Кейс №6
В этом кейсе мы поделимся нашим опытом столкновения с специфичным типом мобильного бот-трафика и расскажем, как мы разработали и внедрили систему защиты, основанную на анализе поведенческих паттернов пользователя, с последующей демонстрацией адаптивной “мобильной капчи”.
Введение: Встречайте нежелательных гостей в мобильном вебе
Интернет стал неотъемлемой частью нашей жизни, а мобильные устройства — основным способом взаимодействия с ним. Компании активно развивают мобильные версии своих сайтов и приложений, стремясь предоставить пользователям максимально удобный сервис. Однако вместе с ростом мобильного трафика увеличивается и активность автоматизированных систем — ботов.
Боты могут быть как полезными (поисковые краулеры, мониторинговые сервисы), так и вредоносными. Последние могут парсить контент, рассылать спам, совершать мошеннические действия, проводить атаки на отказ в обслуживании (DDoS) на уровне приложения, или пытаться взломать учетные записи (credential stuffing). На десктопных версиях сайтов борьба с ботами ведется давно и успешно применяются различные методы, от простых IP-блэклистов до сложных систем анализа трафика.
Однако мобильный трафик имеет свои особенности. Паттерны поведения пользователей, способы взаимодействия с интерфейсом (тач, свайп вместо мыши и клавиатуры), вариативность устройств и сетевых условий создают как новые вызовы для детектирования ботов, так и новые возможности для их обнаружения. Традиционные методы, вроде классической визуальной капчи, могут быть неудобны на маленьких экранах или легко обходятся продвинутыми ботами, использующими сервисы распознавания.
В этой статье мы поделимся нашим опытом столкновения с специфичным типом мобильного бот-трафика и расскажем, как мы разработали и внедрили систему защиты, основанную на анализе поведенческих паттернов пользователя, с последующей демонстрацией адаптивной “мобильной капчи”.
Охота на ботов: Развертывание приманки
Наша история началась с того, что мы решили проактивно искать потенциальные векторы атак ботов на наш сайт. Одним из эффективных методов для этого является создание так называемой “медовой ловушки” (honeypot). Суть метода в том, чтобы создать элемент или страницу на сайте, которая абсолютно бесполезна или недоступна для обычного пользователя, но привлекательна для автоматизированных скриптов, сканирующих сайт на предмет уязвимостей, форм для спама или просто собирающих структуру сайта.
Мы выбрали подход с отдельной страницей. Был создан URL, который не ссылался ниоткуда на нашем сайте, не индексировался поисковыми системами (мы использовали robots.txt и мета-теги noindex), и не фигурировал в каких-либо рекламных или маркетинговых материалах. Попасть на эту страницу обычный пользователь мог только случайно, набрав URL вручную (что крайне маловероятно), либо перейдя по некорректной или устаревшей ссылке извне, чего мы минимизировали. Наполнение страницы было минимальным, не содержало интерактивных элементов или форм. По сути, это была страница-пустышка.
Идея была проста: любой значимый трафик на эту страницу, особенно повторяющийся или с подозрительными характеристиками, с высокой вероятностью является ботовым. Мы настроили логирование запросов к этой странице с максимальной детализацией: IP-адрес, User-Agent, реферер, время запроса, а также начали собирать базовую информацию о поведении на странице через аналитические системы (хотя, как оказалось, их детализации было недостаточно).
Враг обнаружен: Специфичный паттерн мобильных ботов
Спустя некоторое время мониторинга “медовой ловушки”, мы заметили интересную и тревожную тенденцию. На эту страницу стал приходить стабильный, хотя и не огромный по объему, трафик. Самое главное, что этот трафик имел ряд отличительных особенностей, позволяющих идентифицировать его как ботовый:
- Источник трафика: Почти весь трафик приходил с мобильных устройств. User-Agent строки указывали на популярные мобильные браузеры (Chrome Mobile, Safari Mobile), но часто содержали небольшие аномалии или были подозрительно однообразными.
- Необычная навигационная цепочка: Пользователи (точнее, что-то, что выдавало себя за них) не останавливались на странице-ловушке. Их поведение следовало четкому, повторяющемуся паттерну:
- Переход на страницу-ловушку (зачастую напрямую, без реферера, или с подозрительным реферером).
