя. Данный метод основывается на последовательном проведении кластеризации с увеличением количества кластеров. На каждой итерации измеряется сумма среднеквадратичных расстояний элементов кластеров до центров кластеров. Хорошим количеством кластеров считается то, на котором произошел перелом, появился «локоть» на графике среднеквадратичных отклонений.
- Анализ силуэта. Используется для анализа степени разделенности кластеров. В противопоставление методу локтя верифицирует не критерий схожести элементов внутри каждого из кластеров, а критерий различности между разными кластерами. Для всех экземпляров данных высчитывается коэффициент, показывающий близость к включающему их кластеру и дальность от других. Оптимальным считается количество кластеров, в котором разделение наиболее существенно.
Для данной работы более существенным критерием является схожесть пользователей внутри каждого кластера, так что подбирать будем методом локтя.
Архитектура нашей системы защиты от скликивания
Архитектура разрабатываемого сервиса подразумевает наличие клиентской и серверной частей, обменивающихся запросами без непосредственного участия пользователя.
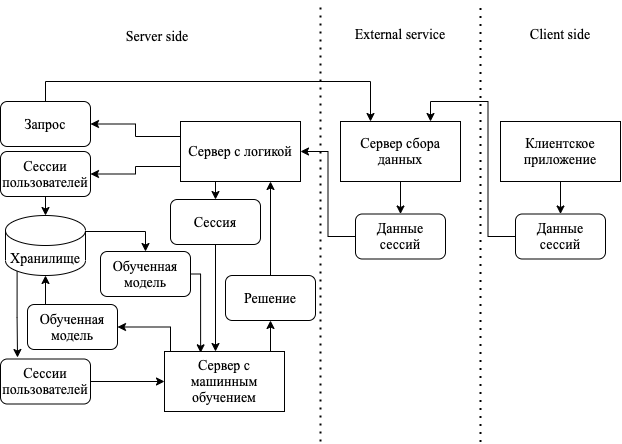
На Рисунке 1 схематически изображена архитектура всей системы. Справа помещена клиентская часть. На ней располагается сценарий, считывающий поведение пользователя и остальную информацию о его сессии. Данный сценарий активируется при заходе на страницу, анализирует необходимую информацию и отсылает ее на сервер с внешним сервисом Matomo, который описан посередине рисунка. В левой части Рисунка 1 расположены сервисы серверной части. Здесь под “сервером с логикой” подразумевается набор сервисов, включенных в основной пайплайн анализа и блокировки. Этот сервер с логикой тоже построен на основан на архитектуре .NET Core Workers, хоть и написан под .NET Framework. Он циклично раз в некоторый промежуток времени посылает запросы на сервер с внешним сервисом, хранящий данные недавних сессий пользователей.
Ответы возвращают на сервер с логикой сырые данные, требующие многоступенчатой доработки и анализа для использования в рабочих целях. Там они обрабатываются, параллельно записываются в базу данных и используются в пайплайне анализа-блокировки по прямому назначению. Под хранилищем здесь подразумевается не только база данных, но и файловая система, директория сборки, в которой можно хранить некоторые дополнительные файлы, не подходящие для хранения в базе данных. Под сервером машинного обучения подразумевается некая программа с необходимым функционалом, поддерживающая gRPC запросы. Для процесса первоначального обучения модели сервер с машинным обучением запрашивает данные сессий из хранилища и обрабатывает их в соответствие со внутренней логикой.
Файл, содержащий обученную модель, сохраняется в файловую систему как часть хранилища. Для штатной работы сервис запрашивает обученную модель из хранилища. В процессе штатной работы сервер с логикой из основного пайплайна запрашивает решение по поводу некоторой сессии, сервер с машинным обучением вычисляет ответ и возвращает его в запрашивающую точку. Некоторые из описанных частей системы уже реализованы, в основном разрабатываемый функционал затрагивает сервер с машинным обучением.
Рассмотрим архитектуру сервера с машинным обучением. Она схематически представлена на Рисунке 2.
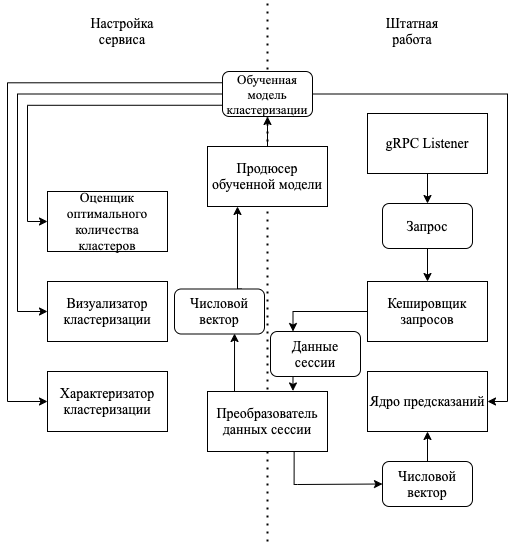
Весь сервис условно можно разделить на две независимые части, используемые на разных этапах разработки:
- Настройка сервиса – набор worker’ов и их функциональных частей, служащих для извлечения всей необходимой информации из свойств обученной модели и оптимальной её корректировки. Части сервиса, расположенные в данной области, не будут использованы при штатной работе сервиса. Изначально создаются датасеты для обучения и верификации результатов. Преобразователь данных сессии при помощи своей внутренней логики производит необходимые вычисления и преобразует исходные данные сессии в числовой вектор для подачи на вход алгоритму машинного обучения. Эти данные передаются в продюсер обученной модели, который на этапе настройки обучает модель и сохраняет её в хранилище (файловую систему). Далее продюсер обученной модели загружает её; позднее она используется для построения метрик, помогающих корректировать и интерпретировать её. Оценщик оптимального количества кластеров вычисляет метрики внутрикластерного и межкластерного расстояний и сохраняет их в файловую систему. Визуализатор кластеризации создает наглядный график-псевдопроекцию распределения сессий между кластерами. Характеризатор кластеризации использует хранимую процедуру базы данных для построения метрик качества сессий, попавших в разные кластеры для определения значения кластеров;
- Штатная работа – части сервиса, задействованные при тестировании его потоковой работы и после регистрации его как службы Windows на сервере. Сюда входят модули, необходимые для обработки запросов, обслуживания логистики их обработки, модуль для преобразования входных данных, модуль для формирования обученной модели машинного обучения и модуль конвейерного вынесения решений по сессиям на основе преобразованных входных данных. Кешировщик запросов нужен для обеспечения равномерной нагрузки на сервис. Он будет накапливать запросы, посылая сессии на обработку порционно. Ядро предсказаний будет порционно принимать преобразованные данные и единовременно возвращать решение сразу по всем проанализированным сессиям.