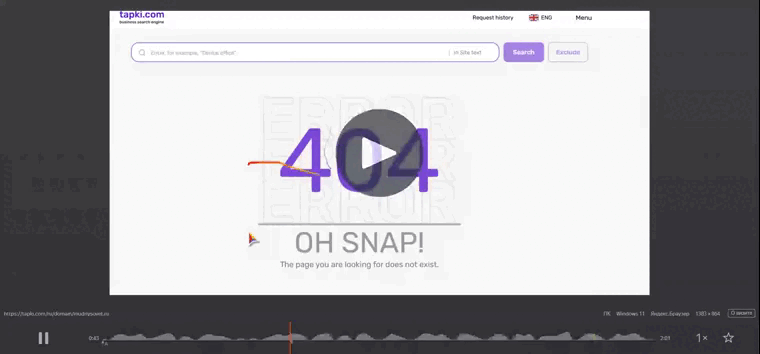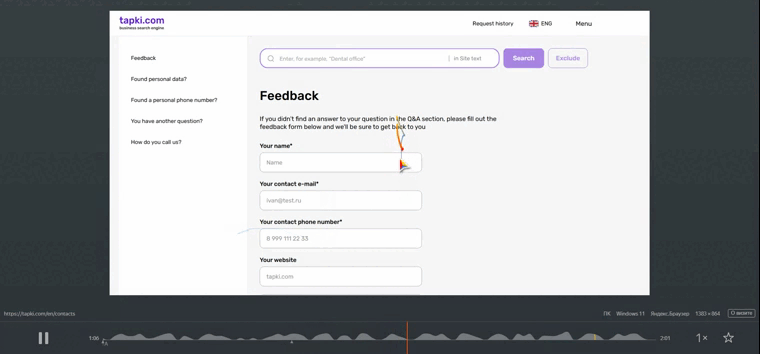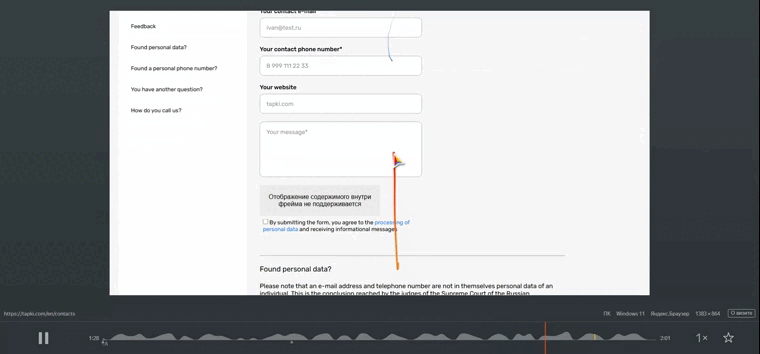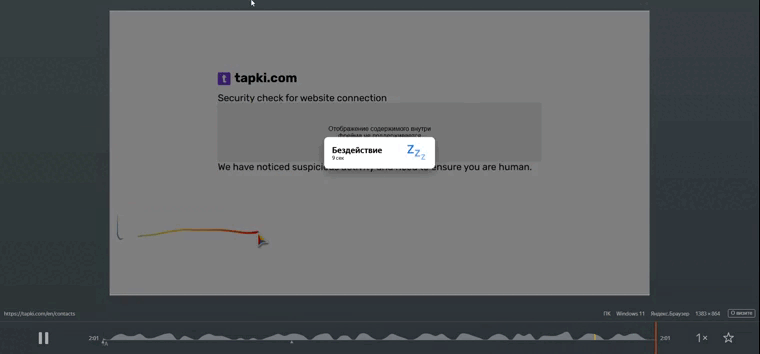
- Почти мгновенный переход на несуществующую страницу или страницу 404. Это могло быть результатом автоматического сканирования или попытки найти распространенные пути.
- Затем – переход на страницу “Контакты”. Это классическое место для ботов, ищущих формы обратной связи, email-адреса или номера телефонов для сбора базы или рассылки спама.
- Аномальное поведение на странице “Контакты”: Самой показательной деталью было поведение на странице “Контакты”. Вместо осмысленного взаимодействия (скроллинг для поиска информации, клики по ссылкам или полям формы), мы фиксировали хаотичные, безцельные движения. На мобильных устройствах это проявлялось как непрерывные, однообразные свайпы вверх-вниз (или иногда в стороны) без видимой логики, часто с одинаковой скоростью и амплитудой, в течение короткого промежутка времени, после чего сессия обрывалась или происходил переход на другую страницу.
Этот паттерн – переход по необычной цепочке страниц с последующим безцельным, механическим свайпингом на странице “Контакты” – был крайне нехарактерен для поведения живого пользователя. Человек, даже случайно попавший на сайт, обычно либо уходит сразу, либо пытается осмысленно найти нужную информацию, что выражается в более естественных движениях, с остановками, прицельными кликами, прокруткой до нужного места.
Мы поняли, что столкнулись с автоматизированными скриптами, которые, вероятно, сканируют сайты, ищут контактную информацию и пытаются имитировать базовое поведение пользователя, чтобы обойти простые системы детектирования, основанные только на анализе запросов. Однообразный свайпинг, видимо, был примитивной попыткой симулировать взаимодействие пользователя с мобильной страницей.
Внедрение поведенческого анализа на основе машинного обучения
Основываясь на выявленном паттерне, стало ясно, что для эффективной борьбы с этим типом ботов необходимо анализировать не только последовательность запросов, но и качество взаимодействия пользователя со страницей. Традиционные методы, такие как проверка IP по черным спискам или анализ User-Agent, оказались недостаточными, так как боты могли менять IP через прокси и использовать правдоподобные User-Agent строки.
Мы решили разработать систему детектирования ботов на основе поведенческого анализа с применением машинного обучения. Основная идея заключается в сборе детальной телеметрии о действиях пользователя на странице (движения мыши, клики, прокрутка, тач-события, свайпы), извлечении из этих данных характерных признаков (фич) и использовании модели машинного обучения для классификации пользователя как “человека” или “бота”.
Процесс реализации включал следующие этапы:
Сбор телеметрии на стороне клиента
Мы разработали lightweight JavaScript-библиотеку, которая внедрялась на страницы нашего сайта. Эта библиотека отслеживала и логировала различные пользовательские события, происходящие в окне браузера:
- События мыши:
mousemove,mousedown,mouseup,click,dblclick,contextmenu. Собирались координаты (clientX,clientY), время события, информация о нажатых кнопках. - События прокрутки (скроллинга):
scroll. Фиксировалась позиция прокрутки, скорость, направление. - Тач-события (критично для мобильных):
touchstart,touchmove,touchend,touchcancel. Собирались координаты касаний (поддержка multi-touch), время события, сила нажатия (если доступно через API), информация о тач-объектах. - События свайпа: Хотя свайп не является отдельным стандартным DOM-событием, мы детектировали его, анализируя последовательность
touchstart->touchmove->touchend. Фиксировались начальная и конечная точки, пройденное расстояние, длительность свайпа, средняя и максимальная скорость. - Другие события: Изменение размеров окна, фокус/блюр, ввод данных в поля форм (без самих данных).
Данные собирались в буфер на стороне клиента и отправлялись на наш сервер с определенной периодичностью (например, каждые несколько секунд или при достижении определенного объема данных) или при уходе пользователя со страницы. Передача данных осуществлялась по защищенному протоколу HTTPS. Важно было минимизировать влияние скрипта на производительность сайта и приватность пользователей (не собирать конфиденциальные данные).
Вот пример собираемых точек данных в упрощенном виде:
Таблица 1: Примеры собираемых данных поведенческой телеметрии
| Тип события | Свойства | Примечания |
|---|---|---|
mousemove | timestamp, x, y, delta_x, delta_y, velocity, acceleration | Движение мыши (для десктопа) |
click | timestamp, x, y, button, target_element_id | Клик мыши |
scroll | timestamp, scroll_x, scroll_y, scroll_delta, speed | Прокрутка страницы |
touchstart | timestamp, touches_count, [touch_x, touch_y] (для каждого касания) | Начало касания (для мобильных) |
touchmove | timestamp, touches_count, [touch_x, touch_y] (для каждого касания), delta_x, delta_y, velocity | Движение касания (для мобильных) |
touchend | timestamp, touches_count | Окончание касания (для мобильных) |
swipe | timestamp, start_x, start_y, end_x, end_y, distance, duration, avg_velocity, direction | Обнаруженный свайп (из последовательности touch) |
Обработка данных и инженерия признаков (Feature Engineering)
Собранные сырые события сами по себе не являются оптимальным входом для модели машинного обучения. На сервере происходила предобработка данных и извлечение из них характерных признаков (фич), описывающих паттерн поведения пользователя за определенный период времени (например, за сессию или за последние N секунд/событий).