Как видно, два модуля – преобразователь данных сессии и продюсер обученной модели – используются в обоих частях сервиса. Как ни странно, они разрабатываются и настраиваются первыми, так как необходимы для работы большинства остальных модулей. Преобразователь данных итеративно обрабатывает данные, с каждой итерацией понижая уровень их абстракции, проходя в том числе фильтрацию, трансформацию и нормализацию, что в конечном итоге приводит данные в вид числового вектора. При первоначальной настройке сервиса продюсер обученной модели принимает преобразованные данные в виде числовых векторов и на их основе обучает модель, чтобы потом иметь возможность доступа к ней без необходимости повторного обучения. Как видно, эти два модуля изначально позволяют сформировать объект исследований и ядро сервиса машинного обучения – обученную модель.
Сбор данных о пользователях с сайтов клиентов
Сбор данных сессий пользователей производится в несколько этапов. После инициализации DOM[13] вызываются скрипты, вычисляющие дополнительные параметры сессии пользователя и основной скрипт веб-аналитики. После этого вызывающие скрипты собирают данные при помощи API Matomo, и они отправляются на сервер. Вызов всех сторонних сценариев производится при помощи вызывающих скриптов, расположенных на сайте в форме тегов GTM.
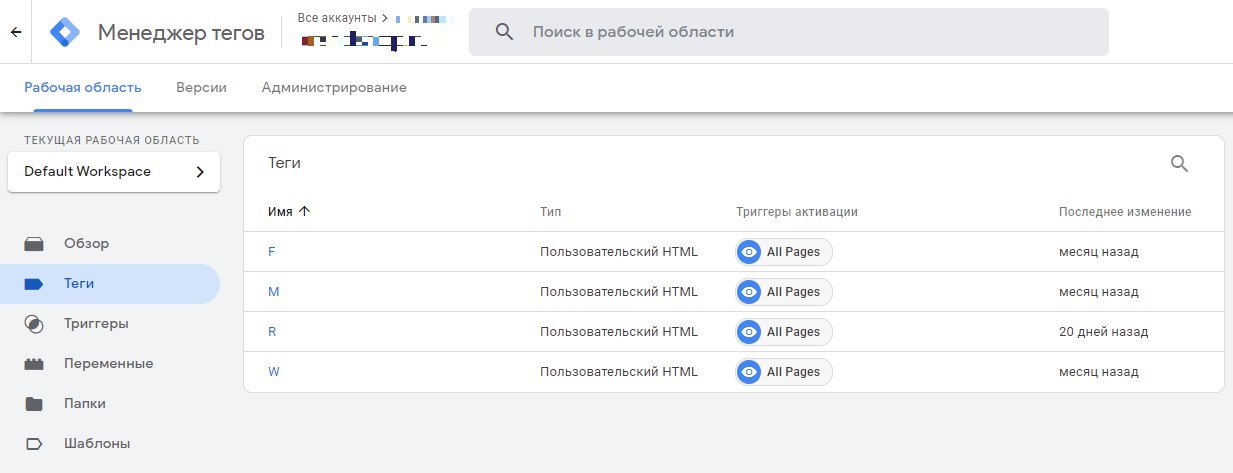
Как видно на Рисунке 3, в нашем случае Google Tag Manager размещает на сайте 4 тега – Fingerprint, вычисляющий отпечаток пальца браузера, Matomo – скрипт веб-аналитики, Google ReCaptcha v3, дающий оценку пользователя по многим параметрам его поведения в интернете и Webdriver – скрипт, определяющий наличие средств автоматизации тестирования при заходе на сайт.
Определение пользовательских переменных, благодаря которым дополнительные данные передаются в Matomo вместе с остальными параметрами сессии, производится при помощи добавления специальных записей в глобальный стек document._paq. Эти записи считываются скриптом Matomo и интерпретируются в зависимости от содержания. В записи содержится следующая информация:
- Название вызываемой операции (в нашем случае – “setCustomVariable”);
- Название пользовательской переменной;
- Индекс пользовательской переменной (они должны быть зарегистрированы в Matomo заранее);
- Значение данной переменной.
Бывает такое, что скрипт веб-аналитики не успевает инициализироваться и некоторые пользовательские переменные записываются «в никуда». Также возможны случаи, при которых пользовательские переменные не вычисляются до того, как пользователь закрывает страницу, в обоих случаях набор данных о пользователе не будет полным. Такое поведение может проявляться непредсказуемо в зависимости от того, какое ПО еще установлено на защищаемом сайте. Другие скрипты JavaScript могут вызывать ошибки, отключающие выполнение сценариев на сайте на какое-то время, а специальные скрипты-оптимизаторы могут управлять порядком запуска скриптов, нарушая заданную логику.
Наличие некоторых из тегов на Рисунке 3 обусловлено необходимостью сбора дополнительных фактов о сессиях пользователей, которые планируется использовать в процессе машинного обучения. Это необходимая опора, позволяющая однозначно выносить решение по поводу качества некоторых сессий пользователя. Данная особенность будет использоваться при оценке результатов для определения качества получившихся в результате кластеризации групп. Особую ценность представляют сессии, чьё качество получилось определить однозначно благодаря вычислению формальных параметров, ведь это чаще всего граничные случаи, возникающие реже других. Также частоту появления таких сессий факторы причины, описанные в предыдущем абзаце.
Подготовка данных для поиска скликивающих ботов
Подготовка данных заключается в последовательном их преобразовании и насыщении смыслом. Таким образом, с каждой итерацией обработки данных у них понижается уровень абстракции. Первая итерация выполняется при сборе данных и записи их во временное хранилище Matomo. Вторая – при получении данных из Matomo на сервере с логикой, дополнительной обработки и записи результата в хранилище – базу данных. Ответственность за дальнейшие этапы обработки и анализа сессий ложится на сервис с машинным обучением. На последнем этапе получится наиболее информативный с точки зрения алгоритмов машинного обучения формат представления данных – числовой вектор.
Первый этап обработки сессий в пайплайне машинного обучение – это пояснение данных. На данном этапе сырые данные анализируются по отдельности и преобразуются в видоизмененные формы себя же. Есть данные, которые легко формализовать, не будем заострять на них внимание.
Здесь важно найти параметры исходных данных, не имеющие объективного смысла для алгоритма машинного обучения. Чаще всего это могут быть строковые представления чего-либо. Например, в исходных данных содержалась информация о стране и городе (локаль), откуда был совершен заход на страницу. Просто название страны и города в форме набора символов не дает почти нисколько информации алгоритму машинного обучения, так как его текущее представление не отражает сути.