Инженерия признаков – это ключевой этап. Мы стремились создать фичи, которые могли бы эффективно различать механическое, однообразное поведение бота и естественное, вариативное поведение человека. Для мобильного трафика особенный акцент делался на признаках, связанных с тач-событиями и свайпами.
Примеры разработанных признаков:
Таблица 2: Примеры признаков, используемых для классификации
| Категория признака | Признак | Описание | Ожидаемое различие (Человек vs Бот) |
|---|---|---|---|
| Движения (Общее) | Общая дистанция, пройденная курсором/касанием | Сумма длин сегментов движений. | Человек: обычно больше вариативности; Бот: может быть очень большим или очень маленьким в зависимости от задачи. |
| Средняя/Максимальная скорость движения | Характеристика динамики перемещений. | Человек: более естественные, вариативные скорости; Бот: часто постоянная или неестественно высокая/низкая. | |
| Плавность/Неровность пути движения | Измеряется по отклонению от прямой линии, количеству изгибов. | Человек: часто неровные, корректирующие движения; Бот: идеально прямые или повторяющиеся кривые. | |
| Количество остановок в движении | Паузы между перемещениями. | Человек: останавливается, чтобы прочитать или прицелиться; Бот: может не останавливаться или останавливаться через равные интервалы. | |
| Клики/Тапы | Количество кликов/тапов | Бот: может не кликать вовсе или кликать в определенные точки; Человек: кликает по интерактивным элементам. | |
| Распределение кликов/тапов по странице | Анализ зон страницы, куда приходятся нажатия. | Бот: кликает в одни и те же координаты или по сетке; Человек: кликает по кнопкам, ссылкам, полям. | |
| Время между кликами/тапами | Паузы между последовательными нажатиями. | Бот: может быть слишком быстрым или слишком медленным и однообразным. | |
Длительность удержания касания (touch_duration) | Как долго палец/стилус касается экрана. | Человек: вариативно, зависит от действия (короткий тап, долгое нажатие); Бот: часто фиксированное. | |
| Прокрутка | Скорость/Ускорение прокрутки | Человек: вариативно, зависит от контента и цели; Бот: часто постоянная. | |
| Амплитуда прокрутки | Расстояние, на которое была совершена прокрутка за одно действие. | Бот: может прокручивать на фиксированное количество пикселей; Человек: вариативно. | |
| Соотношение скроллинга и других действий | Как часто пользователь скроллит относительно кликов или ввода текста. | Бот: может только скроллить; Человек: комбинирует действия. | |
| Тач/Свайпы (Специфично для мобильных) | Количество свайпов | Бот: может совершать множество однообразных свайпов (как в нашем случае). | |
| Длина свайпов | Расстояние, пройденное за один свайп. | Бот: часто фиксированная или из узкого диапазона; Человек: вариативная. | |
| Длительность свайпов | Время от touchstart до touchend. | Бот: часто фиксированная; Человек: вариативная. | |
| Скорость/Ускорение свайпов | Бот: часто постоянная; Человек: вариативная, с начальным ускорением и замедлением в конце. | ||
| Угол/Направление свайпов | Направление движения (вертикаль, горизонталь, диагональ). | Бот: может быть строго вертикальным/горизонтальным; Человек: более широкий диапазон углов. | |
| Плавность траектории свайпа | Насколько прямым или изогнутым был путь между start/end точками. | Бот: часто идеально прямые; Человек: могут быть небольшие изгибы. | |
Количество касаний (touches_count) | Использование одного или нескольких пальцев. | Бот: обычно использует только одно “касание”; Человек: может использовать два и более (зум, жесты). | |
| Временные | Время, проведенное на странице | Бот: может быть очень коротким или слишком долгим без активности. | |
| Время до первого взаимодействия | Задержка перед первым кликом, скроллом или движением. | Бот: может быть мгновенным или слишком долгим; Человек: естественная задержка на загрузку и осмотр страницы. |
Каждый набор телеметрии за определенный интервал (например, 5-10 секунд активности) преобразовывался в вектор признаков.