На основе данного умозаключения можно сформулировать общий принцип манипуляций над данными, производимых на данном этапе их подготовки: «Надо привести данные к такому виду, чтобы их форма отражала их суть». Взглянем на таблицу с исходными данными на Рисунке 4.
Здесь записи располагаются в строках, а столбцы расположены вертикально. Видно, что данные не всегда однородны, встречаются пропуски, много полей, содержащих текстовую информацию. Числовые поля можно не преобразовывать на данном этапе, так как они уже представляют собой какую-либо меру. Ниже приведены некоторые способы пояснения строковых данных, примененные в данной работе.
- Преобразование в перечисление. Иногда при анализе набора данных можно выделить некоторые закономерности. Например, существуют поля, содержащие не уникальную строку, обозначающую что-либо, а одну из возможных строк. Во время анализа было выделено несколько таких полей, некоторые из них представлены на Рисунке 5.
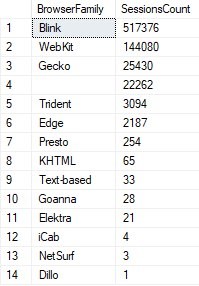
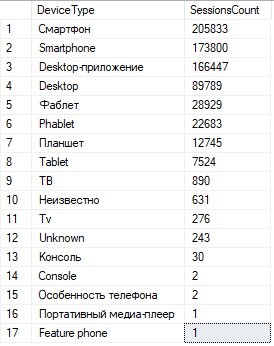
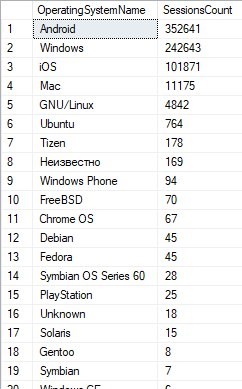
Рисунок 5. Поля с альтернативными значениями
На Рисунке 5 представлены самые частые значения некоторых полей и количество сессий, где поле имеет такое значение. При том можно предусмотреть члены перечисления только для самых популярных опций, остальные, например, классифицируя к члену Other.
- Преобразование даты-времени. Чаще всего время закрытия сессии может иметь значение и должно быть интерпретировано. Время суток можно закодировать как номер секунды в сутках, так как от времени суток зависит период трафика. Сама дата сериализуется сложнее. Просто дата или номер дня в году не несет смысловой нагрузки, могущей характеризовать сессию. Также не сразу очевидно, что день недели (или его номер) тоже не играет роли. Чаще всего характер трафика и рекламы отличается по выходным, праздничным и рабочим дням. Для выяснения, рабочий ли день в соответствие с производственным календарем, будем использовать библиотеку IsDayOff. Можно прибегнуть к инструментам парсинга и обновлять информацию напрямую с портала министерства труда, однако этот способ ненадежен – разметка на странице календаря может измениться, и парсер придется перенастраивать. Данный подход не оптимален, так как может повлечь непредвиденное поведение системы после возможного изменения разметки сайта, подвергнутого парсингу. Пакет IsDayOff предоставляет удобный доступ к API одноименного сервиса с возможностью кеширования результатов в памяти. Это позволят понизить время исполнения сервиса и нагрузку на внешний API-сервис. Таким образом, дата-время отображаются парой значений номера секунды в сутках и показателем, были ли эти сутки выходными.
- Преобразование IP, ASN и Subnet. IP адрес часто представляют в виде 4-х двоичных байт. Данный подход предполагает конкатенацию всех 4-х байт и принятие получившегося результата как одного 32-битного числа. Это число просто записывается в переменную типа UInt32, так как все IP адреса находятся ровно в диапазоне допустимых значений данного типа. Такая же операция проводится и с ASN, на выходе получается переменная UInt32. Так как адрес подсети частично соответствует IP адресу, можно сохранить только степень соответствия, привязав её к количеству битов в маске подсети. В таком случае, Subnet приобретет значение маски подсети и будет храниться в качестве количества бит в ней, а всю информацию о подсети, связанную с адресом, будет нести в себе параметр IP.
- Преобразование в буль наличия. Данное преобразование используется в качестве крайней меры, если не удалось придумать другой более подходящий способ насыщения значения информацией. Подразумевает замену некоторых полей на поля, определяющие их существование. То есть, появляется булево поле, принимающее значение True, если изначально поле содержало некоторое значение, отличное от null, и False в иных случаях. Также стоит отметить, что не рекомендуется применять данный метод к тем полям, чьё наличие или отсутствие не несет за собой никакого смысла. Под булем наличия также может пониматься буль соответствия, например, в выходном наборе присутствует буль, определяющий, содержал ли referrer ссылку с тем же хостом, что и первая страница сессии.
На данном этапе вместо каждой строки исходного датасета стоит числовой вектор, далее все данные анализируются и изменяются в числовом виде. Не все поля исходного набора данных получили свое отражение в поясненном датасете. Не перенесенные поля либо не имеют видимого независимого влияния на результат, либо не удалось придумать подходящее преобразование для них. Например, в поле с датой-временем начала сессии нет необходимости, потому что присутствуют поля, отражающие дату-время конца сессии и ее длину. А поле с названием провайдера, возможно, имеет смысл, но соответствующего преобразования для него придумать не получилось.
Фильтрация данных и заполнение пропущенных значений
Данные два этапа – первые, выполняемые при помощи фреймворка ML.NET и контекста машинного обучения. Объект типа MlContext содержит в себе так называемые каталоги – наборы функций и моделей, служащих разным целям машинного обучения. Например, в каталоге Data есть функции для загрузки датасетов, их сохранения, а также некоторых операций с обученной моделью. Также каталог Data содержит функции для фильтрации данных на основе полей с числовыми значениями. Единственная использованная здесь функция – FilterRowsByColumn, позволяющая отсеивать те строки, в которых значения числовых полей с плавающей точкой не входят в заданные рамки. Этот метод подходит для большинства наших полей, так как для них заранее известны допустимые рамки. Например, для поля с номером секунды в сутках нижней границей будет являться 0, а верхней (исключающей) – 86400 по количеству секунд в сутках. Аналогично 4294967296 будет верхней границей для IP и ASN как 232, а 32 – для SubnetMaskBits.
Замена пропущенных значений в основном проводится на предыдущем этапе пояснения данных, однако каталог Transform объекта типа MlContext предоставляет функции замены некоторых граничных (пропущенных или удовлетворяющих заданному условию) значений. Например, можно заменять пропущенные значения минимумом, максимумом или средним из всех значений данного поля.
Нормализация данных
На данном этапе анализируется уже полученный числовой вектор. Требуется унифицировать его, масштабировать все значения таким образом, чтобы они в одинаковой мере влияли на результат. Это обязательный этап подготовки данных для анализа при помощи машинного обучения. Чаще всего он заключается в пропорциональном масштабировании значений поля в разных записях таким образом, чтобы максимальное значение стало 1, минимальное – 0, а все остальные поместились бы в промежуток от 0 до 1. Также иногда используют систему, при которой значения распределяются в пределах от -1 до 1. Для разных целей могут применяться разные типы масштабирования.
В данной работе помимо пропорционального масштабирования на основе минимального и максимального значений используется также логарифмическое масштабирование на основе среднего значения. Оно используется, например, в таких полях, как длительность визита, количество действий за визит, количество посещений и номер посещения за день. Здесь значения могут разниться очень сильно, при том, не имеет особой разницы, например, 1000 секунд длился визит или 10000, однако разница между 10 и 100 секундами существенна. Таким образом, логарифмическое масштабирование с большей чувствительностью относится к одинаковым изменениям в малом диапазоне значений, нежели в больших значениях.
Дискретные значения, полученные в результате преобразований перечислений и булевых переменных нормализуются пропорционально, при том булевы переменные, изначально имевшие значение False, примут значение 0, а True преобразуются в 1. Все функции, необходимые для нормализации значений датасета, присутствуют в каталоге Transforms объекта MlContext.
Обучение модели
Бо́льшая часть работы, относящейся к машинному обучению в проекте, написанном под фреймворк ML.NET, производится при помощи специального объекта контекста машинного обучения MlContext. Он создается в начале работы программы и передается внутри нее в течение всей ее работы.
Класс MlContext имеет один публичный конструктор, содержащий опциональный параметр – целочисленное значение. Этот параметр называется seed (от англ. зерно), он используется для создания детерминированного характера среды. Дело в том, что в процессе машинного обучения много применений нашли генераторы случайных чисел, использующиеся для самых разных целей. Они требуют на вход некоторое зерно, seed, при присутствии которого всегда после каждого перезапуска программы они будут выдавать одинаковую последовательность случайных чисел. Если этого не сделать, от запуска к запуску результаты работы могут отличаться, даже при одинаковых входных данных. Для того, чтобы гарантировать одинаковую работу при каждом запуске, укажем некоторое значение при создании объекта MlContext.
Объект контекста машинного обучения позволяет проводить множество операций над наборами данных, моделями и даже другими операциями. Среди ключевых принципов, на которых строится вся работа с ML.NET есть работа с трансформерами (ITransformer). Они преобразуют некоторые входные данные и возвращают «трансформированные» данные. Частым подходом является составление цепочек трансформеров (TransformerChain), являющих собой пайплайны подготовки данных и/или обучения модели. Внутри одного приложения пайплайн подготовки данных и пайплайн обучения модели можно объединить в одну TransformerChain, что облегчит в последствие создание ядра предсказаний (PredictionEngine) на её основе.
Однако в одну цепочку трансформеров можно добавить только функции из каталога Transforms контекста машинного обучения. Так что функции фильтрации, расположенные в каталоге Data, необходимо сохранять отдельно и использовать перед применением получившегося пайплайна.
После получения пайплайна подготовки данных необходимо в конец него добавить алгоритм машинного обучения и обучить модель при помощи заготовленных преобразованных и отфильтрованных данных в формате IDataView. Обученная таким образом модель будет содержать в себе предварительные функции нормализации, помимо самой кластеризации. Таким образом, их не надо будет применять дополнительно. Полученная модель может быть сохранена в .zip архивный файл в файловую систему или на удаленный ресурс. После загрузки модель сразу же может использоваться без необходимости повторного обучения.
В разработанном сервисе реализован класс ClusteringResultsPlottingWorker, наследованный от BaseService, определяющего фоновую задачу, так называемую работу (work). Логика его работы такова: из базы данных берутся сессии для анализа и сразу преобразовываются для машинного обучения, обученная модель загружается из файловой системы и делается распределение сессий из БД по кластерам. Далее из обученной модели извлекаются центроиды (показания средних значений по всем входным параметрам для сессий в одном кластере), по предсказаниям определяются «координаты» точке на карте кластерного распределения.
На основе полученных данных строится псевдо-проекция распределения сессий по кластерам. Проекция не настоящая, так как исходное пространство имеет 27 измерений, и любая проекция была бы слишком запутанной. При том она не отражала бы реальную ситуацию распределения лучше, чем это делает псевдо-проекция.
Полученные точки наносятся на систему координат, оптимизируя ее масштаб под координаты граничных точки распределения. Для наглядности разные кластеры отмечены разными цветами и разными формами. Получившееся распределение изображено на Рисунке 6.