Модель машинного обучения
Мы использовали классификационную модель машинного обучения для определения вероятности того, что текущее поведение принадлежит боту. В качестве модели хорошо зарекомендовали себя ансамблевые методы, такие как Random Forest или Gradient Boosting (например, XGBoost, LightGBM). Эти модели способны обрабатывать табличные данные (наши векторы признаков) и выявлять сложные нелинейные зависимости между признаками.
Процесс обучения модели:
- Сбор и разметка данных: Нам нужны были наборы данных с заведомо известным поведением человека и бота. Данные человека собирались с обычных сессий пользователей (при условии их согласия и соблюдения приватности), а данные ботов – в основном с нашей страницы-ловушки, где мы были уверены в их автоматизированной природе, а также с других страниц, где явно проявлялась ботовая активность (например, спам-заявки через формы). Разметка данных – критически важный и трудоемкий этап.
- Обучение: Модель обучалась на размеченном наборе данных, минимизируя ошибку классификации. Цель – научить модель отличать векторы признаков, характерные для человека, от векторов, характерных для бота.
- Валидация и тестирование: Оценка качества модели проводилась на независимых наборах данных для измерения точности, полноты (recall – обнаружение как можно большего числа ботов) и специфичности (specificity – минимизация ложных срабатываний на людях). Последнее особенно важно, так как ложное срабатывание на реальном пользователе приводит к негативному опыту.
После обучения модель была развернута на сервере в качестве сервиса, который мог принимать векторы признаков и возвращать вероятность принадлежности к классу “бот”.
Real-time Скоринг и Принятие Решения
Когда пользователь заходил на страницу, запускался наш клиентский скрипт сбора телеметрии. Собранные данные периодически отправлялись на сервер. Серверный компонент:
- Принимал сырые данные телеметрии.
- Формировал из них векторы признаков за определенный временной интервал или окно событий.
- Передавал вектор признаков обученной ML-модели.
- Получал на выходе “скор” или вероятность того, что текущее поведение является ботовым.
На основе этого скора принималось решение. Устанавливался пороговое значение: если скор превышал порог (например, 0.85), система классифицировала пользователя как потенциального бота. Это решение фиксировалось для данной сессии пользователя (например, в сессионных данных на сервере или в защищенном cookie на клиенте).
Важно: скоринг происходит поведенчески, то есть анализируется процесс взаимодействия. Это позволяет обнаружить даже ботов, которые успешно прошли первичные проверки (IP, User-Agent).
Реакция на обнаружение: Демонстрация адаптивной капчи
Как только система детектирования классифицировала пользователя как бота (на основе анализа его аномального поведенческого паттерна, в нашем случае — безцельных свайпов), мы должны были предпринять действие. Существует несколько вариантов:
- Полностью заблокировать доступ.
- Ограничить скорость запросов.
- Показать предупреждение.
- Показать CAPTCHA.
Мы выбрали последний вариант – демонстрацию CAPTCHA. Причины такого выбора:
- Подтверждение человечности: CAPTCHA является классическим способом предоставить пользователю возможность доказать, что он не бот, выполнив задание, сложное для автоматизации.
- Минимизация ложных блокировок: Если система вдруг ошиблась и классифицировала человека как бота (ложное срабатывание), CAPTCHA дает ему шанс продолжить работу с сайтом, пройдя проверку. Полная блокировка была бы слишком жесткой мерой.
- Адаптивность: Поскольку наша система обнаружила ботов по их мобильному поведению (свайпам), мы решили показать CAPTCHA, которая также хорошо адаптирована для мобильных устройств и, по возможности, связана с тач-взаимодействием. Классическая визуальная капча с текстом может быть неудобна на мобильном.
При обнаружении ботового поведения (например, после серии безцельных свайпов на странице “Контакты”, когда поведенческий скор достиг порогового значения), на следующей интерактивной странице или при попытке выполнить действие (например, отправить форму) пользователю вместо ожидаемого контента или результата показывался экран с нашей адаптивной мобильной капчей.