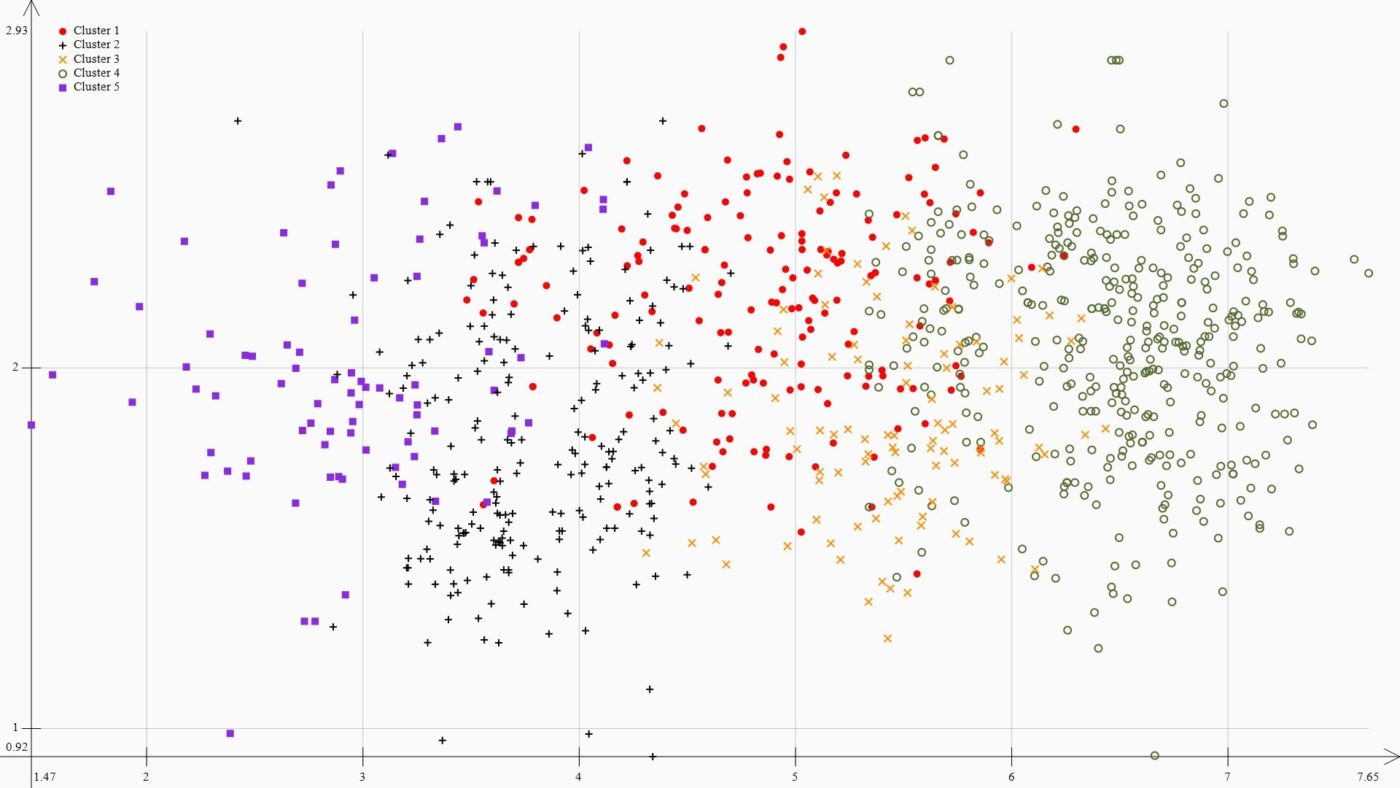
Данная метрика полезна для визуальной оценки качества распределения. На первый взгляд может создаться впечатление, что кластеры не разделены и точки перемешаны. Однако не стоит забывать, что это лишь псевдо-проекция и расположение точек весьма условно. С другой стороны стоит обратить внимание на то, что точки внутри кластеров расположены кучно, распыление не очень большое. Это может свидетельствовать о низком среднеквадратичном внутрикластерном расстоянии (расстоянии от центроида кластера до конкретной точки), что является хорошим признаком качественного кластерного распределения.
Корректировка полученных результатов
Данный этап заключается в корректировки модели машинного обучения на основе полученных результатов. Важно отметить, корректировка модели проводится хронологически не после предыдущего этапа, а итеративно сменяя его.
При корректировке модели машинного обучения может изменяться не только модель входных данных, но и пайплайн нормализации. Также при применении метода кластеризации отдельному анализу и корректировкам подлежит параметр количества кластеров
Первоначальный пайплайн подготовки данных не включал логарифмическую нормализацию, однако после нескольких сеансов обучения было обнаружено, что строки данных, имеющие значительные логические отличия, не теряли их, находясь в форме выходного вектора целочисленных значений. Был проведен анализ и выявлено неожиданное поведение алгоритмов нормализации. Слишком большие значения таких параметров как длина сессии, количество действий во время сессии (и других параметров, теперь анализируемых логарифмически) не отбрасывались на этапе фильтрации, так как теоретически были допустимыми. Несмотря на допустимость высоких значений, не имело особого значения, какое именно число было в параметре, если оно было выше определенной точки, однако различия в низких значениях играли большую роль даже при разнице в 1.
В каталоге Transforms объекта MlContext содержится несколько заготовленных функций нормализации, среди которых есть функция NormalizeLogMeanVariance, предоставляющая необходимый функционал. Она производит нормализацию данных на основе вычисленного среднего значения и дисперсии логарифма данных.
В выбранном алгоритме машинного обучения – k-средних – количество кластеров задается алгоритму на вход, то есть является обязательным параметром. Однако чаще всего исходя из данных, невозможно сразу определить оптимальное количество кластеров. Отличие кластеризации от классификации в том, что алгоритм не относит каждый экземпляр входных данных к одной из заранее заготовленных групп, а распределяет все входные данные между нужным количеством кластеров оптимальным способом.
Существуют специальные алгоритмы, основанные на среднеквадратичных внутрикластерном и межкластерном расстояниях. Платформа ML.NET предоставляет удобный инструмент для построения метрик кластеризации. Объект MlContext в каталоге Clustering содержит метод Evaluate, который создает эту метрику. Она содержит два числовых поля с плавающей точкой – среднеквадратичное внутрикластерное расстояние и среднеквадратичное межкластерное расстояние. Для построения таких метрик и применения их в алгоритмах подбора количества кластеров был создан отдельный Worker – ElbowMethodWorker.
- Метод локтя. Это самый простой и широко распространенный способ подбора количества кластеров при кластеризации. Он заключается в составлении метрики, определяемой, как формула E= I / O
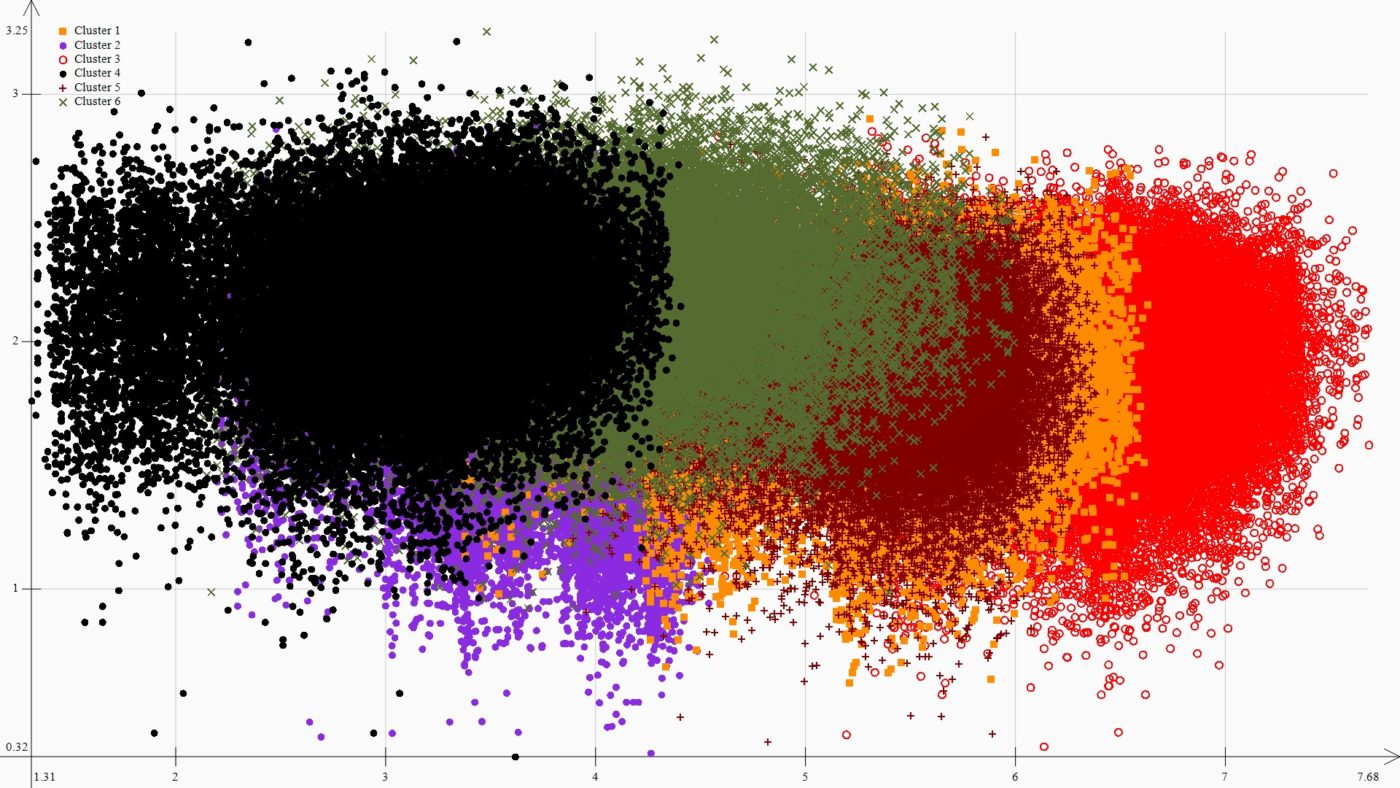
Здесь E – мера кластерной группировки по методу локтя, I – среднеквадратичное внутрикластерное расстояние, а O – среднеквадратичное межкластерное расстояние. По нескольким количествам кластеров вычисляется такая метрика и строится график зависимости этой метрики от количества кластеров. Оптимальное количество кластеров, находится на перегибе графика. Результат работы метода локтя представлен на Рисунке 7.
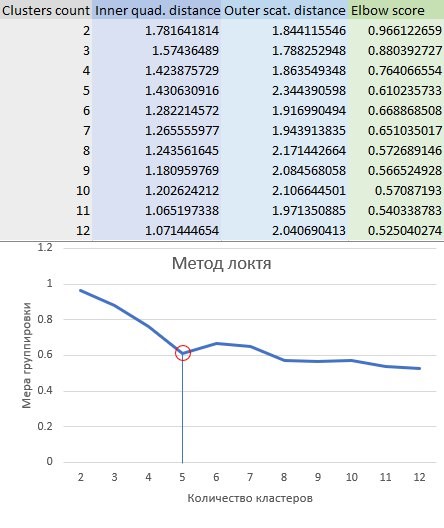
На графике отмечен перегиб на точке с пятью кластерами, можно считать, что метод локтя определил 5 кластеров как оптимальное количество для данного распределения. Однако на графике перегиб показан не очень ярко выраженно, возможно, верное количество кластеров – 8. На этот вопрос алгоритм локтя не может дать однозначного ответа, придется прибегнуть к другому методу.
- Метод силуэта. Это метод подбора количества кластеров, созданный как альтернатива методу локтя. Он основывается на тех же входных данных, но использует их немного по-другому, в следствие чего чувствительность метода повышается. Отношение, по которому строится метрика этого метода, описано в формуле S = ( O – I)/ MAX (O,I)
Здесь S – мера кластерной группировки по методу силуэта, I – среднеквадратичное внутрикластерное расстояние, а O – среднеквадратичное межкластерное расстояние. Метод предписывает искать пик на графике, составленном аналогично методу локтя. Такой график с исходными данными и отмеченным пиком показан на Рисунке 8.
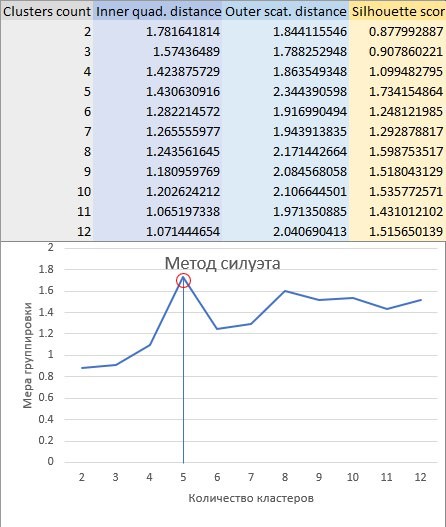
Легко видеть, метод силуэта намного более нагляден, чем метод локтя. После построения кривой силуэта не остается сомнений в оптимальном количестве кластеров. Хотя данный метод не опроверг предполагаемый вердикт метода локтя, было полезно его построить, чтобы убедиться в правильности решения.
Анализ полученных результатов алгоритма защиты от скликивания
Анализ результатов заключается прежде всего в оценке изменений по количеству обвинительных вердиктов при анализе и блокировке сессий. Для этого недостаточно двух подготовленных датасетов, и необходимо наладить доступ к хранилищу. В существующей части системы есть проект, представляющий слой доступа к данным (Data Access Layer, DAL), но его использование не представляется возможным в силу особенностей совместимости платформ .NET Framework, на котором написан слой с данными и .NET 5, на котором написан новый проект.
В виду сложившейся необходимости реализуем новый слой с данными для проектов на новых версиях .NET Core/5+. В качестве основного фреймворка-поставщика данных будем использовать Entity Framework Core (EFCore). Чтобы использовать существующую базу данных и в будущем не задумываться о сложных миграциях, для реализации слоя данных был выбран подход ручного переноса необходимых сущностей из базы данных в код. В общем EFCore похож на своего предшественника Entity Framework 6 (EF6), но он также имеет и ряд особенностей, которые необходимо учитывать. Перечислим некоторые из них:
- Нельзя передавать ни имя строки подключения, ни саму строку как параметр конструктора контекста. Контекст конфигурируется либо единожды при инициализации сервиса и передается от объекта к объекту в течение работы программы, либо каждый раз при создании для выполнения одного запроса. В первом случае создается специальный объект конфигурации со строкой подключения, а во втором алгоритм действий иной. В классе контекста переопределяется метод OnModelCreating и в нем определяется строка подключения к определенному типу СУБД и некоторые дополнительные параметры.