Здесь мы можем показать, как выглядит процесс демонстрации и взаимодействия с нашей мобильной капчей. Мы разработали несколько типов заданий, удобных для мобильных устройств, например, “Свайпните вправо, чтобы продолжить” или “Перетащите элемент в нужное место”.
Демонстрация появления капчи и начального состояния

Пояснение: На этом GIF показано, как при срабатывании системы детектирования бота (например, после обнаружения паттерна аномальных свайпов) пользователю вместо стандартного контента страницы появляется наложенный экран с заданием капчи.
Демонстрация появления капчи на десктопе
Важно, что проверка решения капчи также происходит на стороне сервера, чтобы избежать простого обхода путем эмуляции клиентского JavaScript.
Результаты, Вызовы и Будущее
Внедрение системы поведенческого анализа и адаптивной мобильной капчи дало ощутимые результаты:
- Значительное снижение ботового трафика: Мы отметили существенное снижение активности ботов, демонстрирующих выявленный ранее паттерн (посещение ловушки -> 404 -> Контакты -> свайпы). Большинство из них либо прекратили попытки после первых срабатываний капчи, либо были успешно остановлены.
- Уменьшение нагрузки: Снижение объема нежелательного трафика привело к уменьшению нагрузки на серверы, особенно на интерактивных страницах, которые боты пытались сканировать.
- Защита контактной информации и форм: Снизилось количество автоматических попыток сбора данных и спама через формы обратной связи.
- Низкий уровень ложных срабатываний: Благодаря тщательной настройке пороговых значений и continuous monitoring, количество ложных срабатываний на реальных пользователях оказалось на приемлемо низком уровне.
Однако разработка и поддержка такой системы сопряжена с рядом вызовов:
- Постоянная “гонка вооружений”: Бот-фермы и разработчики ботов постоянно совершенствуют свои методы, имитируя все более сложное и естественное поведение. Наша модель должна регулярно переобучаться на новых данных, чтобы оставаться актуальной.
- Производительность клиентского скрипта: Сбор детальной телеметрии не должен негативно сказываться на скорости загрузки и отзывчивости сайта, особенно на старых или менее мощных мобильных устройствах.
- Приватность данных: Крайне важно обеспечить безопасность и анонимность собираемых поведенческих данных, соблюдая все применимые нормы (например, GDPR).
- Ложные срабатывания (False Positives): Минимизация блокировок реальных пользователей – приоритетная задача. Это требует постоянного мониторинга и тонкой настройки модели и порогов.
- Evolving User Behavior: Поведение людей в интернете также меняется. Модель должна уметь адаптироваться к этим изменениям.
В планах на будущее мы рассматриваем:
- Интеграцию дополнительных источников данных (например, сведений о браузере, плагинах, настройках устройства – в рамках применимых ограничений приватности).
- Исследование более сложных ML-моделей или ансамблей моделей.
- Внедрение адаптивных ответных мер: вместо показа капчи, для менее подозрительных сессий можно использовать “мягкие” методы, например, задержку ответа сервера или показ искаженных данных.
- Расширение применения поведенческого анализа на другие чувствительные области сайта (формы регистрации, авторизации, оформления заказа).
Заключение
Борьба с ботовым трафиком, особенно в мобильном сегменте, требует использования продвинутых и многоуровневых подходов. Как показал наш опыт, обнаружение ботов, маскирующихся под реальных пользователей путем имитации базового взаимодействия, эффективно решается с помощью анализа поведенческих паттернов на основе машинного обучения.
Сбор детальной телеметрии о движениях, тапах и свайпах на мобильных устройствах, последующая инженерия признаков и применение классификационных ML-моделей позволяют выявить даже изощренные попытки автоматизации. Интеграция такого детектирования с адаптивной, удобной для мобильных устройств капчей является мощным инструментом защиты, который позволяет остановить ботов, не создавая излишних препятствий для добросовестных пользователей.
Разработка такой системы – это непрерывный процесс, требующий мониторинга, анализа новых угроз и постоянного совершенствования моделей и методов. Однако инвестиции в эти технологии оправдывают себя, обеспечивая безопасность, стабильность и качество работы нашего сайта для настоящих пользователей.
Если у вас есть вопросы по реализации или вы сталкиваетесь с похожими проблемами, обращайтесь – мы будем рады обсудить наш опыт и возможные решения.