- Строку подключения теперь нельзя напрямую по псевдониму получить из файла конфигурации. В проектах .NET Framework файл конфигурации чаще всего называется app.config и содержит теги в xml-подобном виде, и строку подключения при создании контекста можно было указать по ее имени из конфигурации. В проектах .NET Core/5+ файл конфигурации – appsettings.json, и хотя там есть специальный раздел для строк подключения, нет никакого встроенного интерфейса взаимодействия с ними. Чтобы получить информацию оттуда, необходимо воспользоваться пакетом Microsoft.Configuration.Extensions и при его помощи загрузить конфигурацию из appsettings.json. Полученный объект конфигурации имеет специальный метод для доступа к строкам подключения – GetConnectionString(string name).
- Для того, чтобы контекст из базы данных мог возвращать объекты созданных моделей, их надо предварительно зарегистрировать в методе SetConfiguration. При том, необходимо указать, что за тип сущности описывается данной моделью (таблица, представление) и указать все необходимые параметры (например, для регистрации моделей, возвращаемых из хранимых процедур, требуется вызвать ToView(), чтобы указать, что это тип представления и HasNoKey(), чтобы не происходила попытка создания табличного типа без ключевого поля.
- Вызов хранимых процедур (ХП) производится через вызов метода context. Set с аргументом типа модели, возвращаемой из ХП и строкой запроса с параметрами в качестве аргумента метода.
Сложно судить о преимуществах и недостатках новой версии платформы из-за не очень большого опыта ее использования, однако новый подход позволяет более однозначно оценивать процессы, происходящие при подключении к БД и во время взаимодействия с ней. Также регистрация типов позволяет явно указать типы, гарантировано возвращаемые из БД.
Как было написано выше, для оценки качества кластеров необходимо получить из базы данных новый набор сессий, чтобы на их основе оценить качество сессий, попавших в разные кластеры.
Для этих целей была создана хранимая процедура БД, по набору Id сессий возвращающая некоторую комплексную оценку или метрику качества этих сессий. В эту метрику входит статус блокировки сессии, коэффициенты подозрительности и некоторые другие формальные параметры, позволяющие судить о качестве сессий.
Из базы данных было выбрано 1000 сессий, для них было построено распределение между кластерами по обученной модели. После этого для всех обработанных сессий была создана метрика качества (из ХП БД), все метрики с указанием номера кластера были сгруппированы и записаны в файл .csv для дальнейшего ручного анализа при помощи Microsoft Excel. Сводная информация была построена при помощи применения встроенных функций СУММЕСЛИМН, СУММЕСЛИ, СРЗНАЧЕСЛИ для фильтрации полного набора данных. Целью построения данной таблицы является определение средних или суммарных значений ключевых параметров для каждого из кластеров. Полученная метрика изображена на Рисунке 9.
На ней в верхней части расположена сводная таблица средних и суммарных показателей параметров сессий по кластерам. В некоторых столбцах ячейки помечены красным, тем хуже результат кластера в данном столбце, чем насыщеннее оттенок красного в ячейке с его результатом. Последний столбец отмечен цветами другой гаммы, там более зеленый цвет определяет более желательные заходы.
По суммарным показателям метрик лучшие результаты показали сессии из кластеров номер 3 и номер 5. Сессии, попавшие в эти кластеры, можно считать человеческими. Сессии из кластеров номер 1 и номер 2 имеют худшие результаты и скорее всего являются автоматизированными. А сессии, попавшие в 4-й кластер, не имеют однозначного вердикта и оставляют возможность для настройки чувствительности сервиса. Таким образом, анализ результатов доказал работоспособность созданного алгоритма и его пригодность для решения поставленной задачи.
Вывод
В процессе выполнения работы был разработан сервис, вычисляющий на основе данных сессий пользователей вердикт о необходимости блокировки. Логика разработана с использованием алгоритма машинного обучения кластеризации k-средних. Была создана система, отвечающая поставленным целям и штатно выполняющая свою задачу. Было проведено необходимое соответствующее тестирование и функционал проверен на устойчивость к ошибкам. Результат обработки тестовых данных был проверен, по нему составлена метрика и выявлены качества получившихся кластеров.
Список использованных источников
- Бизнес уходит в онлайн: как изменятся цифровые продажи после пандемии [Электронный ресурс] : портал. – Режим доступа: https://thebell.io/biznes-uhodit-v-onlajn-kak-izmenyatsya-tsifrovye-prodazhi-posle-pandemii, свободный. – (дата обращения 11.05.2021)
- B2B- и B2C-системы [Электронный ресурс] : портал. – Режим доступа: https://www.activetraffic.ru/wiki/b2b-i-b2c/#:~:text=B2C%20(Business%20to%20Consumer)%20%E2%80%93,%D1%82%D0%BE%D0%B2%D0%B0%D1%80%20%D0%B8%D0%BB%D0%B8%20%D1%83%D1%81%D0%BB%D1%83%D0%B3%D1%83%20%D0%B4%D1%80%D1%83%D0%B3%D0%BE%D0%BC%D1%83%20%D0%BF%D1%80%D0%B5%D0%B4%D0%BF%D1%80%D0%B8%D0%BD%D0%B8%D0%BC%D0%B0%D1%82%D0%B5%D0%BB%D1%8E., свободный. – (дата обращения 11.05.2021)
- Конверсия [Электронный ресурс] : портал. – Режим доступа: https://myacademy.ru/baza-znanii/glossarii/konversiya, свободный. – (дата обращения 11.05.2021)
- ClickCease. Product [Электронный ресурс] : портал. – Режим доступа: https://www.clickcease.com/features.html, свободный. – (дата обращения 11.05.2021)
- Яндекс Справка. Площадки, на которых запрещены показы. [Электронный ресурс] : портал. – Режим доступа: https://yandex.ru/support/direct/campaigns/blocked-sites.html, свободный. – (дата обращения 12.05.2021)
- Microsoft Docs. MLContext(Nullable<Int32>) Constructor [Электронный ресурс] : портал. – Режим доступа: https://docs.microsoft.com/en-us/dotnet/api/microsoft.ml.mlcontext.-ctor?view=ml-dotnet#Microsoft_ML_MLContext__ctor_System_Nullable_System_Int32__, свободный. – (дата обращения 13.05.2021)
- Microsoft Docs. Tutorial: Create a Windows service app. [Электронный ресурс] : портал. – Режим доступа: https://docs.microsoft.com/ru-ru/dotnet/framework/windows-services/walkthrough-creating-a-windows-service-application-in-the-component-designer, свободный. – (дата обращения 13.05.2021)
- Монополии цифровых гигантов: кто защитит потребителей? [Электронный ресурс] : портал. – Режим доступа: https://vc.ru/legal/169807-monopolii-cifrovyh-gigantov-kto-zashchitit-potrebiteley, свободный. – (дата обращения 14.05.2021)
- Реализации кэша в C# .NET. [Электронный ресурс] : портал. – Режим доступа: https://habr.com/ru/company/otus/blog/502974/, свободный. – (дата обращения 14.05.2021)
- Топ-10 сервисов для защиты от скликивания контекстной рекламы. [Электронный ресурс] : портал. – Режим доступа: https://vc.ru/services/128467-top-10-servisov-dlya-zashchity-ot-sklikivaniya-kontekstnoy-reklamy, свободный. – (дата обращения 14.05.2021)
- Машинное обучение: методы и способы. [Электронный ресурс] : портал. – Режим доступа: https://www.osp.ru/cio/2018/05/13054535, свободный. – (дата обращения 14.05.2021)
- Обзор алгоритмов кластеризации данных. [Электронный ресурс] : портал. – Режим доступа: https://habr.com/ru/post/101338/#:~:text=%D0%A1%D1%80%D0%B5%D0%B4%D0%B8%20%D0%B0%D0%BB%D0%B3%D0%BE%D1%80%D0%B8%D1%82%D0%BC%D0%BE%D0%B2%20%D0%B8%D0%B5%D1%80%D0%B0%D1%80%D1%85%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B9%20%D0%BA%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D0%B8%20%D0%B2%D1%8B%D0%B4%D0%B5%D0%BB%D1%8F%D1%8E%D1%82%D1%81%D1%8F,%D0%BD%D0%B0%20%D0%B2%D1%81%D0%B5%20%D0%B1%D0%BE%D0%BB%D0%B5%D0%B5%20%D0%BC%D0%B5%D0%BB%D0%BA%D0%B8%D0%B5%20%D0%BA%D0%BB%D0%B0%D1%81%D1%82%D0%B5%D1%80%D1%8B, свободный. – (дата обращения 15.05.2021)
- Иерархическая кластеризация. [Электронный ресурс] : портал. – Режим доступа: https://studme.org/139999/informatika/ierarhicheskaya_klasterizatsiya, свободный. – (дата обращения 15.05.2021)
- Докеризация веб-служб на R и Python. [Электронный ресурс] : портал. – Режим доступа: https://habr.com/ru/company/microsoft/blog/420159/, свободный. – (дата обращения 20.05.2021)
- Microsoft Docs. What Is Windows Communication Foundation. [Электронный ресурс] : портал. – Режим доступа: https://docs.microsoft.com/en-us/dotnet/framework/wcf/whats-wcf, свободный. – (дата обращения 21.05.2021)
- Различия SOAP и REST. [Электронный ресурс] : портал. – Режим доступа: https://habr.com/ru/post/483204/, свободный. – (дата обращения 22.05.2021)
- gRPC в качестве протокола межсервисного взаимодействия. Доклад Яндекса. [Электронный ресурс] : портал. – Режим доступа: https://habr.com/ru/company/yandex/blog/484068/, свободный. – (дата обращения 22.05.2020)
- What is ML.NET and how does it work? [Электронный ресурс] : портал. – Режим доступа: https://docs.microsoft.com/en-us/dotnet/machine-learning/how-does-mldotnet-work, свободный. – (дата обращения 25.05.2020)
- Вьюгин, В. В. Математические основы машинного обучения и прогнозирования : учебное пособие / В. В. Вьюгин. — Москва : МЦНМО, 2014. — 304 с. — ISBN 978-5-4439-2014-6. — Текст : электронный // Лань : электронно-библиотечная система. — URL: https://e.lanbook.com/book/56397 (дата обращения: 20.05.2021). — Режим доступа: для авториз. пользователей.
- Баюк, Д. А. Практическое применение методов кластеризации, классификации и аппроксимации на основе нейронных сетей : монография / Д. А. Баюк, О. А. Баюк, Д. В. Берзин. — Москва : Прометей, 2020. — 448 с. — ISBN 978-5-00172-079-9. — Текст : электронный // Лань : электронно-библиотечная система. — URL: https://e.lanbook.com/book/166775 (дата обращения: 21.05.2021). — Режим доступа: для авториз. пользователей.
[1] B2C (Business to Consumer) – это схема коммерческого взаимоотношения, где в качестве покупателя выступает конечный потребитель [2].
[2] Конверсия – отношение количества посетителей, совершивших целевое действие (например, оформление корзины покупок, заказ обратного звонка или заход в карточку товара) к общему количеству посетителей, измеряется в процентах. Семантически означает долю посетителей, совершивших покупку после перехода по рекламе [4].
[3] Детерминированный характер среды (deterministic environment) означает одинаковое поведение при одинаковых входных условиях.
[4] Логирование (составление и сохранение логов, отчетов о состоянии системы и протекающих в ней процессах) – унифицированное журналирование сообщений от системы.
[5] Информер – информативная панель, отображающая некоторую информацию (графики, списки, таблицы, интерактивные карты и т.д.).
[6] Контейнеризация – подход к разработке программного обеспечения, при котором приложение или служба, их зависимости и конфигурация (абстрактные файлы манифеста развертывания) упаковываются вместе в образ контейнера и исполняются в изолированном пространстве виртуальной ОС [15].
[7] Тест кейс, вариант тестирования – совокупность алгоритма тестирования и входных данных для него.
[8] Пайплайн – аналог конвейера в программировании, цепочка некоторых последовательно исполняемых действий, каждое из которых опирается на результат предыдущего действия, а первое действие использует входные данные.
[9] Стриминг (от англ. stream – поток) – потоковая передача данных.
[10] Таймаут (от англ. time out – передышка) – время задержки перед некоторым действием (например, время ожидания ответа на запрос).
[11] Обучение без учителя – способ машинного обучения, заключающийся в самостоятельном (без участия учителя) выявлении скрытых закономерностей и корреляций между переменными со стороны алгоритма.
[12] Рандомизация – получение случайных чисел или значений.
[13] DOM, Document Object Model (англ. объектная модель документа) – программное представление html документа, позволяющая обращаться к тегам как к переменным.